

Introduction
The goal of this series is to put readers in the right mindset when thinking about SIEM and describe how to set themselves up for success. While I’m not a Data Scientist and don’t claim to be, I can confidently say that expecting results in security analytics without first having “good data” to work with is folly. This is why I always say that “security analytics is, first and foremost, a data collection problem” and why part 1 of the SIEM Fundamentals blog is focused on how to approach data collection.
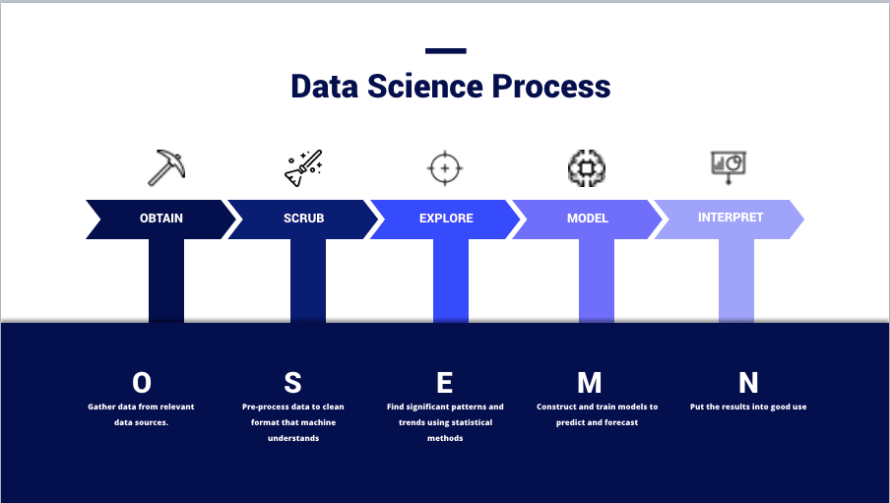
(Image from – https://thelead.io/data-science/5-steps-to-a-data-science-project-lifecycle)
This image is a visualization of the OSEMN framework that many data scientists utilize when planning a project and is effectively how teams turn data into information. The entire purpose of using a SIEM is not to store data; but, to create new and useful information that can be used to improve security.
Obtaining data and scrubbing it is no small feat. In fact, many Data Scientists view each of these phases as distinct specialties or domains within the practice. It’s not uncommon to find individuals dedicated to a single phase. Not appreciating this is why many teams fail to derive value from a SIEM; all of the marketing hype makes it easy to overlook just how much effort is required by the end-user at every phase of the process and is something that good teams will continually iterate through as their environment and the threat landscape changes.
Let’s spend a moment talking about ETL, as this helps describe some of the next sections.
- Extract – Actually getting the data source to output logs somewhere in some format. Important to note that this is the only phase in which new original data can be introduced to a data set via configuration.
- E.G. Configuring the log source to report fields “X, Y, and Z” using remote syslog with a specific format such as key-value pairs or comma delimited lists.
- Transform – Modifying the format and structure of the data to better suit your needs.
- E.G. Parsing a JSON log file into distinct plain-text events with a parsing file, mapping file, custom script, etc.
- Load – Writing the data to the database.
- E.G. Using software that interprets the plain-text events and sends them into the database with INSERT statements or other public APIs.
- Post-Load Transform – Not an official part of the ETL process; but, a very real component of SIEM.
- E.G. Using data modeling, field extractions, and field aliases.
Obtain
Collecting data is, at a small scale, simple. However, SIEM is not small scale, and figuring out how to reliably obtain data relevant data is critical.
Reliable Delivery
For this section, we’re going to focus on Extraction and Loading.
- Extraction
- What is my data source capable of outputting?
- What fields and formats can be used?
- What transport methods are available?
- Is this a device that we can “push” data from to a listener or do we have to “pull” it via requests?
- Loading
- How do we ensure that data is delivered in a timely and reliable manner?
- What happens if a listener goes down? Will we miss data that gets pushed during an outage?
- How do we ensure that pull requests complete successfully?
In the SIEM world, it’s often the case that “extraction” functionality is provided alongside “loading” functionality; especially in cases where additional software (connectors, beats, and agents) are used.
However, there is a hidden space between these two where “event brokers” fit in. Because data must be delivered over a network, event brokers are technologies like Kafka and Redis that can handle load balancing, event caching, and queuing. Sometimes event brokers can be used to actually write data into the target storage; but, may also be outputting to a traditional “loader” in a sort of daisy-chain fashion.
There’s not really a right or wrong way to build your pipeline in respect to these factors. Most of this will be dictated by the SIEM technology that you use. However, it is important to be aware of how these things work and prepared to address the unique challenges of each through engineering solutions.
