

EinführungDas Ziel dieser Serie ist es, die Leser in die richtige Denkweise zu versetzen, wenn sie an SIEM denken, und zu beschreiben, wie sie sich für den Erfolg rüsten können. Obwohl ich kein Datenwissenschaftler bin und das auch nicht behaupte, kann ich mit Sicherheit sagen, dass es töricht ist, ohne vorher „gute Daten“ zu haben, mit denen man arbeiten kann, Ergebnisse in der Sicherheitsanalytik zu erwarten. Aus diesem Grund sage ich immer, dass „Sicherheitsanalytik in erster Linie ein Problem der Datenerfassung ist“ und warum Teil 1 des SIEM-Grundlagen-Blogs sich darauf konzentriert, wie man an die Datenerfassung herangeht.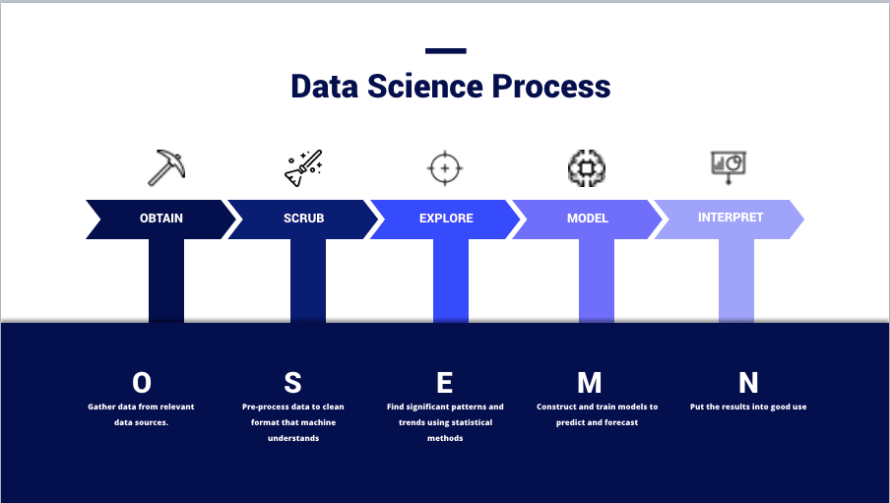
(Bild von – https://thelead.io/data-science/5-steps-to-a-data-science-project-lifecycle)Dieses Bild ist eine Visualisierung des OSEMN-Rahmens, den viele Datenwissenschaftler nutzen, wenn sie ein Projekt planen, und zeigt effektiv, wie Teams Daten in Informationen umwandeln. Der gesamte Zweck der Nutzung eines SIEM besteht nicht darin, Daten zu speichern; sondern darin, neue und nützliche Informationen zu erstellen, die zur Verbesserung der Sicherheit verwendet werden können.
Daten zu beschaffen und zu bereinigen ist keine kleine Aufgabe. Tatsächlich betrachten viele Datenwissenschaftler jede dieser Phasen als eigenständige Spezialitäten oder Domänen innerhalb der Praxis. Es ist nicht ungewöhnlich, Einzelpersonen zu finden, die sich einer einzigen Phase widmen. Nicht zu erkennen, dass dies der Grund ist, warum viele Teams es nicht schaffen, aus einem SIEM Wert zu ziehen; all der Hype im Marketing macht es leicht zu übersehen, wie viel Aufwand vom Endbenutzer in jeder Phase des Prozesses erforderlich ist, und ist etwas, was gute Teams kontinuierlich durchlaufen werden, während sich ihre Umgebung und die Bedrohungslage verändert.
Lassen Sie uns einen Moment über ETL sprechen, da dies einige der nächsten Abschnitte beschreibt.
- Extrahieren – Tatsächlich die Datenquelle dazu bringen, Protokolle irgendwo in einem bestimmten Format auszugeben. Wichtig zu beachten ist, dass dies die einzige Phase ist, in der neue Originaldaten über die Konfiguration in einen Datensatz eingeführt werden können.
- Z.B. Die Konfiguration der Protokollquelle zur Berichterstattung über die Felder „X, Y und Z“ mithilfe von Remote-Syslog mit einem spezifischen Format wie Schlüssel-Wert-Paare oder kommagetrennte Listen.
