

イントロダクションこのシリーズの目的は、SIEMについて考える際に読者を正しいマインドセットに導き、成功への道筋を如何に整えるかを説明することです。私はデータサイエンティストではなく、その立場を主張するつもりもありませんが、「良いデータ」が用意されていない中でセキュリティ分析の結果を期待するのは愚かなことだと言い切れます。これが、「セキュリティ分析はまず第一にデータ収集の問題である」と私が常々言っている理由であり、「SIEM基礎」ブログの最初の部分がデータ収集へのアプローチに焦点を当てている理由です。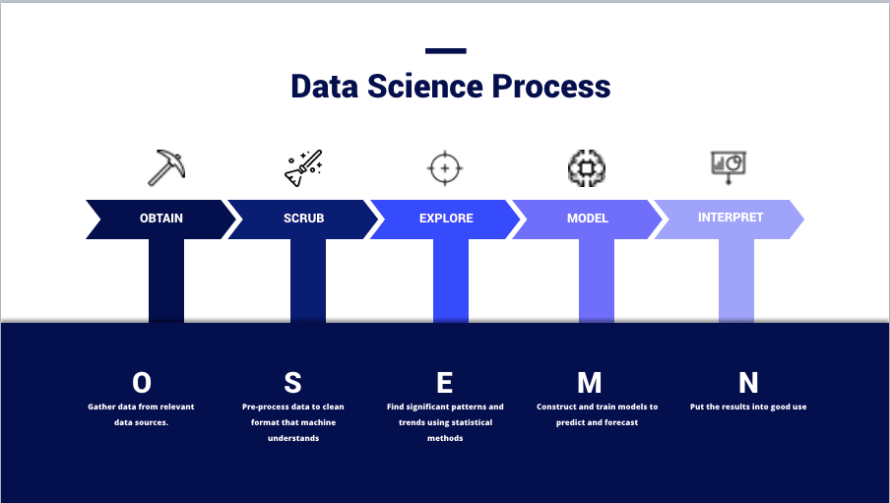
(画像出典 – https://thelead.io/data-science/5-steps-to-a-data-science-project-lifecycle)この画像は、多くのデータサイエンティストがプロジェクトを計画する際に利用するOSEMNフレームワークの視覚化であり、チームがデータを情報に変える方法を効果的に示しています。SIEMを使用する目的全体は、データを保存することではなく、セキュリティの向上に使用できる新しく有用な情報を作成することにあります。
データを取得し、クリーンにすることは容易ではありません。実際、多くのデータサイエンティストはこれらのフェーズをプラクティス内の別々の専門分野または領域と見なしています。特定のフェーズに専念する人々を見つけることは珍しくありません。これを理解していないことが、多くのチームがSIEMから価値を引き出すことに失敗する理由です。マーケティングの誇大広告に流され、エンドユーザーが各フェーズでどれほどの努力を必要とするかを見落としがちだからです。これは、良いチームが環境や脅威の状況が変化するにつれて常に反復することになるものです。
次のセクションを説明するのに役立つため、ETLについて少し話しましょう。
- 抽出 – データソースからログを何らかの形式でどこかに出力させること。重要なのは、この段階が、設定を通じて新しいオリジナルデータをデータセットに導入できる唯一のフェーズであることです。
- 例: 特定のフォーマット(例えばキーと値のペアやカンマ区切りリスト)を使用して、リモートsyslogでフィールド“X、Y、Z”を報告するようにログソースを設定する。
- 変換 – データの形式と構造を自身のニーズに合わせて修正すること。
- 例: パースファイル、マッピングファイル、カスタムスクリプトなどを使用して、JSONのログファイルを個別のプレーンテキストイベントに解析する。
- ロード – データをデータベースに書き込むこと。
- 例: プレーンテキストのイベントを解釈し、INSERT文やその他の公的APIでデータベースに送信するソフトウェアを使用する。
- ポストロード変換 – ETLプロセスの公式な部分ではありませんが、SIEMの非常に現実的なコンポーネントです。
- 例: データモデリング、フィールド抽出、フィールドエイリアスを使用する。
取得データを収集することは、小規模ならば単純です。しかし、SIEMは小規模ではなく、信頼性のある方法で関連データを入手する方法を考えることが重要です。信頼できる配信このセクションでは、抽出とロードに焦点を当てます。
- 抽出
- 私のデータソースは何を出力できるのか?
