

Il Problema: Raggiungere Rilevamenti di Minacce su Scala
In SOC Prime, abbiamo trascorso oltre un decennio a rendere l’ingegneria dei rilevamenti più facile per organizzazioni di ogni dimensione. Ogni anno, man mano che le minacce si moltiplicano e gli ambienti diventano più complessi, l’approccio tradizionale mette i Manager del SOC in una posizione impossibile — responsabili di una copertura che non possono raggiungere con gli strumenti e il team che hanno. DetectFlow offre un percorso per implementare rilevamenti su scala senza il sovraccarico di ingegneria. Ecco cosa risolve:
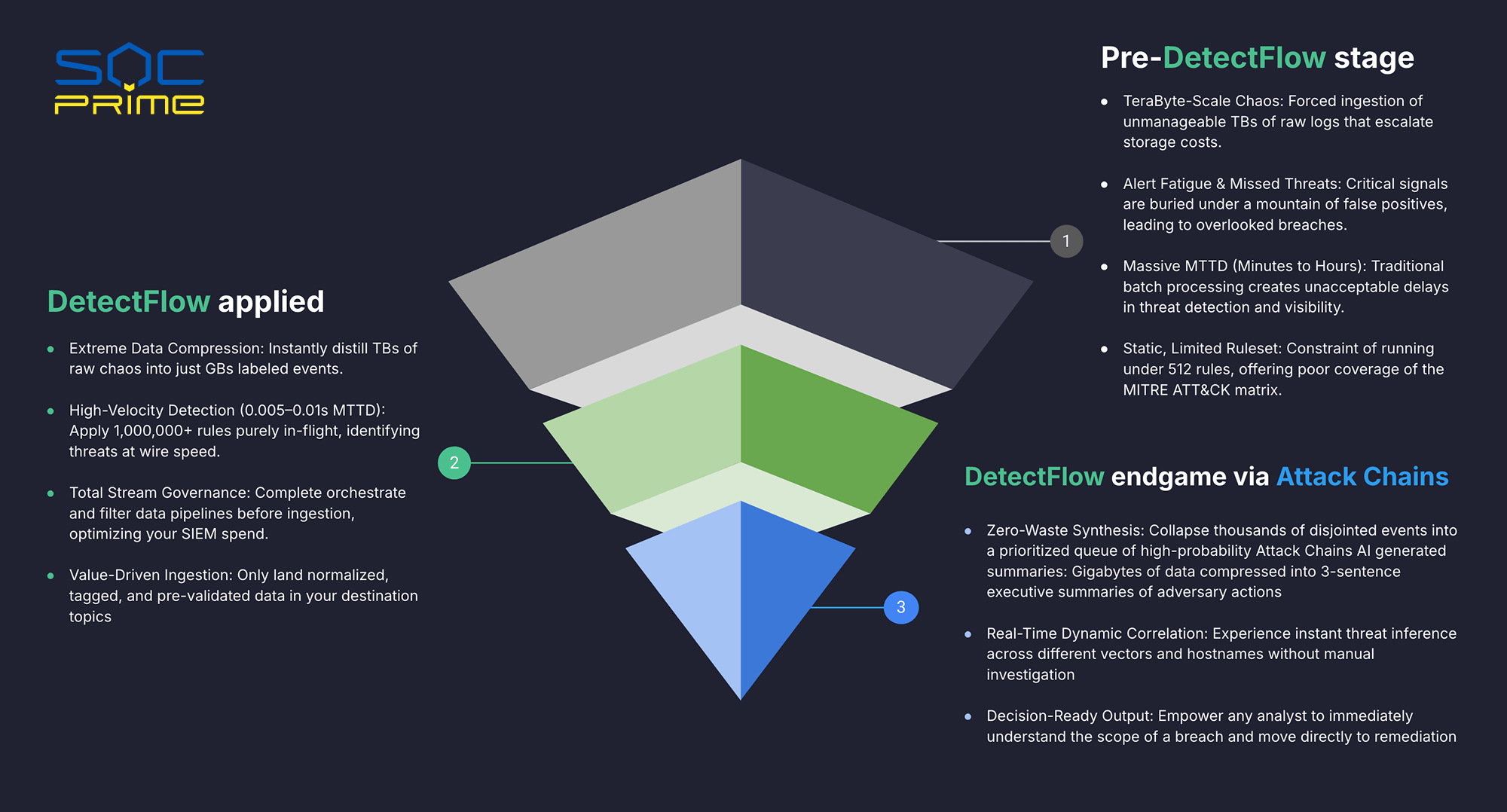
- Il tuo team è sommerso dal rumore, non trova minacce: I falsi positivi sopraffanno gli analisti e i veri segnali vengono persi. L’affaticamento da segnalazioni non è un problema di persone, ma un problema di sistemi
- La copertura di rilevamento ha limiti rigidi che non puoi risolvere con l’ingegneria: Operare con meno di 512 regole significa che il tuo team ha punti ciechi nella matrice MITRE ATT&CK che nessuna quantità di personale può colmare
- Quando il tuo team vede una minaccia, l’attaccante si è già mosso: L’elaborazione batch crea ritardi nei rilevamenti misurati in minuti o ore, trasformando un incidente gestibile in una violazione
- Il budget del tuo SIEM è consumato da dati di cui non avevi bisogno: L’ingestione forzata di log grezzi su scala terabyte aumenta i costi di archiviazione che sono impossibili da giustificare alla leadership
DetectFlow Applicato: Ridurre i Costi e Aumentare la Velocità
DetectFlow cambia fondamentalmente l’economia e la velocità del rilevamento delle minacce. Piuttosto che ingerire caos grezzo e ordinarlo successivamente, DetectFlow:
- comprimi terabyte di dati di log grezzi in gigabyte di eventi puliti ed etichettati (istantaneamente, prima che qualcosa tocchi il tuo SIEM).
