

IntroductionL’objectif de cette série est de mettre les lecteurs dans le bon état d’esprit lorsqu’ils réfléchissent à SIEM et de décrire comment se préparer au succès. Bien que je ne sois pas un Data Scientist et ne prétende pas l’être, je peux affirmer avec confiance qu’attendre des résultats en analytics de sécurité sans d’abord avoir de »bonnes données » avec lesquelles travailler est une folie. C’est pourquoi je dis toujours que les analytics de sécurité sont, avant tout, un problème de collecte de données et pourquoi la partie 1 du blog sur les Fondamentaux SIEM se concentre sur la façon d’aborder la collecte de données.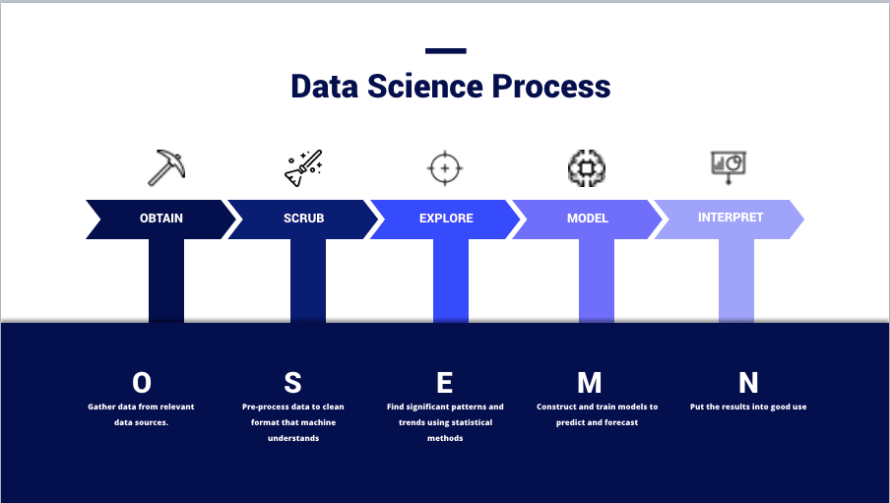
(Image de – https://thelead.io/data-science/5-steps-to-a-data-science-project-lifecycle)Cette image est une visualisation du cadre OSEMN que de nombreux data scientists utilisent lors de la planification d’un projet, et c’est ainsi que les équipes transforment les données en informations. Le but entier de l’utilisation d’un SIEM n’est pas de stocker des données ; mais, de créer de nouvelles informations utiles pouvant être utilisées pour améliorer la sécurité.
Obtenir des données et les nettoyer n’est pas un mince exploit. En fait, de nombreux Data Scientists considèrent chacune de ces phases comme des spécialités ou des domaines distincts au sein de la pratique. Il n’est pas rare de trouver des individus dédiés à une seule phase. Ne pas comprendre cela est la raison pour laquelle de nombreuses équipes échouent à tirer parti d’un SIEM ; tout le battage publicitaire marketing rend facile de négliger l’effort requis par l’utilisateur final à chaque phase du processus, et c’est quelque chose que les bonnes équipes itéreront en permanence à mesure que leur environnement et le paysage des menaces évoluent.
Prenons un moment pour parler de ETL, car cela aide à décrire certaines des sections suivantes.
- Extraire – Faire en sorte que la source de données émette des journaux quelque part dans un certain format. Il est important de noter que c’est la seule phase où de nouvelles données originales peuvent être introduites dans un ensemble de données via la configuration.
- Par exemple, configurer la source de journaux pour signaler les champs »X, Y et Z » en utilisant syslog distant avec un format spécifique tel que des paires clé-valeur ou des listes délimitées par des virgules.
- Transformer – Modifier le format et la structure des données pour mieux répondre à vos besoins.
- Par exemple, analyser un fichier journal JSON en événements distincts en texte brut avec un fichier d’analyse, un fichier de mappage, un script personnalisé, etc.
- Charger – Écrire les données dans la base de données.
- Par exemple, utiliser un logiciel qui interprète les événements en texte brut et les envoie dans la base de données avec des instructions INSERT ou d’autres API publiques.
- Transformation post-charge – Pas une partie officielle du processus ETL; mais, un composant très réel du SIEM.
- Par exemple, utiliser le modélisation des données, les extractions de champs et les alias de champs.
ObtenirCollecter des données est, à petite échelle, simple. Cependant, le SIEM n’est pas à petite échelle, et comprendre comment obtenir de manière fiable des données pertinentes est crucial.Diffusion fiablePour cette section, nous allons nous concentrer sur l’extraction et le chargement.
- Extraction
- De quoi ma source de données est-elle capable de produire ?
- Quels champs et formats peuvent être utilisés ?
- Quels modes de transport sont disponibles ?