- どんなフィールドとフォーマットが使用できるか?
- どんなトランスポート方法が利用可能か?
- これは、監視者にデータを「プッシュ」できるデバイスなのか、それともリクエストを通じて「プル」しなければならないのか?
- ロード
- データがタイムリーかつ信頼性のある方法で配信されることをどうやって確実にするのか?
- リスナーが停止した場合、どうなりますか?障害中にプッシュされるデータを見逃す可能性はあるか?
- プルリクエストが成功するようにするためにはどうすればよいですか?
SIEMの世界では、「抽出」機能が「ロード」機能と共に提供されることが多々あります。特に追加のソフトウェア(コネクタ、ビート、エージェント)が使用される場合です。
しかし、これらの間には隠れた空間が存在し、そこに「イベントブローカー」が収まります。データはネットワーク上で配信されなければならないため、イベントブローカーは、負荷分散、イベントキャッシング、およびキューイングを処理できるKafkaやRedisのような技術です。時には、イベントブローカーがターゲットストレージに実際にデータを書き込むこともありますが、伝統的な「ローダー」に出力されることもあります。
これらの要素に関してパイプラインを構築する際に、正しい方法や間違った方法は特にありません。多くは使用するSIEMテクノロジーによって決まるでしょう。しかし、これらのものがどのように機能するかを理解し、それぞれの課題にエンジニアリングソリューションで対応する準備をしておくことが重要です。ログソースの選択SIEMベンダーが言ったからといって、すべてからデータを収集しに行くのではなく、常に計画を立て、選択したデータ収集の正当な理由を持つべきです。このプロセスのこの時点で、私たちは、適切なデータを選択する際に、次の質問を自問するべきです。
- 情報を理解する
- このアクティビティはどのような可視性を提供するか?
- このデータソースはどれだけ権威的か?
- このデータソースは必要な可視性をすべて提供しているのか、それとも追加のソースが必要か?
- このデータは他のデータセットの強化に使用できるか?
- 関連性を判断する
- このデータが政策、基準、またはセキュリティポリシーによって設定された目標や基準を達成するのにどのように役立つか?
- このデータが特定の脅威や脅威アクターの検出をどのように強化できるか?
- このデータが既存の運用に対して新しい洞察を生成するためにどのように使用されるか?
- 完全性を測る
- デバイスはすでに必要なデータを必要なフォーマットで提供しているのか?
- そうでない場合、設定が可能か?
- データソースは最大の冗長性のために設定されているか?
- このデータソースを有用にするためには追加の強化が必要か?
- 構造を分析する
- データは人間に読める形式か?
- このデータは何が読みやすいのか?同じタイプのデータに対して類似のフォーマットを採用すべきか?
- データは機械が読み取れる形式か?
- データのファイルタイプは何か?このファイルタイプを機械はどのように解釈するか?
- データはどのように提示されているか?
- それはキーと値の形式か、カンマ区切りか、それとも他の形式か?
- このフォーマットの良いドキュメントはあるか?
- データは人間に読める形式か?
自分の情報を理解する際に直面する一般的な問題は、ログソース自体やネットワークアーキテクチャの内部ドキュメントや専門知識が不十分であることに起因します。関連性を判断するには、セキュリティの専門家やポリシー管理者からのインプットが必要です。いずれの場合も、早期に参加する経験豊富で知識のある人材がいることで、全体の運用が非常に助かります。スクラブさて、より興味深いデータスクラビングのトピックに進みましょう。これに精通していない場合は、次のような疑問が浮かぶかもしれません:
- こんにちは、それはそのまま動作しないの?
- データがすでにクリーンでないのはなぜですか?エンジニアがコーヒーをこぼしたのですか?
- 衛生は個人的な問題のように聞こえますが、これは人事部が介入すべきことですか?
