

IntroducciónEl objetivo de esta serie es poner a los lectores en la mentalidad correcta al pensar en SIEM y describir cómo prepararse para el éxito. Aunque no soy un científico de datos y no pretendo serlo, puedo decir con confianza que esperar resultados en análisis de seguridad sin antes tener ‘buenos datos’ para trabajar es una locura. Por eso siempre digo que ‘los análisis de seguridad son, ante todo, un problema de recopilación de datos’ y por qué la parte 1 del blog Fundamentos de SIEM está centrada en cómo abordar la recopilación de datos.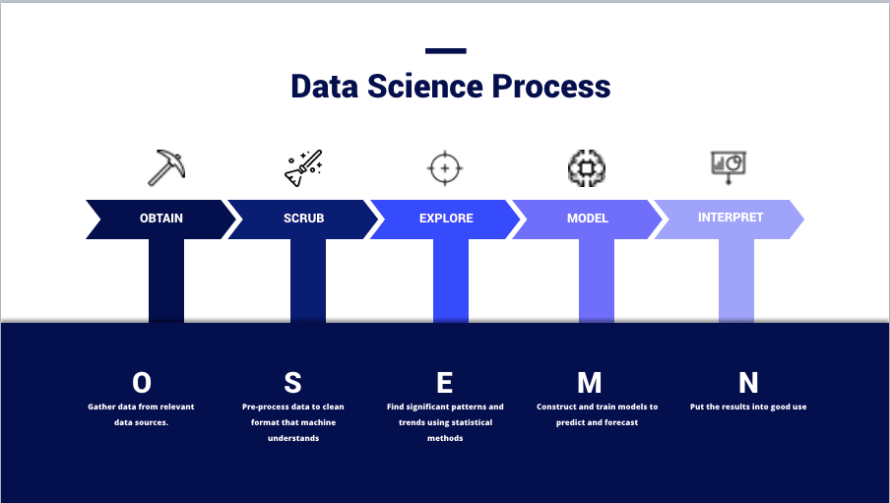
(Imagen de – https://thelead.io/data-science/5-steps-to-a-data-science-project-lifecycle)Esta imagen es una visualización del marco OSEMN que muchos científicos de datos utilizan al planificar un proyecto y es efectivamente cómo los equipos convierten datos en información. El propósito completo de usar un SIEM no es almacenar datos, sino crear información nueva y útil que pueda ser utilizada para mejorar la seguridad.
Obtener datos y limpiarlos no es una hazaña menor. De hecho, muchos científicos de datos ven cada una de estas fases como especialidades o dominios distintos dentro de la práctica. No es raro encontrar individuos dedicados a una sola fase. No apreciar esto es la razón por la que muchos equipos no logran derivar valor de un SIEM; toda la exageración del marketing facilita el pasar por alto cuánto esfuerzo se requiere del usuario final en cada fase del proceso y es algo que los buenos equipos continuarán iterando a medida que cambia su entorno y el panorama de amenazas.
Pasemos un momento hablando sobre ETL, ya que esto ayuda a describir algunas de las próximas secciones.
- Extracción – Obtener realmente que la fuente de datos emita registros en algún lugar en algún formato. Es importante señalar que esta es la única fase en la que se puede introducir nuevos datos originales a un conjunto de datos a través de la configuración.
- P. ej., configurar la fuente de registros para informar los campos “X, Y y Z” utilizando syslog remoto con un formato específico como pares clave-valor o listas delimitadas por comas.
- Transformación – Modificar el formato y la estructura de los datos para adaptarlos mejor a sus necesidades.
- P. ej., analizar un archivo de registro JSON en eventos de texto simple distintos con un archivo de análisis, archivo de mapeo, script personalizado, etc.
- Carga – Escribir los datos en la base de datos.
- P. ej., usar software que interprete los eventos de texto claro y los envíe a la base de datos con instrucciones INSERT u otras APIs públicas.
- Transformación posterior a la carga – No es una parte oficial del proceso ETL; pero, un componente muy real de SIEM.
- P. ej., utilizando modelado de datos, extracciones de campo y alias de campo.
ObtenerRecopilar datos, a pequeña escala, es sencillo. Sin embargo, SIEM no es a pequeña escala, y averiguar cómo obtener datos relevantes de manera confiable es crítico.Entrega confiablePara esta sección, nos enfocaremos en la Extracción y Carga.
- Extracción
- ¿De qué es capaz de emitir mi fuente de datos?
- ¿Qué campos y formatos se pueden utilizar?
- ¿Qué métodos de transporte están disponibles?
- ¿Es este un dispositivo del que podemos ‘empujar’ datos hacia un receptor o tenemos que ‘tirarlos’ mediante solicitudes?