- S’agit-il d’un appareil à partir duquel nous pouvons »pousser » des données vers un écouteur ou devons-nous les »extraire » via des requêtes ?
- Chargement
- Comment s’assurer que les données sont livrées de manière rapide et fiable ?
- Que se passe-t-il si un écouteur tombe en panne ? Allons-nous rater des données qui sont envoyées lors d’une coupure ?
- Comment garantir que les demandes d’extraction se terminent avec succès ?
Dans le monde du SIEM, il arrive souvent que la »fonctionnalité » d’extraction soit fournie avec la »fonctionnalité » de chargement; surtout dans les cas où des logiciels supplémentaires (connecteurs, beats et agents) sont utilisés.
Cependant, il y a un espace caché entre les deux où les compensateurs d’événements s’insèrent. Parce que les données doivent être livrées sur un réseau, les compensateurs d’événements sont des technologies telles que Kafka et Redis qui peuvent gérer la répartition de la charge, la mise en cache des événements et la mise en file d’attente. Parfois, les compensateurs d’événements peuvent être utilisés pour réellement écrire des données dans le stockage cible ; mais, peuvent également envoyer à un »chargeur » traditionnel de manière chaînée.
Il n’y a pas vraiment de bonne ou de mauvaise façon de construire votre pipeline en fonction de ces facteurs. La plupart de cela sera dicté par la technologie SIEM que vous utilisez. Cependant, il est important d’être conscient de ces fonctionnements et prêt à relever les défis uniques de chacun grâce à des solutions d’ingénierie.Choisir les sources de journauxNe collectez pas des données de tout simplement parce que votre fournisseur de SIEM vous l’a dit ; ayez toujours un plan et justifiez bien la collecte des données que vous avez choisies. À ce stade du processus, nous devrions nous poser les questions suivantes lorsqu’on choisit des données pertinentes :
- Comprendre les informations
- Quelle activité cela offre-t-il de visibilité ?
- Quelle est l’autorité de cette source de données ?
- Cette source de données fournit-elle toute la visibilité nécessaire ou d’autres sources sont-elles requises ?
- Ces données peuvent-elles être utilisées pour enrichir d’autres ensembles de données ?
- Déterminer la pertinence
- Comment ces données peuvent-elles aider à satisfaire les politiques, normes ou objectifs définis par la politique de sécurité ?
- Comment ces données peuvent-elles améliorer la détection d’une menace/acteur spécifique ?
- Comment ces données peuvent-elles être utilisées pour générer une nouvelle perspective sur les opérations existantes ?
- Mesurer la complétude
- Le périphérique fournit-il déjà les données dont nous avons besoin dans le format que nous souhaitons ?
- Sinon, peut-il être configuré pour ?
- La source de données est-elle configurée pour une verbosité maximale ?
- Un enrichissement supplémentaire sera-t-il requis pour rendre cette source de données utile ?
- Analyser la structure
- Les données sont-elles dans un format lisible par un humain ?
- Qu’est-ce qui rend ces données faciles à lire et devrions-nous adopter un format similaire pour les données du même type ?
- Les données sont-elles dans un format lisible par une machine ?
- Quel type de fichier sont les données et comment une machine interprétera-t-elle ce type de fichier ?
- Comment les données sont-elles présentées ?
- Est-ce un format clé-valeur, délimité par des virgules, ou autre chose ?
- Avons-nous une bonne documentation pour ce format ?
- Les données sont-elles dans un format lisible par un humain ?
Les problèmes communs rencontrés dans la compréhension de vos informations proviennent d’une mauvaise documentation interne ou de l’expertise de la source de journal elle-même et de l’architecture réseau. Déterminer la pertinence nécessite l’entrée des spécialistes de la sécurité et des responsables de la politique. Dans tous les cas, avoir du personnel expérimenté et compétent participant dès le début est un avantage pour toute l’opération.NettoyerPassons maintenant à un sujet plus intéressant, le nettoyage des données. À moins d’être familier avec cela, vous pourriez vous poser les questions suivantes :
- Bonjour, cela ne devrait-il pas simplement fonctionner ?
- Pourquoi les données ne sont-elles pas déjà propres, un ingénieur a-t-il renversé du café dessus ?
- L’hygiène semble être une affaire personnelle – est-ce quelque chose sur lequel nous devons impliquer les RH ?
