

IntroduçãoO objetivo desta série é colocar os leitores no estado de espírito certo ao pensar sobre o SIEM e descrever como se preparar para o sucesso. Embora eu não seja um Cientista de Dados e não reclame ser, posso afirmar com confiança que esperar resultados em analytics de segurança sem primeiro ter “bons dados” para trabalhar é uma tolice. É por isso que sempre digo que “analytics de segurança é, antes de tudo, um problema de coleta de dados” e por isso a parte 1 do blog Fundamentos do SIEM é focada em como abordar a coleta de dados.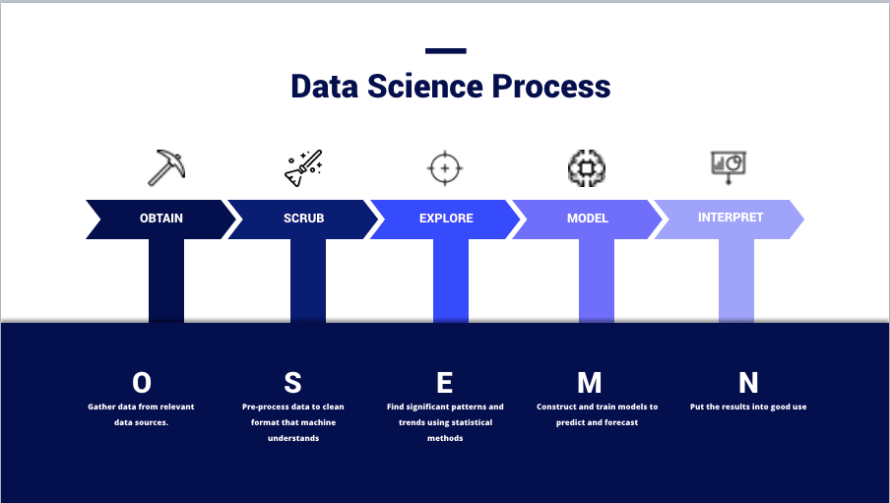
(Imagem de – https://thelead.io/data-science/5-steps-to-a-data-science-project-lifecycle)Esta imagem é uma visualização da estrutura OSEMN que muitos cientistas de dados utilizam ao planejar um projeto e, efetivamente, como as equipes transformam dados em informações. O propósito inteiro de usar um SIEM não é armazenar dados; mas sim, criar novas e úteis informações que podem ser usadas para melhorar a segurança.
Obter dados e limpá-los não é uma tarefa pequena. Na verdade, muitos Cientistas de Dados veem cada uma dessas fases como especialidades ou domínios distintos dentro da prática. Não é incomum encontrar indivíduos dedicados a uma única fase. Não apreciar isso é o motivo pelo qual muitas equipes falham em extrair valor de um SIEM; todo o hype de marketing faz com que seja fácil ignorar o quanto de esforço é exigido pelo usuário final em cada fase do processo e é algo que boas equipes irão iterar continuamente à medida que seu ambiente e o cenário de ameaças mudam.
Vamos gastar um momento falando sobre ETL, pois isso ajuda a descrever algumas das próximas seções.
- Extrair – Realmente conseguir que a fonte de dados emita logs em algum lugar em algum formato. Importante notar que esta é a única fase em que novos dados originais podem ser introduzidos a um conjunto de dados via configuração.
- E.G. Configurando a fonte de logs para relatar campos “X, Y, e Z” usando syslog remoto com um formato específico como pares chave-valor ou listas delimitadas por vírgula.
- Transformar – Modificar o formato e estrutura dos dados para melhor atender suas necessidades.
- E.G. Fazer parsing de um arquivo de log JSON em eventos de texto simples distintos com um arquivo de parsing, arquivo de mapeamento, script personalizado, etc.
- Carregar – Escrever os dados no banco de dados.
- E.G. Usar software que interpreta os eventos de texto simples e os envia para o banco de dados com instruções INSERT ou outras APIs públicas.
- Transformação Pós-Carregamento – Não é parte oficial do processo ETL; mas, um componente muito real do SIEM.
- E.G. Usando modelagem de dados, extrações de campo e aliases de campo.
ObterColetar dados é, em pequena escala, simples. No entanto, o SIEM não é de pequena escala, e descobrir como obter de forma confiável dados relevantes é crítico.Entrega ConfiávelPara esta seção, vamos nos concentrar na Extração e Carregamento.
- Extração
- Qual é a capacidade da minha fonte de dados em emitir?
- Quais campos e formatos podem ser usados?
- Quais métodos de transporte estão disponíveis?
- Este é um dispositivo do qual podemos “empurrar” dados para um ouvinte ou precisamos “puxá-los” via solicitações?