現実には、機械はすごいものの、そんなに賢くはありません (*まだ)。彼らが持つ唯一の知識は、我々が彼らに備えた知識だけです。例えば、人間は「Rob3rt」というテキストを見て、それが「Robert」を意味すると理解できます。しかし、機械は、数字「3」が英語でしばしば「e」を表すことを事前にプログラムされていなければ理解できません。より現実的な例として、フォーマットの違いを扱う際のことが挙げられます。「3000」 vs 「3,000」 vs 「3K」などです。人間はこれらすべてが同じ意味を持つことを知っていますが、機械は「3,000」の中の「,」に戸惑い、「K」を「000」と解釈することを知りません。SIEMにおいて、これはログソース間でデータを分析する際に重要です。例 1 – 展示 A
| デバイス | タイムスタンプ | ソースIPアドレス | ソースホスト名 | リクエストURL | トラフィック |
| ウェブプロキシ | 1579854825 | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | 許可済み |
| デバイス | 日付 | SRC_IP | SRC_HST | RQ_URL | アクション |
| NGFW | 2020-01-24T08:34:14+00:00 | ::FFF:192.168.0.59 | webproxy | www.example.com | 許可 |
この例では、「フィールド名」と「フィールドデータ」がログソース「ウェブプロキシ」と「NGFW」で異なることが分かります。このフォーマットで複雑なユースケースを構築するのは非常に困難です。問題のある違いの内訳は次のとおりです:
- タイムスタンプ: ウェブプロキシはエポック(Unix)フォーマットで、NGFWはZulu(ISO 8601)フォーマットです。
- ソース IP: ウェブプロキシはIPv4アドレスを、NGFWはIPv4マッピングされたIPv6アドレスを持っています。
- ソースホスト: ウェブプロキシは完全修飾ドメイン名(FQDN)を使用し、NGFWはそうではありません。
- リクエスト URL: プロキシはフルリクエストを使用し、NGFWはドメインのみを使用します。
- トラフィック/アクション: プロキシは「許可済み」を使用し、NGFWは「許可」を使用します。
これは、実際のフィールド名が異なることに加えてのことです。スクラビングが不十分なNoSQLデータベースでは、アルファログを検索するために使用するクエリ用語がベータログを 使用する際には大きく変わることになります。
もし私がこのポイントをまだ十分に強調していないのであれば、次はサンプル検出ユースケースを見てみましょう:
- ユースケース: ユーザーが成功裏に既知の悪意のあるウェブサイトにアクセスしていることを検出する。
- 環境: ウェブプロキシはNGFWの前にあり、ウェブトラフィックを最初に見るデバイスです。
- 注意点
- ウェブプロキシとNGFWは同一のブロックリストを持っていません。ウェブプロキシを通過できるウェブリクエストが、後でNGFWで拒否されることがあります。
- プロキシからNGFWに転送されるリクエストは非透過的方法で行われます。つまり、ソースIPとホスト名がウェブプロキシのIPとホスト名に置き換えられ、NGFWログのみを分析してもリクエストの本当のソースは分かりません。
- 説明:
- この例では、「悪意のある」がSIEMで既知の悪意のあるURLのルックアップテーブルと比較する変数であると仮定しましょう。
我々のクエリは次のようになります:
- SELECT RQ_URL, SRC_IP, SRC_HST
WHERE デバイス == NGFW AND RQ_URL = 悪意のある AND アクション = 許可 - SELECT リクエストURL, ソースIP, ソースホスト,
WHERE デバイス == ウェブプロキシ AND リクエストURL = 悪意のある AND トラフィック = 許可
しかし、既知の注意点を考慮に入れると、単一のクエリの結果を分析することで分かるのは次のことだけです:
- NGFW – 最終的なブロック/拒否のステータスは分かる。本当のソースは不明。
- ウェブプロキシ – 最終的なブロック/拒否のステータスは不明。本当のソースは分かる。
これで、関連する2つの情報を、2つのイベントが(恐らく)のんびりと発生した同じ時間帯に基づいて「ベストな推測」として結合する必要があります。解決方法は?この記事の初めに覚えておいてください。
- 変換 – データの形式と構造を自身のニーズに合わせて修正すること。
- 例: JSONログファイルを、パースファイル、マッピングファイル、カスタムスクリプトなどを使用して個別のプレーンテキストイベントに解析する。
- ポストロード変換 – ETLプロセスの公式な部分ではありませんが、SIEMの非常に現実的なコンポーネントです。
- 例: データモデリング、フィールド抽出、フィールドエイリアスを使用する。
私がすべての技術とオプションを説明するのにはあまりに多いので、変換テクニックを理解するための基本的な語彙を説明します。
