

IntroduzioneL’obiettivo di questa serie è mettere i lettori nella giusta mentalità quando si pensa al SIEM e descrivere come prepararsi al successo. Anche se non sono un Data Scientist e non pretendo di esserlo, posso dire con sicurezza che aspettarsi risultati nelle analitiche di sicurezza senza prima avere ‘dati di qualità’ con cui lavorare è una follia. Ecco perché dico sempre che ‘l’analitica di sicurezza è, prima di tutto, un problema di raccolta dati’ e perché la parte 1 del blog Fondamenti del SIEM è focalizzata su come affrontare la raccolta dati.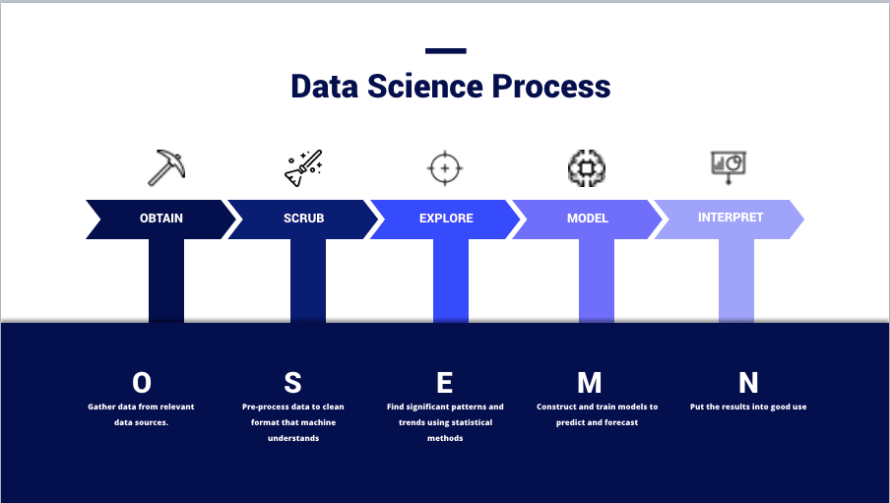
(Immagine da – https://thelead.io/data-science/5-steps-to-a-data-science-project-lifecycle)Questa immagine è una visualizzazione del framework OSEMN che molti data scientist utilizzano durante la pianificazione di un progetto ed è essenzialmente come i team trasformano i dati in informazioni. L’intero scopo dell’uso di un SIEM non è conservare i dati, ma creare nuove e utili informazioni che possano essere utilizzate per migliorare la sicurezza.
Ottenere e ripulire i dati non è un’impresa da poco. Infatti, molti data scientist vedono ognuna di queste fasi come specialità o domini distinti nella pratica. Non è raro trovare individui dedicati a una sola fase. Non comprendere appieno ciò è il motivo per cui molti team falliscono nel ricavare valore da un SIEM; tutto il clamore del marketing rende facile trascurare quanto sforzo sia richiesto dall’utente finale in ogni fase del processo ed è qualcosa che i buoni team itereranno continuamente man mano che il loro ambiente e il panorama delle minacce cambiano.
Prendiamoci un momento per parlare dell’ETL, poiché questo aiuta a descrivere alcune delle sezioni successive.
- Estrazione – Effettivamente ottenere la fonte dati per emettere log da qualche parte in un qualche formato. È importante notare che questa è l’unica fase in cui nuovi dati originali possono essere introdotti a un set di dati tramite configurazione.
- Ad esempio, configurare la fonte log per riportare i campi ‘X, Y, e Z’ utilizzando syslog remoto con un formato specifico come coppie chiave-valore o elenchi separati da virgole.
- Trasformare – Modificare il formato e la struttura dei dati per meglio adattarsi alle vostre esigenze.
- Ad esempio, analizzare un file di log JSON in distinti eventi in testo semplice con un file di parsing, file di mappatura, script personalizzato, ecc.
- Caricare – Scrivere i dati nel database.
- Ad esempio, utilizzare un software che interpreta gli eventi in testo semplice e li invia nel database con istruzioni INSERT o altre API pubbliche.
- Trasformazione Post-Carico – Non una parte ufficiale del processo ETL; ma una componente molto reale del SIEM.
- Ad esempio, utilizzare modelli di dati, estrazioni di campi e alias di campi.
OttenereRaccogliere dati, su piccola scala, è semplice. Tuttavia, il SIEM non è piccola scala, e capire come ottenere in modo affidabile i dati rilevanti è cruciale.Consegna AffidabilePer questa sezione, ci concentreremo sull’Estrazione e il Caricamento.
- Estrazione
- Cosa è in grado di emettere la mia fonte di dati?
- Quali campi e formati possono essere utilizzati?
- Quali metodi di trasporto sono disponibili?
- È questo un dispositivo da cui possiamo ‘spingere’ dati verso un listener o dobbiamo ‘tirarli’ tramite richieste?
