보안 분석가를 위한 Elastic. 1부: 문자열 검색.


목차:
목적:
Elastic이 솔루션의 속도와 확장성을 통해 사이버 보안 분야에서 입지를 넓히면서 새로운 Elastic 사용자가 늘어날 것으로 예상됩니다. 이러한 사용자들은 다른 플랫폼과 SIEM에서의 경험으로 얻은 직관으로 Elastic에 접근할 것입니다. 종종 이러한 직관은 Elastic에서 몇 번의 검색 후에 직접적으로 도전받게 될 것입니다. 이 시리즈의 목적은 보안 분석가들이 Elastic의 독특성에 빠르게 적응하도록 돕는 것입니다. 이 게시물은 Elastic에서 문자열 데이터에 대한 적절한 검색을 구축하기 위한 가이드를 제공합니다.분석된 내용이 어떻게 텍스트 분석되지 않은 키워드 데이터 유형이 문자열 기반 데이터 검색에 어떻게 영향을 미치는지에 대한 오해는 오도된 결과로 이어질 수 있습니다. 이 게시물을 읽으면 분석 의도에 맞는 문자열 검색을 수행할 수 있도록 더 잘 준비될 것입니다.
개요:
- 시작하기 전에
- 어떤 데이터 유형을 사용하고 있습니까?
- 차이점 요약
- 차이점 1: 토큰화 및 용어
- 차이점 2: 대소문자 구분
- 차이점 3: 기호 매칭
시작하기 전에:
루씬
이 블로그 게시물은 루씬을 사용합니다. KQL은 정규 표현식을 아직 지원하지 않으며 우리는 그것이 필요합니다.
용어: 데이터 유형, 매핑 및 분석기:
Elastic의 인덱스에 데이터가 저장되는 방식에 대해 논의할 때 매핑, 데이터 유형 및 분석기라는 용어에 익숙해야 합니다.
- 데이터 유형 – 값이 저장/인덱싱되는 “형식”, “데이터 형식” 또는 “데이터 유형”입니다. 데이터 유형의 예로는 문자열, 불리언, 정수 및 IP가 있습니다. 문자열은 “텍스트” 또는 “키워드” 데이터 유형으로 저장/인덱싱됩니다.
- 매핑 – 이는 각 필드를 데이터 유형에 할당(매핑)하는 설정입니다. 매핑 가져오기 API를 통해 접근할 수 있습니다. “매핑 가져오기”를 하면 매핑된 데이터 유형의 필드가 반환됩니다.
- 분석기 – 문자열 데이터가 저장/인덱싱되기 전에 값을 저장 및 검색을 최적화하기 위해 사전 처리합니다. 분석기는 문자열 검색을 빠르게 하는 데 도움이 됩니다.
문자열이 저장되는 방식:
문자열에 대한 주요 데이터 유형은 두 가지입니다: 키워드 and 텍스트.
- 키워드 – 형식의 문자열은 원시 값으로 저장됩니다. 분석기는 적용되지 않습니다. 키워드 are stored as their raw value. No analyzer is applied.
- 텍스트 – 형식의 문자열은 분석됩니다. 기본 및 가장 일반적인 분석기는 텍스트 표준(텍스트) 분석기 입니다. 이 게시물에서는 “. In this post when we refer to the “텍스트” 데이터 유형을 언급할 때 표준 분석기를 사용한 텍스트 데이터 유형을 지칭합니다. 다른 분석기들도 있으며, 사용자 지정 분석기도 가능합니다.
어떤 데이터 유형을 사용하고 있습니까?
Elastic 인스턴스가 문자열에 대해 텍스트 and 키워드 데이터 유형을 모두 사용하는 경우가 매우 많습니다. 그러나 Elastic Common Schema(ECS) 와 Winlogbeat 는 주로 키워드 데이터 유형을 사용합니다.