- Carregamento
- Como garantimos que os dados sejam entregues de maneira oportuna e confiável?
- O que acontece se um ouvinte falhar? Perderemos dados que são enviados durante uma falha?
- Como garantimos que as solicitações de pull sejam concluídas com sucesso?
No mundo do SIEM, muitas vezes é o caso de que a funcionalidade de “extração” é fornecida juntamente com a funcionalidade de “carregamento”; especialmente em casos onde software adicional (conectores, beats e agentes) são usados.
No entanto, há um espaço oculto entre esses dois onde os “brokers de eventos” se encaixam. Como os dados precisam ser entregues por uma rede, brokers de eventos são tecnologias como Kafka e Redis que podem lidar com balanceamento de carga, cache de eventos e enfileiramento. Às vezes, brokers de eventos podem ser usados para realmente escrever dados no armazenamento alvo; mas, também podem estar enviando saída para um “loader” tradicional em uma espécie de efeito cascata.
Não há realmente um jeito certo ou errado de construir seu pipeline em relação a esses fatores. A maior parte disso será ditada pela tecnologia SIEM que você usa. No entanto, é importante estar ciente de como essas coisas funcionam e preparado para enfrentar os desafios únicos de cada um através de soluções de engenharia.Escolhendo Fontes de LogsNão saia coletando dados de tudo só porque seu fornecedor de SIEM mandou; sempre tenha um plano e sempre tenha uma boa justificativa para coletar os dados que você escolheu. Neste ponto do processo, devemos nos perguntar as seguintes perguntas ao escolher dados relevantes: data:
- Compreendendo Informações
- Que atividade isso fornece visibilidade?
- Quão autoritária é essa fonte de dados?
- Essa fonte de dados fornece toda a visibilidade necessária ou são necessárias fontes adicionais?
- Esses dados podem ser usados para enriquecer outros conjuntos de dados?
- Determinando Relevância
- Como esses dados podem ajudar a atender a políticas, padrões ou objetivos definidos por políticas de segurança?
- Como esses dados podem melhorar a detecção de uma ameaça específica/ator de ameaça?
- Como esses dados podem ser usados para gerar novos insights sobre operações existentes?
- Medindo a Completeness
- O dispositivo já fornece os dados que precisamos no formato que queremos?
- Se não, ele pode ser configurado para isso?
- A fonte de dados está configurada para máxima verbosidade?
- Será necessário enriquecimento adicional para tornar essa fonte de dados útil?
- Analisando Estrutura
- Os dados estão em um formato legível por humanos?
- O que torna esses dados fáceis de ler e devemos adotar um formato semelhante para dados do mesmo tipo?
- Os dados estão em um formato legível por máquina?
- Qual é o tipo de arquivo dos dados e como uma máquina interpretará esse tipo de arquivo?
- Como os dados são apresentados?
- É um formato chave-valor, delimitado por vírgula ou algo mais?
- Temos boa documentação para esse formato?
- Os dados estão em um formato legível por humanos?
Problemas comuns encontrados na compreensão de suas informações surgem de documentação interna deficiente ou falta de especialização na própria fonte de logs e arquitetura de rede. Determinar relevância requer input de especialistas em segurança e proprietários de políticas. Em todos os casos, ter pessoal experiente e informado participando cedo é um benefício para toda a operação.LimpezaAgora vamos para o tópico mais interessante de limpeza de dados. A menos que você esteja familiarizado com isso, pode acabar se fazendo as seguintes perguntas:
- Olá, isso não deveria funcionar?
- Por que os dados não estão limpos, um engenheiro derramou café sobre eles?
- Higiene parece um problema pessoal – precisamos da opinião do RH nisso?
A realidade é que, por mais incríveis que sejam as máquinas, elas não são tão inteligentes (*ainda). O único conhecimento que elas têm é qualquer conhecimento que construímos nelas.Por exemplo, um humano pode olhar para o texto “Rob3rt” e entender que significa “Robert”. No entanto, uma máquina não sabe que o número “3” pode frequentemente representar a letra “e” na língua inglesa a menos que tenha sido pré-programada com tal conhecimento. Um exemplo mais real seria lidar com diferenças de formato como “3000” vs “3,000” vs “3K”. Como humanos, sabemos que todos significam a mesma coisa; mas, uma máquina se confunde com a “,” em “3,000” e não sabe interpretar “K” como “000”.Para o SIEM, isso é importante ao analisar dados entre fontes de logs.Exemplo 1 – Exposição A
| Dispositivo | Carimbo de Data/Hora | Endereço IP de Origem | Nome do Host de Origem | URL de Solicitação | Tráfego |
| Proxy da Web | 1579854825 | 192.168.0.1 | meuestacaodetrabalho.dominio.com | https://www.exemplo.com/index | Permitido |
| Dispositivo | Data | IP_Fonte | HST_Fonte | URL_Solicitação | Ação |
| NGFW | 2020-01-24T08:34:14+00:00 | ::FFF:192.168.0.59 | proxyweb | www.exemplo.com | Permitido |
Neste exemplo, você pode ver que o “Nome do Campo” e “Dados do Campo” são diferentes entre as fontes de log “Proxy da Web” e “NGFW”. Tentar construir casos de uso complexos com este formato é extremamente desafiador. Aqui está uma análise das diferenças problemáticas:
- Carimbo de Data/Hora: Proxy da Web está em formato Epoch (Unix) enquanto o NGFW está em formato Zulu (ISO 8601).