- 設定 – 技術的には変換テクニックではありませんが、通常データ構造とフォーマットの問題に対応する最良の方法です。問題をソースで修正し、その他すべてをスキップします。
- パース/フィールド抽出 – 正規表現(regex)を利用して、文字列をパターンに基づいて文字(または文字群)にスライスする変換操作(取り込み前)です。全体の構造が静的であれば動的な値を適切に処理できますが、ワイルドカードが多すぎるとパフォーマンスを犠牲にする可能性があります。
- マッピング – 静的な入出力のライブラリを使用する変換操作です。フィールド名と値の割り当てに使用されます。動的な入力を適切に処理しませんが、マッピングテーブルが小さい場合は、パースよりも効率的と考えられます。
- フィールドエイリアス – マッピングに似ていますが、ロード後に発生し、SIEMに実際に格納されたものを必ずしも変更しません。
- データモデル – フィールドエイリアスに似ており、検索時間に発生します。
- フィールド抽出 – パースに似ており、プラットフォームに応じて取り込み前または後に発生する可能性があります。
例えば、共通のフィールドスキーマを適用する多数のパーサーを作成し、トラフィックのフィールド値を「許可済み」から「許可」にマッピングし、ウェブプロキシを元のソース情報を転送するように設定し、NGFWを完全修飾ドメイン名でホスト名を記録するように構成し、タイムスタンプを変換し、IPv4アドレスを抽出する関数を利用したとしましょう。我々のデータは次のようになりました。例 1 – 展示 B
| デバイス | 時間 | ソースIPv4 | ソースFQDN | リクエストURL | トラフィック |
| ウェブプロキシ | 2020年1月24日 – 午前8:00 | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | 許可 |
| デバイス | 時間 | ソースIPv4 | ソースFQDN | リクエストURL | トラフィック |
| NGFW | 2020年1月24日 – 午前8:01 | 192.168.0.1 | myworkstation.domain.com | www.example.com | 許可 |
例えば、NGFWがリクエストURL全体を提供できないのは、この情報がDNS解決を介してソースで強化されるためと仮定しましょう。私たちの「理想の擬似ロジック」は次のようになります。
- SELECT ソースIPv4, ソースFQDN, リクエストURL
WHERE デバイス == NGFW AND リクエストURL == 悪意のある AND トラフィック == 許可
私たちはプロキシをソース情報を転送するように構成したので、特定のソースに活動を帰属させるために、もはや2つのデータソースと曖昧なタイムスタンプロジックに依存する必要がありません。ルックアップテーブルといくつかの高度なロジックを使用することで、一般的なフォーマットのソース情報を入力として、トラフィックに関連付けられたフルリクエストURLを容易に把握できます。例 2最後にもう一つの例として、ネットワーク全体で許可された悪意のあるウェブトラフィックを示すレポートを作成したいとします。しかし、セグメントAのトラフィックだけがウェブプロキシを通過し、セグメントBのトラフィックだけがNGFWを通過します。
データスクラビングが不十分な状態でのクエリは次のようになります。
- SELECT リクエスト URL, RQ_URL, ソース IP, SRC_IP, ソースホスト, SRC_HST
WHERE (リクエスト URL = 悪意のある AND トラフィック = 許可) OR (RQ_URL = 悪意のある AND アクション = 許可)
そしてデータスクラビングが良好な状態では次のようになります。
- SELECT リクエストURL, ソースIPv4, ソースFQDN,
WHERE リクエストURL = 悪意のある AND トラフィック = 許可
共通のフォーマット、スキーマ、および値のタイプにより、クエリのパフォーマンスが向上し、検索とコンテンツの構築がはるかに簡単になります。覚えておくべきフィールド名のセットは限られており、NGFWのリクエストURLを除けば、フィールドの値は大部分同じに見えるでしょう。
迅速な分析やコンテンツ開発にどれほど優雅で効果的か強調してもしきれません。結論これは、効果的なSIEMの使用が(1)計画、(2)強力なクロスファンクショナルコラボレーション、(3)早期のデータ構造化の明確な意図を必要とするという非常に長い説明でした。これらの初期段階に投資することで、将来的に迅速な利益を得るための舞台を整えます。
もしこの記事が気に入ったら、他の人とも共有して、「SIEM基礎 (パート2): アラート、ダッシュボード、レポートを効果的に使用する」に注目してください。本当にこの記事が気に入った方で何かサポートを見せたい方は、私たちの脅威検出市場(無料のSIEMコンテンツ)、私たちのECSプレミアムログソースパック(Elastic用のデータスクラバー)と予知保全(ここで議論されたデータ収集の問題を解決します)をチェックアウトできます。