ECS를 사용하더라도 관리자는 매핑을 사용자 지정할 수 있습니다! 필드가 어떻게 매핑되어 있는지 확실히 알기 위해서는 Elastic 인스턴스에 쿼리를 실행해야 합니다. 이를 위해 필드 매핑 가져오기 API 또는 매핑 가져오기 API를 사용할 수 있습니다. 정기적으로 검색하거나 내용을 구축한 필드에 대한 최신 매핑을 계속 파악하는 것이 좋은 방법입니다. 매핑은 변경될 수 있으며, 필드 이름은 그대로일 수 있습니다. 다시 말해 오늘의 키워드 필드는 내일 텍스트 필드가 될 수 있습니다.
키워드 and 텍스트 의 주목할 만한 차이점은 아래 섹션에 자세히 설명되어 있습니다. 또한, 검색 결과에 영향을 미치는 각 차이점은 자체 섹션에서 탐색됩니다.
차이점 요약
이 섹션을 보고 즉시 유형이 매치되는 이유를 이해할 것을 기대하지 않습니다. 각 차이점은 자체 섹션에서 확장하여 설명됩니다. 테이블의 각 예제는 또한 해당 동작을 설명하는 섹션 내에 테이블로 배치되어 있습니다.
차이점
다음 표는 데이터 유형의 주요 차이점에 대한 간략한 개요를 제공합니다.
| 차이점 | 표준(텍스트) | 키워드 |
| 토큰화됨 | 항목으로 나뉘어짐(토큰화됨), 원래 값 손실되지만 더 빠름 | 토큰화되지 않음, 원래 값 유지됨 |
| 대소문자 구분 | 대소문자 구분 없음, 대소문자를 구분하는 쿼리가 불가능 | 대소문자 구분 있음, 대소문자를 구분하지 않는 쿼리가 정규 표현식을 통해 가능 |
| 기호 | 일반적으로 비알파벳 문자는 저장되지 않음. 그러나 특정 상황에서는 비알파벳 문자를 유지함 | 비알파벳 문자 유지 / 기호 유지 |
행동의 차이점
다음 표는 유형이 검색 동작에 어떻게 영향을 미치는지에 대한 실제 예를 제공합니다.
| 예시 값 | 쿼리 | 텍스트 매치 | 키워드 매치 |
| Powershell.exe –encoded TvqQAAMA | process.args:encoded | Yes | No |
| Powershell.exe –encoded TvqQAAMA | process.args:/.*[Ee][Nn][Cc][Oo][Dd][Ee][Dd].*/ | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:*Powershell.exe*Tvq* | No | Yes |
| TVqQAAMA | process.args:*TVqQAAMA* | Yes | Yes |
| TVqQAAMA | process.args:*tvqqaama* | Yes | No |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
| CmD.ExE | process.name:cmd.exe | Yes | No |
| CmD.ExE | process.name:/[Cc][Mm][Dd].[Ee][Xx][Ee]/ | Yes | Yes |
| \*$* | process.args:*\\*$* | No | Yes |
| \C$WindowsSystem32 | process.args:*C$\* | Yes | Yes |
_
차이점 1: 분석기, 토큰화 및 용어
차이점
| 차이점 | 텍스트(표준 분석기) | 키워드 |
| 토큰화됨 | 용어로 나눔(토큰화됨) | 분석되지 않음, 토큰화되지 않음. 원래 값 유지됨. |
왜…?
The 텍스트 데이터 유형/표준 분석기는 문자열을 조각(토큰)으로 나누는 토큰화를 사용합니다. 이 토큰들은 단어 경계(예: 공백), 구두점 등을 기반으로 합니다.
표준 분석기로 다음 문자열을 토큰화한 예제:“searching for things with Elastic is straightforward”결과 용어는 다음과 같습니다:“searching” | “for” | “thing” | “with” | “elastic” | “is” | “straightforward”모든 것이 공백(단어 경계)에서 토큰화되었고, 전부 소문자로 변환되었으며 “s”가 “thing”에서 제거되었습니다.
토큰화는 포함 또는 와일드카드 없이 단일 용어 매칭을 가능하게 합니다. 예를 들어, “Elastic” the 텍스트 데이터 유형에 “searching for things with Elastic is straightforward”라는 문자열이 포함된 경우 매칭됩니다. 이는 다른 SIEM들이 와일드카드 또는 ‘contains’ 논리에 크게 의존하는 것과 다릅니다.