La réalité est que, aussi formidables que soient les machines, elles ne sont pas si intelligentes (*encore). Les seules connaissances qu’elles possèdent sont celles avec lesquelles nous les construisons.Par exemple, un humain peut regarder le texte « Rob3rt » et le comprendre comme « Robert ». Cependant, une machine ne sait pas que le nombre « 3 » peut souvent représenter la lettre « e » dans la langue anglaise, sauf si elle est préprogrammée avec une telle connaissance. Un exemple plus concret serait dans la gestion des différences de format telles que « 3000 » vs « 3,000 » vs « 3K ». En tant qu’humains, nous savons que tout cela signifie la même chose ; mais, une machine est perturbée par la « , » dans « 3,000 » et ne sait pas interpréter « K » comme « 000 ».Pour le SIEM, c’est important lors de l’analyse des données provenant de différentes sources de journaux.Exemple 1 – Pièce A
| Appareil | Horodatage | Adresse IP Source | Nom d’hôte Source | URL de la demande | Trafic |
| Proxy Web | 1579854825 | 192.168.0.1 | monposte.domain.com | https://www.example.com/index | Autorisé |
| Appareil | Date | SRC_IP | SRC_HST | RQ_URL | Action |
| NGFW | 2020-01-24T08:34:14+00:00 | ::FFF:192.168.0.59 | webproxy | www.example.com | Permis |
Dans cet exemple, vous pouvez voir que le »Nom du champ » et les »Données du champ » sont différents entre les sources de journaux »Proxy Web » et »NGFW ». Essayer de construire des cas d’utilisation complexes avec ce format est extrêmement difficile. Voici une explication des différences problématiques :
- Horodatage: Le Proxy Web est en format Epoch (Unix) tandis que NGFW est en format Zulu (ISO 8601).
- IP Source: Le Proxy Web a une adresse IPv4 tandis que NGFW a une adresse IPv4 mappée en IPv6.
- Hôte Source: Le Proxy Web utilise un FQDN tandis que NGFW ne le fait pas.
- URL de la Demande: Le Proxy utilise la demande complète tandis que NGFW n’utilise que le domaine.
- Trafic/Action: Le Proxy utilise « autorisé » et NGFW utilise « permis ».
Cela s’ajoute aux noms de champs réels qui sont différents. Dans une base de données NoSQL avec un nettoyage médiocre, cela signifie que les termes de requête utilisés pour trouver les journaux Alpha varieront considérablement lorsqu’ils utiliseront les journaux Beta.
Si je ne vous ai pas encore suffisamment fait comprendre ce point ; jetons un coup d’œil à un exemple de cas d’utilisation de détection :
- Cas d’utilisation : Détecter les utilisateurs réussissant à visiter des sites Web malveillants connus.
- Environnement : Le Proxy Web est situé devant le NGFW et est le premier appareil à voir le trafic Web.
- Mises en garde
- Le Proxy Web et le NGFW n’ont pas de listes de blocage identiques. Une demande Web pourrait passer par le Proxy Web pour être ensuite refusée par le NGFW.
- Les demandes sont transmises du proxy au NGFW de manière non transparente. C’est-à-dire que l’adresse IP et le nom d’hôte de la source sont remplacés par l’adresse IP et le nom d’hôte du Proxy Web, et l’analyse uniquement des journaux du NGFW ne vous montrera pas la véritable source de la demande.
- Explication :
- Dans cet exemple, supposons que « Malicious » soit un type de variable qui compare l’URL à une table de consultation d’URL malveillantes connues stockée dans le SIEM.
Notre requête ressemblerait à ceci :
- SÉLECTIONNER RQ_URL, SRC_IP, SRC_HST
OÙ périphérique == NGFW ET RQ_URL = Malicious ET Action = Permis - SÉLECTIONNER URL de demande, IP source, Hôte Source,
OÙ périphérique == Proxy Web ET URL de demande = Malicious ET Trafic = Accepté
Cependant, étant donné les mises en garde connues, l’analyse des résultats d’une seule requête ne nous dirait que ce qui suit :
- NGFW – Le statut final de blocage/refus est connu. La véritable source est inconnue.
- Proxy Web – Le statut final de blocage/refus est inconnu. La véritable source est connue.
Nous avons deux morceaux d’information connexes qui doivent maintenant être joints à l’aide d’une logique d’horodatage floue qui est en réalité simplement un « meilleur des cas » selon deux événements qui se sont produits à peu près en même temps (ouille).CommentCorriger ?Vous vous souvenez de ces éléments plus tôt dans l’article ?
- Transformer – Modifier le format et la structure des données pour mieux répondre à vos besoins.
- Par exemple, analyser un fichier journal JSON en événements distincts en texte brut avec un fichier d’analyse, un fichier de mappage, un script personnalisé, etc.
- Transformation post-charge – Pas une partie officielle du processus ETL; mais, un composant très réel du SIEM.
- Par exemple, utiliser le modélisation des données, les extractions de champs et les alias de champs.
Il existe bien trop de technologies et d’options pour que je puisse expliquer chacune ; mais, je couvrirais un petit vocabulaire de base pour comprendre ce que sont les techniques de transformation :
- Configuration – Pas techniquement une technique de transformation ; mais généralement le meilleur moyen de régler les problèmes de structure et de format de données. Résolvez le problème à la source et évitez tout le reste.