- IP de Fonte: Proxy da Web tem um endereço IPv4 enquanto NGFW tem um endereço IPv4-mapeado IPv6.
- Host de Origem: Proxy da Web usa um FQDN enquanto NGFW não usa.
- URL de Solicitação: Proxy usa a solicitação completa enquanto NGFW usa apenas o domínio.
- Tráfego/Ação: Proxy usa “permitido” e NGFW usa “permitido”.
Isso além dos nomes dos campos reais sendo diferentes. Em um banco de dados NoSQL com limpeza inadequada, isso significa que os termos de consulta usados para encontrar logs Alfa vão variar significativamente ao usar logs Beta.
Se eu ainda não enfatizei bastante esse ponto; vamos dar uma olhada em um caso de uso de detecção de exemplo:
- Caso de Uso: Detectar usuários com sucesso visitando sites conhecidos por serem maliciosos.
- Ambiente: O Proxy da Web está na frente do NGFW e é o primeiro dispositivo a ver o tráfego web.
- Advertências
- O Proxy da Web e o NGFW não têm listas de bloqueio idênticas. Uma solicitação web pode passar pelo Proxy da Web apenas para ser mais tarde negada pelo NGFW.
- As solicitações são encaminhadas do proxy para o NGFW de maneira não transparente. Ou seja, o endereço IP e o nome do host de origem são substituídos pelo endereço IP e nome do host do Proxy da Web e analisar apenas os logs do NGFW não mostrará a verdadeira origem da solicitação.
- Explicação:
- Neste exemplo, vamos supor que “Malicioso” é algum tipo de variável que compara o URL contra uma tabela de pesquisa de URLs maliciosos conhecidos armazenados no SIEM.
Nossa consulta seria assim:
- SELECT RQ_URL, SRC_IP, SRC_HST
WHERE Device == NGFW AND RQ_URL = Malicioso AND Action = Permitido - SELECT Request URL, Source IP, Source Host,
WHERE Device == Proxy da Web AND Request URL = Malicioso AND Traffic = Aceito
No entanto, dadas as advertências conhecidas, analisar os resultados de uma única consulta nos diria apenas o seguinte:
- NGFW – O status de bloqueio/negação final é conhecido. A verdadeira origem é desconhecida.
- Proxy da Web – O status de bloqueio/negação final é desconhecido. A verdadeira origem é conhecida.
Temos 2 peças de informação relacionadas que agora precisam ser unidas usando alguma lógica de carimbo de data/hora imprecisa que é na verdade apenas um “melhor palpite” de acordo com dois eventos que aconteceram em torno do mesmo período de tempo (uau).Como corrigir?Lembra-se destes do início do artigo?
- Transformar – Modificar o formato e estrutura dos dados para melhor atender suas necessidades.
- E.G. Fazer parsing de um arquivo de log JSON em eventos de texto simples distintos com um arquivo de parsing, arquivo de mapeamento, script personalizado, etc.
- Transformação Pós-Carregamento – Não é parte oficial do processo ETL; mas, um componente muito real do SIEM.
- E.G. Usando modelagem de dados, extrações de campo e aliases de campo.
Há muitas tecnologias e opções para eu explicar cada uma; mas, cobrirei algum vocabulário básico para entender o que são as técnicas de transformação:
- Configuração – Não é tecnicamente uma técnica de transformação; mas, geralmente a melhor maneira de abordar problemas de estrutura e formato de dados. Corrija o problema na fonte e pule tudo o mais.
- Parsing/Extrações de Campos – Uma operação de transformação (pré-ingestão) que utiliza expressões regulares (regex) para dividir uma string em caracteres (ou grupos de strings) com base em padrões. Lida bem com valores dinâmicos, desde que a estrutura geral seja estática; mas, pode ser proibitivo de desempenho com muitos curingas.