그러나 토큰화는 용어 사이의 와일드카드에서 중단됩니다. 예를 들어, 는 표준 분석된 문자열 “searching with Elastic is straightforward”와 일치하지 않습니다. 와일드카드 사이에 용어가 지원되지 않는다는 점에서 차이가 있습니다. 예를 들어, “*searching*Elastic*” 표준 분석된 문자열 “searching with Elastic is straightforward”와 일치하지 않습니다.참고: 구문론적 맞춤을 사용하는 것으로 처리할 수 있지만, 순서는 유지되지 않습니다. 예를 들면, “searching Elastic”~1은 “searching with Elastic”와 “Elastic with searching”에 일치할 것입니다.
보안에서는 종종 정확한 일치와 용어 사이의 와일드카드 사용이 필요합니다. 이것이 키워드 데이터 유형이 ECS에서 사실상의 데이터 유형이 된 이유 중 하나입니다. 속도에서 잃는 것을, 보다 정밀한 검색 수행 능력에서 얻을 수 있습니다.
예제들
| 예시 값 | 쿼리 | 텍스트 매치 | 키워드 매치 |
| Powershell.exe –encoded | process.args:”Powershell.exe –encoded” | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:/.*[Ee][Nn][Cc][Oo][Dd][Ee][Dd].*/ | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:encoded | Yes | No |
| Powershell.exe –encoded TvqQAAMA | process.args:*Powershell.exe*encoded* | No | Yes |
_
차이점 2: 대소문자 구분
차이점
| 차이점 | 텍스트(표준 분석기) | 키워드 |
| 대소문자 구분 | 전부 소문자로 저장되며, 따라서 대소문자를 구분하지 않습니다. 대소문자 구분 쿼리를 하는 것이 불가능합니다. | 대소문자를 구분합니다. 대소문자 구분하지 않는 쿼리는 정규식을 사용하여 만들 수 있습니다. |
왜…?
Elastic의 동작에서 대소문자 구분 문제는 보안 분석가에게 혼란을 유발하는 주요 원인 중 하나입니다. 이는 특히 키워드 데이터 유형(ECS 군중들 안녕하세요)에서 더욱 그렇습니다. 로그에 하나의 out-of-case 문자만 있어도 잘못 구축된 쿼리가 키워드 필드와 매칭되지 못할 수 있습니다. 공격자가 를(을) 포함한 데이터의 일부를 제어할 수 있을 때(윈도우 4688 및 4104 이벤트를 생각해보십시오) 대소문자를 구분하지 않으려면 정규식을 사용해야 합니다! 또한, Elastic은 한 문자만큼 대소문자가 맞지 않아서 문서를 겨우 놓쳐도 경고하지 않습니다. 따라서 보안 분석가에게는 결과가 누락되거나 의도한 것보다 더 많은 결과를 얻는 것이 혼란의 주요 원인이 됩니다.
의 기본적인 예제를 소개합니다. “PoWeRsHeLl”와 일치하는지 확인합니다. 한 문자의 대소문자 불일치로 인해 쿼리가 일치하지 않을 수 있습니다.