- Caricamento
- Come garantiamo che i dati vengano consegnati in maniera tempestiva e affidabile?
- Cosa succede se un listener si arresta? Perderemo dati che vengono spinti durante un’interruzione?
- Come garantiamo che le richieste di pull vengano completate con successo?
Nel mondo del SIEM, spesso si ha che la funzionalità di ‘estrazione’ viene fornita accanto alla funzionalità di ‘caricamento’; specialmente nei casi in cui viene utilizzato software aggiuntivo (connettori, beats e agenti).
Tuttavia, esiste uno spazio nascosto tra questi due in cui si inseriscono i ‘broker eventi’. Poiché i dati devono essere consegnati su una rete, i broker di eventi sono tecnologie come Kafka e Redis che possono gestire il bilanciamento del carico, la memorizzazione nella cache e l’accodamento di eventi. A volte i broker di eventi possono essere utilizzati per scrivere effettivamente i dati nell’archiviazione di destinazione, ma possono anche emettere dati verso un ‘caricatore’ tradizionale in una sorta di concatenazione.
Non esiste realmente un modo giusto o sbagliato per costruire la tua pipeline rispetto a questi fattori. La maggior parte di questo sarà dettato dalla tecnologia SIEM che utilizzi. Tuttavia, è importante essere consapevoli di come funzionano queste cose e prepararsi ad affrontare le sfide uniche di ciascuna attraverso soluzioni ingegneristiche.Scegliere le Fonti di LogNon andate a raccogliere dati da tutto solo perché il vostro fornitore di SIEM ve l’ha detto; abbiate sempre un piano e sempre una buona giustificazione per raccogliere i dati che avete scelto. A questo punto del processo, dovremmo porci le seguenti domande quando scegliamo i dati rilevanti:
- Comprendere le Informazioni
- Quale attività fornisce visibilità?
- Quanto è autorevole questa fonte di dati?
- Questa fonte di dati fornisce tutta la visibilità necessaria o sono necessarie ulteriori fonti?
- Questo dato può essere utilizzato per arricchire altri set di dati?
- Determinare la Rilevanza
- Come può questo dato aiutare a soddisfare le politiche, gli standard o gli obiettivi stabiliti dalla politica di sicurezza?
- Come può questo dato migliorare il rilevamento di una specifica minaccia/attore della minaccia?
- Come possono essere usati questi dati per generare nuove intuizioni sulle operazioni esistenti?
- Misurare la Completezza
- Il dispositivo fornisce già i dati di cui abbiamo bisogno nel formato che vogliamo?
- Se no, può essere configurato per farlo?
- La sorgente dati è configurata per la massima verbosità?
- Sarà necessario un ulteriore arricchimento per rendere utile questa sorgente dati?
- Analizzare la Struttura
- I dati sono in un formato leggibile dall’uomo?
- Cosa rende questi dati facili da leggere e dovremmo adottare un formato simile per dati dello stesso tipo?
- I dati sono in un formato leggibile dalla macchina?
- In che tipo di file sono i dati e come interpreterà questo tipo di file una macchina?
- Come sono presentati i dati?
- È un formato chiave-valore, separato da virgole, o qualcosa d’altro?
- Abbiamo una buona documentazione per questo formato?
- I dati sono in un formato leggibile dall’uomo?
I problemi comuni riscontrati nel comprendere le tue informazioni derivano da una scarsa documentazione interna o esperienza della stessa fonte log e dell’architettura di rete. Determinare la rilevanza richiede l’input da parte di specialisti della sicurezza e proprietari delle politiche. In tutti i casi, avere personale esperto e competente che partecipa presto è un vantaggio per l’intera operazione.RipulireOra passiamo all’argomento più interessante della pulizia dei dati. A meno che tu non sia familiare con questo, potresti finire per farti le seguenti domande:
- Ciao, non dovrebbe semplicemente funzionare?
- Perché i dati non sono già puliti, un ingegnere ha versato caffè su di essi?
- L’igiene suona come un problema personale – è qualcosa su cui abbiamo bisogno dell’intervento delle Risorse Umane?