- Carga
- ¿Cómo aseguramos que los datos se entreguen de manera oportuna y confiable?
- ¿Qué sucede si un receptor cae? ¿Perderemos los datos que se envían durante una interrupción?
- ¿Cómo aseguramos que las solicitudes de extracción se completen exitosamente?
En el mundo de SIEM, a menudo sucede que la funcionalidad de ‘extracción’ se proporciona junto con la de ‘carga’; especialmente en casos donde se utiliza software adicional (conectores, beats y agentes).
Sin embargo, hay un espacio oculto entre estos dos donde encajan los ‘brokers de eventos‘. Debido a que los datos deben ser entregados a través de una red, los brokers de eventos son tecnologías como Kafka y Redis que pueden manejar balanceo de carga, almacenamiento en caché de eventos y enrutamiento. A veces, los brokers de eventos pueden usarse para escribir datos directamente en el almacenamiento objetivo; pero, también pueden estar emitiendo a un ‘cargador’ tradicional de una manera en cadena.
Realmente no hay una forma correcta o incorrecta de construir su canalización respecto a estos factores. La mayoría de esto será dictado por la tecnología SIEM que use. Sin embargo, es importante estar consciente de cómo funcionan estas cosas y estar preparado para abordar los desafíos únicos de cada uno mediante soluciones de ingeniería.Elegir fuentes de registroNo salga a recopilar datos de todo solo porque su proveedor de SIEM le dijo que lo hiciera; siempre tenga un plan y siempre tenga una buena justificación para recopilar los datos que ha elegido. En este punto del proceso, deberíamos estarnos preguntando las siguientes preguntas al elegir datos relevantes:
- Entendiendo la Información
- ¿Qué actividad proporciona visibilidad?
- ¿Qué tan autoritativa es esta fuente de datos?
- ¿Esta fuente de datos proporciona toda la visibilidad necesaria o se requieren fuentes adicionales?
- ¿Se pueden usar estos datos para enriquecer otros conjuntos de datos?
- Determinando la relevancia
- ¿Cómo pueden estos datos ayudar a cumplir políticas, estándares u objetivos definidos por la política de seguridad?
- ¿Cómo pueden estos datos mejorar la detección de una amenaza/actor de amenaza específico?
- ¿Cómo pueden usarse estos datos para generar una nueva perspectiva sobre operaciones existentes?
- Midiendo la integridad
- ¿El dispositivo ya proporciona los datos que necesitamos en el formato que queremos?
- Si no, ¿se puede configurar para que lo haga?
- ¿La fuente de datos está configurada para máxima verbosidad?
- ¿Se requerirá enriquecimiento adicional para hacer que esta fuente de datos sea útil?
- Analizando la estructura
- ¿Los datos están en un formato legible por humanos?
- ¿Qué hace que estos datos sean fáciles de leer y deberíamos adoptar un formato similar para datos del mismo tipo?
- ¿Los datos están en un formato legible por máquina?
- ¿Qué tipo de archivo son los datos y cómo interpretará una máquina este tipo de archivo?
- ¿Cómo se presentan los datos?
- ¿Es un formato clave-valor, delimitado por comas, o algo más?
- ¿Tenemos buena documentación para este formato?
- ¿Los datos están en un formato legible por humanos?
Los problemas comunes encontrados al entender su información surgen de una documentación interna deficiente o de la falta de experiencia de la fuente de registro en sí y de la arquitectura de red. Determinar la relevancia requiere la entrada de especialistas en seguridad y propietarios de políticas. En todos los casos, contar con personal experimentado y conocedor participando desde el principio es una ventaja para toda la operación.LimpiarAhora, pasemos al tema más interesante de la limpieza de datos. A menos que esté familiarizado con esto, puede que se haga las siguientes preguntas:
- Hola, ¿no debería simplemente funcionar?
- ¿Por qué los datos no están ya limpios, se le cayó café a un ingeniero?
- La higiene suena como un asunto personal, ¿es esto algo en lo que necesitamos que Recursos Humanos opine?