Choosing Log Sources
Don’t go out collecting data from everything just because your SIEM vendor told you to; always have a plan and always have good justification for collecting the data you’ve chosen. At this point in the process, we should be asking ourselves the following questions when choosing relevant data:
- Understanding Information
- What activity does this provide visibility of?
- How authoritative is this data source?
- Does this data source provide all of the visibility needed or are there additional sources that are required?
- Can this data be used to enrich other data sets?
- Determining Relevance
- How can this data help meet policies, standards, or objectives set by security policy?
- How can this data enhance detection of a specific threat/threat actor?
- How can this data be used to generate novel insight into existing operations?
- Measuring Completeness
- Does the device already provide the data we need in the format we want?
- If not, can it be configured to?
- Is the data source configured for maximum verbosity?
- Will additional enrichment be required to make this data source useful?
- Analyzing Structure
- Is the data in a human readable format?
- What makes this data easy to read and should we adopt a similar format for data of the same type?
- Is the data in a machine readable format?
- What file-type is the data and how will a machine interpret this file type?
- How is the data presented?
- Is it a key-value format, comma delimited, or something else?
- Do we have good documentation for this format?
- Is the data in a human readable format?
Common problems encountered in understanding your information stem from poor internal documentation or expertise of the log source itself and network architecture. Determining relevance requires input from security specialists and policy owners. In all cases, having experienced and knowledgeable personnel participating early is a boon for the entire operation.
Scrub
Now onto the more interesting topic of data scrubbing. Unless you’re familiar with this, you may end up asking yourself the following questions:
- Hello, shouldn’t it just work?
- Why is the data not already clean, did an engineer spill coffee on it?
- Hygiene sounds like a personal issue – is this something we need HR to weigh in on?
The reality is that, as awesome as machines are, they aren’t that smart (*yet). The only knowledge they have is whatever knowledge we build them with.
For example, a human can look at the text “Rob3rt” and understand it to mean “Robert”. However, a machine doesn’t know that the number “3” can often represent the letter “e” in the english language unless it has been pre-programmed with such knowledge. A more real-world example would be in handling differences in format like “3000” vs “3,000” vs “3K”. As humans, we know that these all mean the same thing; but, a machine gets tripped up by the “,” in “3,000” and doesn’t know to interpret “K” as “000”.
For SIEM, this is important when analyzing data across log sources.
Example 1 – Exhibit A
| Device | Timestamp | Source IP Address | Source Host Name | Request URL | Traffic |
| Web Proxy | 1579854825 | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | Allowed |
| Device | Date | SRC_IP | SRC_HST | RQ_URL | Action |
| NGFW | 2020-01-24T08:34:14+00:00 | ::FFF:192.168.0.59 | webproxy | www.example.com | Permitted |
In this example, you can see that the “Field Name” and “Field Data” are different between log sources “Web Proxy” and “NGFW”. Attempting to build complex use cases with this format is extremely challenging. Here’s a breakdown of problematic differences:
- Timestamp: Web Proxy is in Epoch (Unix) format while NGFW is in Zulu (ISO 8601) format.
- Source IP: Web Proxy has an IPv4 address while NGFW has an IPv4-mapped IPv6 address.
- Source Host: Web Proxy uses a FQDN while NGFW does not.
- Request URL: Proxy uses the full request while NGFW only uses the domain.
- Traffic/Action: Proxy uses “allowed” and NGFW uses “permitted”.
This is in addition to the actual field names being different. In a NoSQL database with poor scrubbing, this means that the query terms used to find Alpha logs will vary significantly when using Beta logs.
If I haven’t already driven this point home hard enough yet; let’s take a look at a sample detection use case:
- Use Case: Detect users successfully visiting known malicious websites.
- Environment: The Web Proxy sits in front of the NGFW and is the first device to see web traffic.
- Caveats
- The Web Proxy and NGFW do not have identical block lists. A web request could make it through the Web Proxy only to be later denied by the NGFW.
- Requests are forwarded from the proxy to the NGFW in a non-transparent manner. I.E. The Source IP and Host Name are replaced with the Web Proxy’s IP and Host Name and analyzing only the NGFW logs will not show you the true source of the request.
- Explanation:
- In this example, let’s assume that “Malicious” is some type of variable which compares the URL against a lookup-table of known malicious URLs stored in the SIEM.
Our query would look like this:
- SELECT RQ_URL, SRC_IP, SRC_HST
WHERE Device == NGFW AND RQ_URL = Malicious AND Action = Permitted - SELECT Request URL, Source IP, Source Host,
WHERE Device == Web Proxy AND Request URL = Malicious AND Traffic = Accepted
However, given the known caveats, analyzing the results of a single query would only tell us the following:
- NGFW – The ultimate block/deny status is known. The true source is unknown.