| 예시 값 | 쿼리 | 텍스트 매치 | 키워드 매치 |
| PoWeRsHeLl | process.args:PoWeRsHell | Yes | No |
| PoWeRsHeLl | process.args:PoWeRsHeLl | yes | yes |
| PoWeRsHeLl | process.args:/[Pp][Oo][Ww][Ee][Rr][Ss][Hh][Ee][Ll][Ll]/ | yes | 예(모든 경우와 일치) |
Kibana에서의 실 예제에서, 아래 이미지에서는 키워드 “process.args” 유형 필드가 “windows” 문자열에 대해 쿼리됩니다. 잘 모르는 분석가에게 이것은 충분할 것으로 보일 수 있습니다… 42개의 결과가 반환되었습니다. 그러나 만약 그들이 “windows”를 포함하는 모든 문서를 얻고자 했다면 그들은 잘못된 것입니다. 이 검색은 대소문자 구분이므로, “Windows”와 일치하지 않습니다.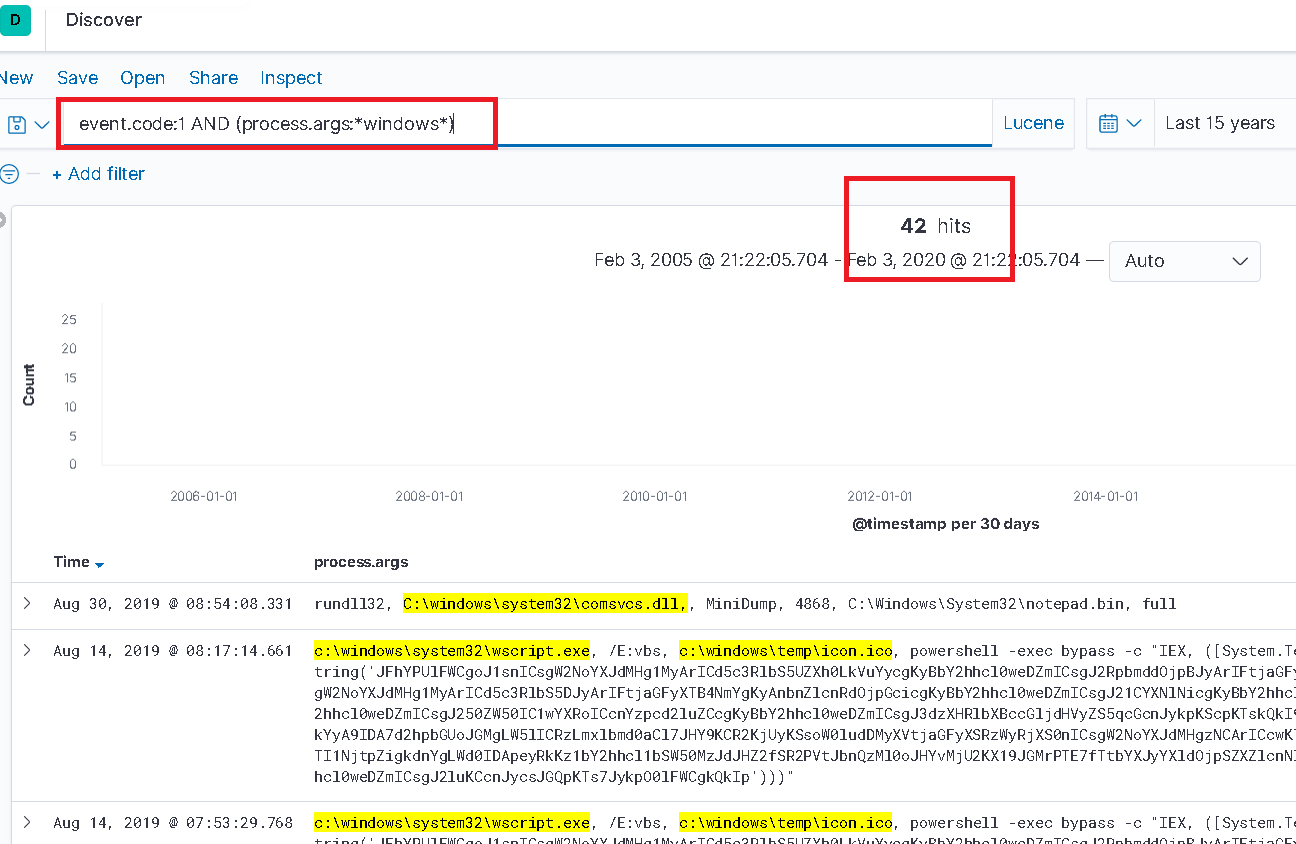
대소문자를 구분하는 검색의 제한된 결과
아래 쿼리에서, 정규 표현식을 사용하여 “windows”를 검색하면 그동안 “누락”된 567개의 결과를 반환합니다!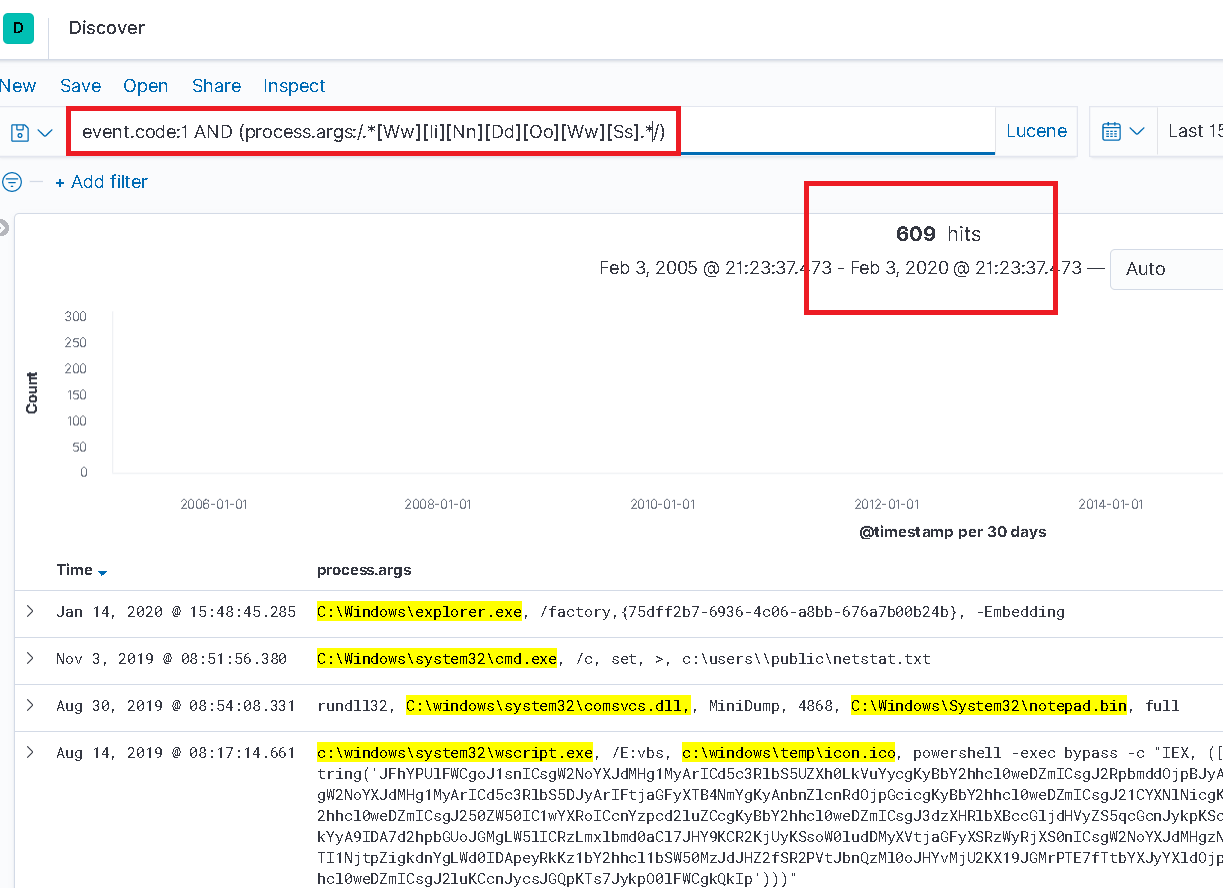
최대 결과
이제 키워드 유형을 사용하여 검색하고 정규 표현식을 사용하지 않을 경우 “powershell”의 다양한 형태를 일치하지 못할 것임이 분명합니다. 공격자가 제어하는 데이터를 대항하여 KQL(정규 표현식을 지원하지 않음)을 사용하여 매칭하지 않도록 주의하세요.참고: Base64처럼 Keyword 필드에서 대소문자를 민감하게 매칭하고자 하는 경우도 있을 수 있습니다.정규식 문자 집합을 사용하여 쿼리를 대소문자 구분 없이 만들 수 있습니다. 예제는 다음과 같습니다:
| encoded | /[Ee][Nn][Cc][Oo][Dd][Ee][Dd]/ |