La realidad es que, por impresionantes que sean las máquinas, no son tan inteligentes (aún). El único conocimiento que tienen es el conocimiento con el que las construimos.Por ejemplo, un humano puede mirar el texto “Rob3rt” y entender que significa “Robert”. Sin embargo, una máquina no sabe que el número “3” puede representar a menudo la letra “e” en inglés a menos que haya sido preprogramada con ese conocimiento. Un ejemplo más real sería manejar diferencias en el formato como “3000” vs “3,000” vs “3K”. Como humanos, sabemos que todos significan lo mismo; pero, una máquina se tambalea con la “,” en “3,000” y no sabe interpretar “K” como “000”.Para SIEM, esto es importante al analizar datos a través de fuentes de registro.Ejemplo 1 – Local A
| Dispositivo | Marca de tiempo | Dirección IP de origen | Nombre de host de origen | URL de solicitud | Tráfico |
| Proxy Web | 1579854825 | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | Permitido |
| Dispositivo | Fecha | SRC_IP | SRC_HST | RQ_URL | Acción |
| NGFW | 2020-01-24T08:34:14+00:00 | ::FFF:192.168.0.59 | webproxy | www.example.com | Permitido |
En este ejemplo, puede ver que el “Nombre de Campo” y el “Dato de Campo” son diferentes entre las fuentes de registro “Proxy Web” y “NGFW”. Intentar construir casos de uso complejos con este formato es extremadamente desafiante. Aquí hay un desglose de las diferencias problemáticas:
- Marca de tiempo: Proxy Web está en formato Época (Unix) mientras que NGFW está en formato Zulu (ISO 8601).
- IP de origen: Proxy Web tiene una dirección IPv4 mientras que NGFW tiene una dirección IPv4 mapeada a IPv6.
- Host de origen: Proxy Web usa un FQDN mientras que NGFW no.
- URL de solicitud: Proxy usa la solicitud completa mientras que NGFW solo usa el dominio.
- Tráfico/Acción: Proxy usa “permitido” y NGFW usa “permitido”.
Esto se suma a los nombres de campo reales siendo diferentes. En una base de datos NoSQL con una limpieza deficiente, esto significa que los términos de consulta utilizados para encontrar registros Alfa variarán significativamente al usar registros Beta.
Si aún no he dejado muy claro este punto; echemos un vistazo a un caso de uso de detección de muestra:
- Caso de Uso: Detectar usuarios exitosamente visitando sitios web maliciosos conocidos.
- Entorno: El Proxy Web se encuentra frente al NGFW y es el primer dispositivo en ver el tráfico web.
- Advertencias
- El Proxy Web y NGFW no tienen listas de bloque idénticas. Una solicitud web podría pasar a través del Proxy Web solo para ser posteriormente denegada por el NGFW.
- Las solicitudes se reenvían desde el proxy al NGFW de manera no transparente. Es decir, la IP de origen y el Nombre de Host son reemplazados por la IP y el Nombre de Host del Proxy Web y al analizar solo los registros de NGFW no se mostrará la verdadera fuente de la solicitud.
- Explicación:
- En este ejemplo, supongamos que “Malicioso” es algún tipo de variable que compara la URL contra una tabla de búsqueda de URLs maliciosas conocidas almacenadas en el SIEM.
Nuestra consulta se vería así:
- SELECT RQ_URL, SRC_IP, SRC_HST
WHERE Device == NGFW AND RQ_URL = Malicious AND Action = Permitted - SELECT URL de Solicitud, IP de Origen, Host de Origen,
WHERE Device == Proxy Web AND URL de Solicitud = Malicioso AND Tráfico = Aceptado
Sin embargo, dadas las advertencias conocidas, analizar los resultados de una sola consulta solo nos diría lo siguiente:
- NGFW – El estado final de bloqueo/denegación se conoce. La verdadera fuente es desconocida.
- Proxy Web – El estado final de bloqueo/denegación es desconocido. La verdadera fuente es conocida.
Tenemos 2 piezas de información relacionadas que ahora deben unirse utilizando alguna lógica temporal difusa que realmente es solo una ‘mejor suposición’ según dos eventos que ocurrieron alrededor del mismo periodo de tiempo (uff).¿Cómo solucionar?¿Recuerdas estos de antes en el artículo?
- Transformación – Modificar el formato y la estructura de los datos para adaptarlos mejor a sus necesidades.
- P. ej., analizar un archivo de registro JSON en eventos de texto simple distintos con un archivo de análisis, archivo de mapeo, script personalizado, etc.
- Transformación posterior a la carga – No es una parte oficial del proceso ETL; pero, un componente muy real de SIEM.
- P. ej., utilizando modelado de datos, extracciones de campo y alias de campo.
Hay demasiadas tecnologías y opciones para que pueda explicar cada una; pero, cubriré algo de vocabulario básico para entender cuáles son las técnicas de transformación:
- Configuración – No es técnicamente una técnica de transformación; pero, típicamente la mejor manera de abordar problemas de estructura y formato de datos. Arregle el problema en la fuente y omita todo lo demás.