- Analyse/Extractions de champs – Une opération de transformation (pré-ingestion) qui utilise des expressions régulières (regex) pour découper une chaîne en caractères (ou groupes de chaînes) basés sur des motifs. Gère bien les valeurs dynamiques à condition que la structure globale soit statique ; mais, peut être prohibitive en termes de performance avec trop de jokers.
- Mappage – Une opération de transformation qui utilise une bibliothèque d’entrées et de sorties statiques. Peut être utilisé pour attribuer des noms et des valeurs de champ. Ne gère pas bien les entrées dynamiques. Cependant, peut être considéré comme plus efficace que l’analyse si la table de mappage est petite.
- Alias de champ – Similaire au mappage ; mais s’effectue post-chargement et ne change pas nécessairement ce qui est réellement stocké dans le SIEM.
- Modèles de données – Similaire à l’aliasage de champs ; se produisent lors de la recherche.
- Extractions de champs – Similaire à l’analyse et peuvent avoir lieu avant ou après l’ingestion selon la plate-forme.
Disons que nous avons créé un tas d’analyseurs pour appliquer un schéma de champ commun, avons mappé les valeurs des champs pour le trafic de « autorisé » à « permis », avons configuré notre proxy web pour transmettre les informations de source originales, avons configuré notre NGFW pour enregistrer les noms d’hôte avec leur FQDN, et avons utilisé des fonctions pour convertir les horodatages et extraire les adresses IPv4. Nos données ressemblent maintenant à ceci :Exemple 1 – Pièce B
| Appareil | Temps | Source IPv4 | FQDN Source | URL de la demande | Trafic |
| Proxy Web | 24 janvier 2020 – 8h00 | 192.168.0.1 | monposte.domain.com | https://www.example.com/index | Permis |
| Appareil | Temps | Source IPv4 | FQDN Source | URL de la demande | Trafic |
| NGFW | 24 janvier 2020 – 8h01 | 192.168.0.1 | monposte.domain.com | www.example.com | Permis |
Supposons également que le NGFW n’a tout simplement pas pu nous donner l’URL de demande complète car ces informations sont enrichies à la source par la résolution DNS. Notre « pseudo-logique idéal » ressemble maintenant à ceci :
- SÉLECTIONNER IPv4 Source, FQDN Source, URL de demande
OÙ périphérique == NGFW ET URL de demande == Malveillant ET Trafic == Permis
Parce que nous avons configuré notre proxy pour transmettre les informations de source, nous n’avons plus besoin de nous fier à deux sources de données et à une logique d’horodatage floue pour attribuer une activité à une source particulière. Si nous utilisons des tables de consultation et une logique sophistiquée, nous pouvons également trouver facilement quelles sont les URL de demande complètes associées au trafic en utilisant les informations de source couramment formatées comme entrées.Exemple 2À titre d’exemple final, disons que nous voulions créer un rapport qui nous montre tout le trafic web malveillant permis à travers notre réseau ; mais, seul le trafic du Segment A passe par le Proxy Web et seul le trafic du Segment B passe par le NGFW.
Notre requête ressemblerait à ceci avec un mauvais nettoyage de données :
- SÉLECTIONNER URL de demande, RQ_URL, IP source, SRC_IP, Hôte Source, SRC_HST
OÙ (URL de demande = Malveillant ET Trafic = Accepté) OU (RQ_URL = Malveillant ET Action = Permise)
Et comme ceci avec un bon nettoyage de données :
- SÉLECTIONNER URL de demande, IPv4 Source, FQDN Source,
OÙ URL de demande = Malveillant ET Trafic = Accepté
Les formats communs, le schéma et les types de valeurs nous donnent de meilleures performances de requête et facilitent la recherche et la création de contenu. Il y a un ensemble limité de noms de champs à retenir et les valeurs des champs auront, pour la plupart, la même apparence sauf pour l’URL de demande du NGFW.
Je ne saurais trop insister sur la façon dont cela est plus élégant et efficace pour une analyse rapide et le développement de contenu.ConclusionCeci a été une manière très exhaustive de dire qu’une utilisation efficace du SIEM nécessite (a) un plan, (b) une collaboration inter-fonctionnelle solide, et (c) une intention claire de structurer les données dès le départ. Investir dans ces premières étapes vous prépare pour des gains rapides plus tard.
Si cet article vous a plu, merci de le partager avec d’autres et de garder un œil sur « Fondamentaux SIEM (Partie 2) : Utiliser efficacement les alertes, tableaux de bord et rapports. Si vous avez vraiment aimé cet article et voulez montrer un peu de soutien, vous pouvez découvrir notre Marché de Détection des Menaces (contenu SIEM gratuit), notre Pack de Sources de Journaux ECS Premium (nettoyeurs de données pour Elastic) et Maintenance Prédictive (résout les problèmes de collecte de données discutés ici).