| cmd.exe | /[Cc][Mm][Dd].[Ee][Xx][Ee]/ |
| C:windowssystem32* | /[Cc]:\[Ww][Ii][Nn][Dd][Oo][Ww][Ss]\[Ss][Yy][Ss][Tt][Ee][Mm]32\.*/ |
예제들
| 예시 값 | 쿼리 | 텍스트 매치 | 키워드 매치 |
| TVqQAAMA | process.args::*TVqQAAMA* | Yes | Yes |
| TVqQAAMA | process.args: *tvqqaama* | Yes | No |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
| CmD.ExE | process.name:cmd.exe | Yes | No |
| CmD.ExE | process.name:/[Cc][Mm][Dd].[Ee][Xx][Ee]/ | Yes | Yes |
_
차이점 3: 기호 매칭
차이점
| 차이점 | 텍스트(표준 분석기) | 키워드 |
| 기호 | 일반적으로 비알파벳 문자는 저장되지 않음. 그러나 특정 상황에서는 비알파벳 문자를 유지함 | 비알파벳 문자 유지 / 기호 유지 |
이유는 무엇인가요?
모든 기호는 데이터가 입력된 그대로 전체 필드가 유지되기 때문에 키워드 유형에 의해 유지됩니다(참고 참조). 그러나 표준 분석기에서는 일반적으로 기호가 유지되지 않습니다. 이는 분석기가 전체 단어 매칭을 위해 만들어졌고, 기호는 단어가 아니기 때문입니다. 다시 말해, 기호는 대체로 표준 분석기에서 저장되지 않습니다. 그래서, 기호에 매칭하려면 키워드 데이터 유형을 사용하는 것이 가장 좋으며, 만약 텍스트 필드만 있고 기호 그룹에 매칭해야 한다면 운이 좋지 않습니다. 그러나 표준 분석기에서도 기호가 유지되는 컨텍스트가 있습니다. 예를 들어, “cmd.exe”와 같은 용어에서는 마침표가 유지됩니다. 작가들은 표준 분석기에서 기호가 언제 유지되는지 이해하기 가장 쉬운 방법은 분석 API에서 테스트 데이터를 실행하는 것이라고 발견했습니다.