- Transformieren – Ändern des Formats und der Struktur der Daten, um sie besser an Ihre Bedürfnisse anzupassen.
- Z.B. Parsen einer JSON-Protokolldatei in getrennte Klartext-Ereignisse mit einer Parser-Datei, Mapping-Datei, einem benutzerdefinierten Skript usw.
- Laden – das Schreiben der Daten in die Datenbank.
- Z.B. Verwendung einer Software, die die Klartext-Ereignisse interpretiert und sie mit INSERT-Anweisungen oder anderen öffentlichen APIs in die Datenbank sendet.
- Nachverarbeitungstransformation – kein offizieller Bestandteil des ETL-Prozesses, aber ein sehr reales Element eines SIEM.
- Z.B. Verwendung von Datenmodellierung, Feldextraktionen und Feldaliasen.
BeschaffenDas Sammeln von Daten ist im kleinen Maßstab einfach. SIEM ist jedoch kein kleiner Maßstab, und es ist entscheidend, herauszufinden, wie man relevante Daten zuverlässig beschaffen kann.Zuverlässige LieferungIn diesem Abschnitt konzentrieren wir uns auf Extraktion und Laden.
- Extraktion
- Wozu ist meine Datenquelle in der Lage, was die Ausgabe angeht?
- Welche Felder und Formate können verwendet werden?
- Welche Transportmethoden stehen zur Verfügung?
- Handelt es sich um ein Gerät, von dem wir Daten zu einem Zuhörer „pushen“ können, oder müssen wir sie über Anfragen „ziehen“?
- Laden
- Wie stellen wir sicher, dass Daten rechtzeitig und zuverlässig geliefert werden?
- Was passiert, wenn ein Zuhörer ausfällt? Werden wir Daten verlieren, die während eines Ausfalls gepusht werden?
- Wie stellen wir sicher, dass Pull-Anfragen erfolgreich abgeschlossen werden?
In der SIEM-Welt ist es oft der Fall, dass die „Extraktions“-Funktionalität neben der „Lade“-Funktionalität bereitgestellt wird, insbesondere in Fällen, in denen zusätzliche Software (Konnektoren, Beats und Agenten) verwendet werden.
Es gibt jedoch einen versteckten Raum zwischen diesen beiden, in dem „Event-Broker“ passen. Da Daten über ein Netzwerk geliefert werden müssen, sind Event-Broker Technologien wie Kafka und Redis, die Lastverteilung, Event-Caching und Queueing handhaben können. Manchmal können Event-Broker verwendet werden, um tatsächlich Daten in den Zielspeicher zu schreiben; können aber auch in einer Art Reihenschaltung zu einem traditionellen „Lader“ ausgeben.
Es gibt wirklich keinen richtigen oder falschen Weg, Ihre Pipeline im Hinblick auf diese Faktoren zu erstellen. Das meiste davon wird von der verwendeten SIEM-Technologie diktiert. Es ist jedoch wichtig, sich dessen bewusst zu sein, wie diese Dinge funktionieren, und vorbereitet zu sein, die einzigartigen Herausforderungen jedes Einzelnen durch technische Lösungen anzugehen.Protokollquellen wählenSammeln Sie keine Daten von allem, nur weil Ihr SIEM-Anbieter es Ihnen gesagt hat; haben Sie immer einen Plan und rechtfertigen Sie stets, warum Sie die gewählten Daten sammeln. An diesem Punkt des Prozesses sollten wir uns die folgenden Fragen stellen, wenn wir relevante Daten auswählen:
- Verständnis von Informationen
- Welche Aktivitäten bietet dies einsehbar?
- Wie autoritativ ist diese Datenquelle?
- Bietet diese Datenquelle die gesamte benötigte Sichtbarkeit oder sind zusätzliche Quellen erforderlich?
- Kann diese Daten genutzt werden, um andere Datensätze anzureichern?
- Relevanz bestimmen
- Wie können diese Daten helfen, Richtlinien, Standards oder Ziele der Sicherheitsrichtlinie zu erreichen?