- Mapeamento – Uma operação de transformação que usa uma biblioteca de entradas e saídas estáticas. Pode ser usado para atribuir nomes e valores de campo. Não lida bem com entradas dinâmicas. No entanto, pode ser considerado mais eficiente do que parsing se a tabela de mapeamento for pequena.
- Aliasing de Campo – Semelhante ao mapeamento; mas, ocorre após o carregamento e não necessariamente altera os dados reais armazenados no SIEM.
- Modelos de Dados – Semelhantes ao aliasing de campo; ocorrem no momento da busca.
- Extrações de Campos – Semelhantes ao parsing e podem ocorrer antes ou depois da ingestão, dependendo da plataforma.
Vamos supor que criamos um monte de parsers para impor um esquema de campo comum, mapeamos os valores de campo para tráfego de “permitido” para “permitido”, configuramos nosso proxy web para encaminhar o IP de origem original e host, configuramos nosso NGFW para registrar nomes de hosts com seus FQDN e utilizamos funções para converter carimbos de data/horários e extrair endereços IPv4. Nossos dados agora se parecem com isso:Exemplo 1 – Exposição B
| Dispositivo | Hora | IPv4 de Origem | FQDN de Origem | URL da Solicitação | Tráfego |
| Proxy da Web | Janeiro 24, 2020 – 8:00 AM | 192.168.0.1 | meuestacaodetrabalho.dominio.com | https://www.exemplo.com/index | Permitido |
| Dispositivo | Hora | IPv4 de Origem | FQDN de Origem | URL da Solicitação | Tráfego |
| NGFW | Janeiro 24, 2020 – 8:01 AM | 192.168.0.1 | meuestacaodetrabalho.dominio.com | www.exemplo.com | Permitido |
Vamos também supor que o NGFW simplesmente não poderia nos dar o URL de solicitação completo porque esta informação é enriquecida na origem através de resolução DNS. Nossa “lógica pseudo-ideal” agora se parece com isso:
- SELECT IPv4 de Origem, FQDN de Origem, URL de Solicitação
WHERE Device == NGFW AND URL de Solicitação == Malicioso AND Tráfego == Permitido
Como configuramos nosso proxy para encaminhar as informações de origem, não precisamos mais depender de duas fontes de dados e lógica de carimbo de data/hora imprecisa para atribuir atividade a uma fonte específica. Se usarmos tabelas de pesquisa e alguma lógica avançada, também podemos descobrir facilmente quais são os URLs de solicitação completos associados ao tráfego usando as informações de origem com um formato comum como entradas.Exemplo 2Como um exemplo final, digamos que quiséssemos construir um relatório que nos mostre todo o tráfego malicioso permitido pela web em nossa rede; mas, apenas o tráfego do Segmento A passa pelo Proxy da Web e apenas o tráfego do Segmento B passa pelo NGFW.
Nossa consulta ficaria assim com uma má limpeza de dados:
- SELECT URL de Solicitação, RQ_URL, IP de Origem, IP_Fonte, Host de Origem, HST_Fonte
WHERE (URL de Solicitação = Malicioso E Tráfego = Aceito) OU (RQ_URL = Malicioso E Ação = Permitido)
E assim com boa limpeza de dados:
- SELECT URL de Solicitação, IPv4 de Origem, FQDN de Origem,
WHERE URL de Solicitação = Malicioso E Tráfego = Aceito
Os formatos comuns, o esquema e os tipos de valores nos proporcionam melhor desempenho de consulta e tornam a busca e a construção de conteúdos muito mais fáceis. Há um conjunto limitado de nomes de campos para lembrar e os valores dos campos, na maioria das vezes, parecerão idênticos, com exceção do URL de Solicitação para o NGFW.
Não posso enfatizar o suficiente o quanto isso é mais elegante e eficaz para análises rápidas e desenvolvimento de conteúdo.ConclusãoEste foi um jeito bastante extenso de dizer que o uso eficaz do SIEM requer (a) um plano, (b) forte colaboração multifuncional e (c) uma intenção clara de estruturar dados desde o início. Investir nessas fases iniciais prepara você para vitórias rápidas no futuro.
Se você gostou deste artigo, compartilhe-o com os outros e fique atento para “Fundamentos do SIEM (Parte 2): Usando Alertas, Painéis de Controle e Relatórios com Eficácia“. Se você realmente gostou deste artigo e deseja mostrar algum suporte, você pode conferir nosso Threat Detection Marketplace (conteúdo de SIEM gratuito), nosso ECS Premium Log Source Pack (escrubadores de dados para Elastic) e Manutenção Preditiva (resolve os problemas de coleta de dados discutidos aqui).