예제들
| 예시 값 | 쿼리 | 텍스트 매치 | 키워드 매치 |
| \*$* | process.args:*\\*$* | No | Yes |
| \C$WindowsSystem32 | process.args:*C$\* | Yes | Yes |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
_
결론
Elastic은 강력한 도구입니다. 그러나 또한 오도될 수 있습니다. 이 게시물을 통해 문자열 기반 데이터를 자신 있게 검색할 수 있는 약간의 지식과 힘을 드렸기를 바랍니다.
Elastic을 위한 콘텐츠 작성이 필요하다고 느끼신다면, SOC Prime의 위협 감지 마켓플레이스 는 우리가 제안하는 Elastic 구성과 함께 작동하는 감지 콘텐츠로 가득 차 있습니다.
미래 게시물
보안 분석가로서 Elastic을 사용함에 있어 기본 및 비기본을 탐구하는 추가 블로그 게시물을 기대해 주세요.
검색을 위한 추가 리소스:
이 시리즈는 구문에 대한 주제를 깊이 탐구하기보다는 분석가의 일반적인 통증점에 중점을 둡니다. Elastic은 자세한 문서를 제공합니다 루씬 구문에 대해. 또한, 고품질의 커뮤니티 치트 시트가 여러 개 있습니다: 특히 McAndre’s and Florian Roth 및 Thomas Patzke의.
메타:
발행 – 2020년 3월
마지막 업데이트 – 3월 12일
저자 – Adam Swan (@acalarch), Nate Guagenti (@neu5ron)의 도움
사용된 Elastic 버전: 7.5.2
예제에 사용된 로그: https://github.com/sbousseaden/EVTX-ATTACK-SAMPLES