- il rilevamento avviene in tempo reale, a velocità di trasmissione, applicando oltre 50.000 in tempo reale e riducendo il tempo medio di rilevamento a 0,005–0,01 secondi
- l’intera pipeline dei dati viene governata e filtrata prima dell’ingestione, quindi il tuo SIEM riceve solo eventi normalizzati, etichettati e pre-validati, risultando in un’ottimizzazione drammatica della spesa del tuo SIEM: stai pagando per archiviare e analizzare segnali, non rumore.
L’Obiettivo Finale: Catene di Attacco che Raccontano l’Intera Storia
Dove DetectFlow si distingue veramente è nel modo in cui porta alla luce ciò che conta. Invece di fornire agli analisti migliaia di avvisi scollegati e a basso contesto da correlare manualmente, DetectFlow:
- riduce quel rumore in una coda prioritaria di Catene di Attacco ad alta probabilità, complete di sommari esecutivi generati dall’IA che condensano gigabyte di attività avversarie in un breve chiaro.
- L’inferenza delle minacce avviene in tempo reale, correlando automaticamente le attività attraverso diversi vettori e nomi host senza richiedere alcuna indagine manuale.
- Il risultato non è un elenco di avvisi: è una decisione. Qualsiasi analista, a prescindere dal livello di esperienza, può comprendere immediatamente l’intero ambito di una violazione e passare direttamente alla rimedio.
Per saperne di più su DetectFlow vai alla nostra pagina di panoramica.
FAQ
Come riduce DetectFlow i costi del SIEM?
DetectFlow si posiziona a monte del tuo SIEM, elaborando flussi di eventi grezzi prima che vengano mai ingeriti. Comprime terabyte di dati di log grezzi a circa il 7% del volume originale, filtrando il rumore e passando solo eventi normalizzati ed etichettati alla minaccia nel tuo SIEM. Il risultato è che i costi di licenza e stoccaggio del tuo SIEM sono calcolati sul segnale, non sul volume grezzo. Per le organizzazioni che ingeriscono su scala, quel cambiamento da solo può fare la differenza tra un budget di sicurezza sostenibile e uno impossibile da difendere per un CFO.
Che cos’è MTTD e come lo migliora DetectFlow?
MTTD (Tempo Medio di Rilevamento) è la misura di quanto tempo impiega il tuo team a identificare una minaccia attiva dopo che è iniziata. Le architetture SIEM tradizionali si basano sull’elaborazione batch, il che significa che le query di rilevamento vengono eseguite con un ritardo, spesso 15 minuti o più dopo che un evento si verifica. DetectFlow applica le regole di rilevamento in tempo reale, direttamente sul flusso di dati dal vivo, riducendo l’MTTD tra 0,005 e 0,01 secondi. In termini pratici, questa è la differenza tra catturare un attaccante al primo movimento e scoprire una violazione dopo che il movimento laterale è già avvenuto.
Perché non possiamo semplicemente aggiungere più regole di rilevamento al nostro SIEM?
La maggior parte dei SIEM aziendali ha un limite operativo rigido su quante regole possono funzionare simultaneamente. Microsoft Sentinel, ad esempio, arriva a 512. Oltre il limite delle regole, ogni regola aggiuntiva aumenta il sovraccarico di query, rallenta il rilevamento e aumenta i costi. DetectFlow esegue il rilevamento al livello della pipeline usando Apache Flink, dove può applicare decine di migliaia di regole Sigma simultaneamente senza quei vincoli. Questo è ciò che consente al tuo team di chiudere le lacune di copertura MITRE ATT&CK che semplicemente non sono affrontabili all’interno di un’architettura SIEM.
DetectFlow sostituisce il nostro SIEM esistente?
No. DetectFlow si integra con il tuo SIEM esistente, non lo sostituisce. Si colloca nel livello della pipeline Kafka prima dell’ingestione, e il tuo SIEM riceve eventi più puliti, arricchiti e etichettati alla minaccia attraverso gli stessi connettori che utilizza già. I tuoi analisti continueranno a lavorare nelle dashboard familiari. Il cambiamento che notano è una qualità dei dati migliore, meno falsi positivi e indagini più rapide, non un nuovo strumento da apprendere.
Cosa significa “Catene di Attacco” e perché è importante per il mio team?
Catene di Attacco è come DetectFlow porta alla luce minacce correlate piuttosto che avvisi individuali. Invece di passare migliaia di eventi isolati ai tuoi analisti per indagini manuali, DetectFlow utilizza l’IA per comprimere attività correlate attraverso diversi vettori e nomi host in una singola coda prioritaria, con un sommario esecutivo di tre frasi su cosa sta facendo l’avversario. Per un manager SOC, questo significa che il tuo team sta triagiando una storia coerente su un attacco in corso, non un cumulo di segnali disconnessi che richiedono ore di indagine prima che il quadro diventi chiaro.