- Análisis/Extracciones de Campo – Una operación de transformación (previa a la ingesta) que utiliza expresiones regulares (regex) para dividir una cadena en caracteres (o grupos de cadenas) basados en patrones. Maneja bien los valores dinámicos siempre que la estructura general sea estática; pero, puede ser prohibitivamente oneroso en términos de rendimiento con demasiados comodines.
- Mapeo – Una operación de transformación que utiliza una biblioteca de entradas y salidas estáticas. Puede usarse para asignar nombres de campo y valores. No maneja bien la entrada dinámica. Sin embargo, puede considerarse más eficiente que el análisis si la tabla de mapeo es pequeña.
- Alias de Campo – Similar al mapeo; pero, ocurre después de la carga y no necesariamente cambia el valor almacenado en el SIEM.
- Modelos de Datos – Similar al alias de campo; ocurre en tiempo de búsqueda.
- Extracciones de Campo – Similar al análisis y puede ocurrir antes o después de la ingesta dependiendo de la plataforma.
Digamos que creamos un montón de analizadores para imponer un esquema de campo común, mapeamos los valores de campo para tráfico de ‘permitido’ a ‘permitido’, configuramos nuestro proxy web para reenviar la IP de origen original y el host, configuramos nuestro NGFW para registrar nombres de host con su FQDN y utilizamos funciones para convertir marcas de tiempo y extraer direcciones IPv4. Nuestros datos ahora se ven así:Ejemplo 1 – Local B
| Dispositivo | Hora | IPv4 de Origen | FQDN de Origen | URL de Solicitud | Tráfico |
| Proxy Web | 24 de enero de 2020 – 8:00 AM | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | Permitido |
| Dispositivo | Hora | IPv4 de Origen | FQDN de Origen | URL de Solicitud | Tráfico |
| NGFW | 24 de enero de 2020 – 8:01 AM | 192.168.0.1 | myworkstation.domain.com | www.example.com | Permitido |
Supongamos también que el NGFW simplemente no podía darnos la URL de solicitud completa porque esta información se enriquece en la fuente a través de la resolución DNS. Nuestra ‘lógica pseudoideal’ ahora se ve así:
- SELECT IPv4 de Origen, FQDN de Origen, URL de Solicitud
WHERE Device == NGFW AND URL de Solicitud == Malicioso AND Tráfico == Permitido
Debido a que hemos configurado nuestro proxy para reenviar la información de origen, ya no tenemos que depender de dos fuentes de datos y lógica temporal incierta para atribuir actividad a una fuente particular. Si usamos tablas de búsqueda y algo de lógica sofisticada, también podemos averiguar fácilmente cuáles son las URL de solicitudes completas asociadas con el tráfico utilizando la información de origen comúnmente formateada como entradas.Ejemplo 2Como un ejemplo final, supongamos que queríamos construir un informe que nos muestre todo el tráfico web malicioso permitido en nuestra red; pero, solo el tráfico del Segmento A pasa por el Proxy Web y solo el tráfico del Segmento B pasa por el NGFW.
Nuestra consulta se vería así con una mala limpieza de datos:
- SELECT URL de Solicitud, RQ_URL, IP de Origen, SRC_IP, Host de Origen, SRC_HST
WHERE (URL de Solicitud = Malicioso Y Tráfico = Aceptado) O (RQ_URL = Malicioso Y Acción = Permitido)
Y así con una buena limpieza de datos:
- SELECT URL de Solicitud, IPv4 de Origen, FQDN de Origen,
WHERE URL de Solicitud = Malicioso Y Tráfico = Aceptado
Los formatos comunes, el esquema y los tipos de valor nos brindan un mejor rendimiento de consulta y facilitan la búsqueda y la creación de contenido. Hay un conjunto limitado de nombres de campo para recordar y los valores de campo, en su mayoría, se verán idénticos con la excepción de la URL de Solicitud para el NGFW.
No puedo enfatizar lo suficiente lo mucho más elegante y efectivo que esto es para un análisis rápido y desarrollo de contenido.ConclusiónEsta ha sido una forma muy detallada de decir que el uso efectivo de SIEM requiere (a) un plan, (b) una fuerte colaboración transversal y (c) una intención clara de estructurar datos desde el principio. Invertir en estas fases tempranas te prepara para logros rápidos en el futuro.
Si te gustó este artículo, por favor compártelo con otros y mantente atento a “Fundamentos de SIEM (Parte 2): Usar Alertas, Tableros y Informes Efectivamente“. Si realmente te gustó este artículo y deseas mostrar apoyo, puedes visitar nuestro Mercado de Detección de Amenazas (contenido SIEM gratuito), nuestro Paquete de Fuente de Registro ECS Premium (limpiadores de datos para Elastic) y Mantenimiento Predictivo (resuelve los problemas de recopilación de datos aquí discutidos).