- Wie können diese Daten die Erkennung einer bestimmten Bedrohung oder eines Bedrohungsakteurs verbessern?
- Wie können diese Daten genutzt werden, um neuartige Einblicke in bestehende Abläufe zu gewinnen?
- Vollständigkeit messen
- Stellt das Gerät bereits die Daten bereit, die wir im gewünschten Format benötigen?
- Wenn nicht, kann es so konfiguriert werden?
- Ist die Datenquelle für maximale Verbosität konfiguriert?
- Wird zusätzliche Anreicherung erforderlich sein, um diese Datenquelle nützlich zu machen?
- Strukturanalyse
- Sind die Daten in einem menschlich lesbaren Format?
- Was macht diese Daten leicht lesbar und sollten wir ein ähnliches Format für Daten desselben Typs übernehmen?
- Sind die Daten in einem maschinenlesbaren Format?
- Welches Dateiformat haben die Daten und wie wird eine Maschine dieses Dateiformat interpretieren?
- Wie werden die Daten präsentiert?
- Ist es ein Schlüssel-Wert-Format, kommagetrennt oder etwas anderes?
- Haben wir gute Dokumentation für dieses Format?
- Sind die Daten in einem menschlich lesbaren Format?
Häufige Probleme beim Verständnis Ihrer Informationen ergeben sich aus schlechter interner Dokumentation oder mangelnder Expertise der Protokollquelle selbst und der Netzwerkarchitektur. Die Bestimmung der Relevanz erfordert Input von Sicherheitsspezialisten und Richtlinienverantwortlichen. In allen Fällen ist es ein Vorteil für den gesamten Betrieb, wenn erfahrenes und sachkundiges Personal frühzeitig beteiligt ist.ReinigenJetzt zum interessanteren Thema des Datenreinigens. Wenn Sie mit diesem nicht vertraut sind, könnten Sie sich die folgenden Fragen stellen:
- Hallo, sollte es nicht einfach funktionieren?
- Warum sind die Daten nicht schon sauber, hat ein Ingenieur Kaffee darüber verschüttet?
- Hygiene klingt wie ein persönliches Problem – müssen wir das bei HR ansprechen?
Die Realität ist, so großartig Maschinen auch sind, so klug sind sie nicht (*noch nicht). Das einzige Wissen, das sie haben, ist das Wissen, mit dem wir sie gebaut haben.Zum Beispiel kann ein Mensch den Text „Rob3rt“ ansehen und verstehen, dass er „Robert“ bedeutet. Eine Maschine weiß jedoch nicht, dass die Zahl „3“ im Englischen oft den Buchstaben „e“ darstellen kann, es sei denn, sie wurde mit diesem Wissen vorprogrammiert. Ein realistischeres Beispiel wäre der Umgang mit Formatunterschieden wie „3000“ vs. „3.000“ vs. „3K“. Als Menschen wissen wir, dass das alles das Gleiche bedeutet, aber eine Maschine wird von dem „.“ in „3.000“ verwirrt und weiß nicht, dass „K“ als „000“ zu interpretieren ist.Für SIEM ist dies bei der Datenanalyse über Protokollquellen hinweg wichtig.Beispiel 1 – Anhang A
| Gerät | Zeitstempel | Quelle IP-Adresse | Quell-Host-Name | Anforderungs-URL | Verkehr |
| Web-Proxy | 1579854825 | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | Erlaubt |
| Gerät | Datum | SRC_IP | SRC_HST | RQ_URL | Aktion |
| NGFW | 2020-01-24T08:34:14+00:00 | ::FFF:192.168.0.59 | webproxy | www.example.com | Erlaubt |
In diesem Beispiel können Sie sehen, dass der „Feldname“ und die „Felddaten“ zwischen den Protokollquellen „Web-Proxy“ und „NGFW“ unterschiedlich sind. Der Versuch, komplexe Anwendungsfälle mit diesem Format zu erstellen, ist äußerst anspruchsvoll. Hier ist eine Aufschlüsselung der problematischen Unterschiede:
- Zeitstempel: Web-Proxy ist im Epoch (Unix)-Format, während NGFW im Zulu (ISO 8601)-Format ist.