- Web Proxy – The ultimate block/deny status is unknown. The true source is known.
We have 2 related pieces of information that now have to be joined using some fuzzy timestamp logic that is really just a “best guess” according to two events that happened around the same time period (yikes).
How2Fix?
Remember these from earlier in the article?
- Transform – Modifying the format and structure of the data to better suit your needs.
- E.G. Parsing a JSON log file into distinct plain-text events with a parsing file, mapping file, custom script, etc.
- Post-Load Transform – Not an official part of the ETL process; but, a very real component of SIEM.
- E.G. Using data modeling, field extractions, and field aliases.
There are entirely too many technologies and options for me to explain every one; but, I’ll cover some basic vocabulary for understanding what the transformation techniques are:
- Configuration – Not technically a transformation technique; but, typically the best way to address data structure and format problems. Fix the problem at the source and skip everything else.
- Parsing/Field Extractions – A transform operation (pre-ingestion) that utilizes regular expressions (regex) to slice a string into characters (or groups of strings) based on patterns. Handles dynamic values well provided that the overall structure is static; but, can be performance prohibitive with too many wildcards.
- Mapping – A transform operation that uses a library of static inputs and outputs. Can be used to assign field names and values. Does not handle dynamic input well. However, can be considered to be more efficient than parsing if the mapping table is small.
- Field Aliasing – Similar to mapping; but, occurs post-load and doesn’t necessarily change the actual stored in the SIEM.
- Data Models – Similar to field aliasing; occurs at search-time.
- Field Extractions – Similar to parsing and can occur pre or post ingestion depending on the platform.
Let’s say that we created a bunch of parsers to enforce a common field schema, mapped the field values for traffic from “allowed” to “permitted”, configured our web-proxy to forward the original source IP and host, configured our NGFW to log host names with their FQDN, and utilized functions to convert timestamps and extract IPv4 addresses. Our data now looks like this:
Example 1 – Exhibit B
| Device | Time | Source IPv4 | Source FQDN | Request URL | Traffic |
| Web Proxy | January 24, 2020 – 8:00 AM | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | Permitted |
| Device | Time | Source IPv4 | Source FQDN | Request URL | Traffic |
| NGFW | January 24, 2020 – 8:01 AM | 192.168.0.1 | myworkstation.domain.com | www.example.com | Permitted |
Let’s also assume that the NGFW simply couldn’t give us the full request URL because this information is enriched at the source through DNS resolution. Our “ideal pseudo-logic” now looks like this:
- SELECT Source IPv4, Source FQDN, Request URL
WHERE Device == NGFW AND Request URL == Malicious AND Traffic == Permitted
Because we’ve configured our proxy to forward the source information, we no longer have to rely on two data sources and fuzzy timestamp logic to attribute activity to a particular source. If we use lookup tables and some fancy logic we can also easily figure out what the full request URLs associated with the traffic are by using the commonly formatted source information as inputs.
Example 2
As one final example, let’s say we wanted to build a report which shows us all permitted malicious web traffic across our network; but, only Segment A’s traffic goes through the Web Proxy and only Segment B’s traffic goes through the NGFW.
Our query would look like this with bad data scrubbing:
- SELECT Request URL, RQ_URL, Source IP, SRC_IP, Source Host, SRC_HST
WHERE (Request URL = Malicious AND Traffic = Accepted) OR (RQ_URL = Malicious AND Action = Permitted)
And like this with good data scrubbing:
- SELECT Request URL, Source IPv4, Source FQDN,
WHERE Request URL = Malicious AND Traffic = Accepted
The common formats, schema, and value types gives us better query performance and makes searching and building content much easier. There’s a limited set of field names to remember and the field values will, for the most part, look identical with the exception of the Request URL for the NGFW.
I can’t stress enough how much more elegant and effective this is for quick analysis and content development.
Conclusion
This has been a very long-winded way of saying that effective SIEM usage requires (a) a plan, (b) strong cross-functional collaboration, and (c) a clear intent to structure data early on. Investing in these early phases sets yourself up for quick-wins down the road.
If you liked this article, please share it with others and keep an eye out for “SIEM Fundamentals (Part 2): Using Alerts, Dashboards, and Reports Effectively“. If you really liked this article and want to show some support, you can check out our Threat Detection Marketplace (free SIEM content), our ECS Premium Log Source Pack (data scrubbers for Elastic) and Predictive Maintenance (solves the data collection problems discussed here).