La realtà è che, per quanto le macchine siano fantastiche, non sono così intelligenti (ancora). L’unica conoscenza che hanno è quella che noi costruiamo in loro.Ad esempio, un umano può leggere il testo ‘Rob3rt’ e capire che significa ‘Robert’. Tuttavia, una macchina non sa che il numero ‘3’ può spesso rappresentare la lettera ‘e’ nella lingua inglese a meno che non sia stata programmata con tale conoscenza. Un esempio più reale potrebbe essere nella gestione delle differenze di formato come ‘3000’ vs ‘3,000’ vs ‘3K’. Come umani, sappiamo che questi significano tutti la stessa cosa; ma, una macchina si inceppa a causa della ‘,’ in ‘3,000’ e non sa interpretare ‘K’ come ‘000’.Per il SIEM, ciò è importante quando si analizzano i dati attraverso diversi log sources.Esempio 1 – Esempio A
| Dispositivo | Timestamp | Indirizzo IP sorgente | Nome host sorgente | URL di richiesta | Traffico |
| Web Proxy | 1579854825 | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | Consentito |
| Dispositivo | Data | SRC_IP | SRC_HST | RQ_URL | Azione |
| NGFW | 2020-01-24T08:34:14+00:00 | ::FFF:192.168.0.59 | webproxy | www.example.com | Permesso |
In questo esempio, puoi vedere che il ‘Nome Campo’ e i ‘Dati Campo’ sono diversi tra le fonti log ‘Web Proxy’ e ‘NGFW’. Tentare di costruire casi d’uso complessi con questo formato è estremamente impegnativo. Ecco un’analisi delle differenze problematiche:
- Timestamp: il proxy web è nel formato Epoch (Unix) mentre NGFW è nel formato Zulu (ISO 8601).
- IP sorgente: Web Proxy ha un indirizzo IPv4 mentre NGFW ha un indirizzo IPv4 mappato su IPv6.
- Host sorgente: Web Proxy utilizza un FQDN mentre NGFW no.
- Request URL: Proxy utilizza l’intera richiesta mentre NGFW utilizza solo il dominio.
- Traffico/Azione: Proxy usa ‘consentito’ e NGFW usa ‘permesso’.
Questo è in aggiunta al fatto che i nomi dei campi effettivi sono diversi. In un database NoSQL con scarsa pulizia, questo significa che i termini di ricerca utilizzati per trovare log Alpha varieranno notevolmente quando si usano i log Beta.
Se non ho già spinto abbastanza questo punto; diamo un’occhiata a un esempio di caso d’uso di rilevamento:
- Caso D’uso: Rilevare utenti con successo visitando siti web noti come malevoli.
- Ambiente: Il Web Proxy è posizionato davanti all’NGFW ed è il primo dispositivo a vedere il traffico web.
- Limitazioni
- Il Web Proxy e l’NGFW non hanno liste di blocco identiche. Una richiesta web potrebbe passare attraverso il Web Proxy solo per essere negata successivamente dall’NGFW.
- Le richieste vengono inoltrate dal proxy all’NGFW in modo non trasparente. I.E. L’IP di Origine e il Nome Host vengono sostituiti con l’IP e il Nome Host del Web Proxy e analizzando solo i registri NGFW non mostrerà la vera fonte della richiesta.
- Spiegazione:
- In questo esempio, supponiamo che ‘Malicious’ sia un qualche tipo di variabile che confronta l’URL con una tabella di ricerca di URL malevoli conosciuti archiviati nel SIEM.
La nostra query sarebbe simile a questa:
- SELEZIONA RQ_URL, SRC_IP, SRC_HST
DOVE Dispositivo == NGFW E RQ_URL = Malicious E Azione = Permesso - SELEZIONA Request URL, Source IP, Source Host,
DOVE Dispositivo == Web Proxy E Request URL = Malicious E Traffico = Accepted
Tuttavia, date le limitazioni conosciute, analizzando i risultati di una singola query avremmo solo le seguenti informazioni:
- NGFW – Lo stato finale di blocco/rifiuto è noto. La vera fonte è sconosciuta.
- Web Proxy – Lo stato finale di blocco/rifiuto è sconosciuto. La vera fonte è nota.
Abbiamo 2 pezzi di informazioni correlate che ora devono essere uniti utilizzando una logica temporale sfocata che è davvero solo un ‘miglior indovino’ secondo due eventi che sono accaduti nello stesso periodo di tempo (aiuto).Come Risolverlo?Ricordi questi dal precedente dell’articolo?
- Trasformare – Modificare il formato e la struttura dei dati per meglio adattarsi alle vostre esigenze.
- Ad esempio, analizzare un file di log JSON in eventi distinti in testo semplice con un file di parsing, file di mappatura, script personalizzato, ecc.
- Trasformazione Post-Carico – Non una parte ufficiale del processo ETL; ma una componente molto reale del SIEM.
- Ad esempio, utilizzare modelli di dati, estrazioni di campi e alias di campi.
Ci sono troppe tecnologie e opzioni per me per spiegare ciascuna di esse; ma coprirò un po’ di vocabolario di base per comprendere quali sono le tecniche di trasformazione:
- Configurazione – Non tecnicamente una tecnica di trasformazione; ma, in genere il modo migliore per affrontare problemi di struttura e formato dati. Risolvi il problema alla fonte e salta tutto il resto.
- Parsing/Estratti dei Campi – Un’operazione di trasformazione (pre-ingestione) che utilizza espressioni regolari (regex) per suddividere una stringa in caratteri (o gruppi di stringhe) basati su modelli. Gestisce bene i valori dinamici se la struttura generale è statica; ma può essere proibitiva in termini di prestazioni con troppi caratteri jolly.
- Mappatura – Un’operazione di trasformazione che utilizza una libreria di input e output statici. Può essere usata per assegnare nomi e valori ai campi. Non gestisce bene l’input dinamico. Tuttavia, può essere considerata più efficiente rispetto al parsing se la tabella di mappatura è piccola.
- Alias dei Campi – Simile alla mappatura; ma avviene post-caricamento e non necessariamente cambia i dati effettivamente archiviati nel SIEM.
- Modelli di Dati – Simile all’alias dei campi; avviene al momento della ricerca.
- Estratti dei Campi – Simile al parsing e può avvenire pre o post-ingestione a seconda della piattaforma.
Supponiamo di aver creato un mucchio di parser per imporre uno schema di campi comune, mappato i valori dei campi per il traffico da ‘consentito’ a ‘permesso’, configurato il nostro web-proxy per inoltrare le informazioni sorgente originali, configurato il nostro NGFW per registrare nomi host con il loro FQDN, e utilizzato funzioni per convertire timestamp ed estrarre indirizzi IPv4. I nostri dati ora appaiono così:Esempio 1 – Esempio B
| Dispositivo | Ora | IPv4 Sorgente | FQDN Sorgente | URL di Richiesta | Traffico |
| Web Proxy | 24 gennaio 2020 – 8:00 | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | Permesso |
| Dispositivo | Ora | IPv4 Sorgente | FQDN Sorgente | URL di Richiesta | Traffico |
| NGFW | 24 gennaio 2020 – 8:01 | 192.168.0.1 | myworkstation.domain.com | www.example.com | Permesso |
Supponiamo anche che il NGFW semplicemente non potesse fornirci l’intero URL di richiesta perché queste informazioni sono arricchite all’origine tramite risoluzione DNS. La nostra ‘logica pseudo-ideale’ ora assomiglia a questa:
- SELEZIONA IPv4 Sorgente, FQDN Sorgente, URL di Richiesta
DOVE Dispositivo == NGFW E URL di Richiesta == Malicious E Traffico == Permesso
Poiché abbiamo configurato il nostro proxy per inoltrare le informazioni di origine, non dobbiamo più fare affidamento su due fonti di dati e una logica temporale sfocata per attribuire l’attività a una particolare fonte. Se utilizziamo tabelle di ricerca e una logica sofisticata possiamo anche facilmente scoprire quali sono gli URL di richiesta completi associati al traffico utilizzando le informazioni di origine comunemente formattate come input.Esempio 2Come esempio finale, supponiamo di voler costruire un rapporto che ci mostra tutto il traffico web malevolo permesso attraverso la nostra rete; ma, solo il traffico del Segmento A passa attraverso il Web Proxy e solo il traffico del Segmento B passa attraverso l’NGFW.
La nostra query sarebbe simile a questa con una scarsa pulizia dei dati:
- SELEZIONA Request URL, RQ_URL, Source IP, SRC_IP, Source Host, SRC_HST
DOVE (Request URL = Malicious AND Traffic = Accepted) OR (RQ_URL = Malicious AND Action = Permitted)
E così con una buona pulizia dei dati:
- SELEZIONA Request URL, Source IPv4, Source FQDN,
DOVE Request URL = Malicious AND Traffic = Accepted
I formati comuni, schemi e tipi di valori ci offrono migliori prestazioni di query e rendono la ricerca e la costruzione di contenuti molto più semplici. C’è un set limitato di nomi di campi da ricordare e i valori dei campi, per la maggior parte, appariranno identici con l’eccezione dell’URL di richiesta per l’NGFW.
Non posso sottolineare abbastanza quanto sia più elegante ed efficace questo per analisi rapide e sviluppo di contenuti.ConclusioneQuesto è stato un modo molto prolisso per dire che l’uso efficace del SIEM richiede (a) un piano, (b) una forte collaborazione cross-funzionale, e (c) un intento chiaro nel strutturare i dati presto. Investire in queste fasi iniziali ci prepara a rapidi successi in seguito.
Se avete apprezzato questo articolo, per favore condividetelo con altri e state attenti a ”Fondamenti di SIEM (Parte 2): Utilizzare Allerte, Dashboard e Report in modo Efficace‘. Se vi è piaciuto davvero questo articolo e volete mostrare il vostro supporto, potete dare un’occhiata al nostro Mercato della Rilevazione delle Minacce (contenuti SIEM gratuiti), il nostro Pacchetto Fonte di Log Premium ECS (depuratori di dati per Elastic) e Manutenzione Predittiva (risolve i problemi di raccolta dati discussi qui).