- Quell-IP: Der Web-Proxy hat eine IPv4-Adresse, während NGFW eine IPv4-zu-IPv6 gemappte Adresse hat.
- Quell-Host: Der Web-Proxy verwendet einen FQDN, während NGFW dies nicht tut.
- Anforderungs-URL: Proxy verwendet die vollständige Anforderung, während NGFW nur die Domäne verwendet.
- Verkehr/Aktion: Proxy verwendet „erlaubt“ und NGFW verwendet „erlaubt“.
Dies zusätzlich zu den tatsächlichen Feldnamen, die unterschiedlich sind. In einer NoSQL-Datenbank mit schlechter Bereinigung bedeutet dies, dass die Abfragebegriffe, die für das Finden von Alpha-Protokollen verwendet werden, erheblich variieren, wenn Beta-Protokolle verwendet werden.
Wenn ich diesen Punkt bisher nicht hart genug verdeutlicht habe, lassen Sie uns einen Blick auf einen Beispielsfall zur Erkennung werfen:
- Anwendungsfall: Erkennung von Benutzern erfolgreich bekannte bösartige Websites besuchen.
- Umgebung: Der Web-Proxy befindet sich vor dem NGFW und ist das erste Gerät, das den Webverkehr sieht.
- Einschränkungen
- Der Web-Proxy und NGFW haben nicht identische Blocklisten. Eine Webanfrage könnte es durch den Web-Proxy schaffen, nur um später vom NGFW blockiert zu werden.
- Anfragen werden nicht transparent vom Proxy zum NGFW weitergeleitet. I.E. Die Quell-IP und der Host-Name werden durch die IP und den Host-Namen des Web-Proxys ersetzt, und die Analyse nur der NGFW-Protokolle zeigt Ihnen nicht die wahre Quelle der Anfrage.
- Erläuterung:
- In diesem Beispiel nehmen wir an, dass „Malicious“ eine Art Variable ist, die die URL mit einer in der SIEM gespeicherten Nachschlagetabelle bekannter bösartiger URLs vergleicht.
Unsere Abfrage würde so aussehen:
- SELECT RQ_URL, SRC_IP, SRC_HST
WHERE Device == NGFW AND RQ_URL = Malicious AND Action = Erlaubt - SELECT Anforderungs-URL, Quell-IP, Quell-Host,
WHERE Device == Web Proxy AND Anforderungs-URL = Malicious AND Verkehr = Akzeptiert
Angesichts der bekannten Einschränkungen würde die Analyse der Ergebnisse einer einzelnen Abfrage nur Folgendes aufzeigen:
- NGFW – Der endgültige Block-/Verweigerungsstatus ist bekannt. Die wahre Quelle ist unbekannt.
- Web-Proxy – Der endgültige Block-/Verweigerungsstatus ist unbekannt. Die wahre Quelle ist bekannt.
Wir haben 2 verwandte Informationen, die nun mit einer unscharfen Zeitstempellogik verbunden werden müssen, die wirklich nur ein „bestes Schätzung“ ist gemäß zwei Ereignissen, die ungefähr zur gleichen Zeit stattgefunden haben (oh weh).Wie zu reparieren?Erinnern Sie sich an diese Punkte aus dem Artikel weiter oben?
- Transformieren – Ändern des Formats und der Struktur der Daten, um sie besser an Ihre Bedürfnisse anzupassen.
- Z.B. Parsen einer JSON-Protokolldatei in getrennte Klartext-Ereignisse mit einer Parser-Datei, Mapping-Datei, einem benutzerdefinierten Skript usw.
- Nachverarbeitungstransformation – kein offizieller Bestandteil des ETL-Prozesses, aber ein sehr reales Element eines SIEM.
- Z.B. Verwendung von Datenmodellierung, Feldextraktionen und Feldaliasen.
Es gibt viel zu viele Technologien und Optionen, als dass ich jede einzelne erklären könnte; aber, ich werde einige grundlegende Vokabeln erläutern, um zu verstehen, welche Transformationstechniken es gibt:
- Konfiguration – Technisch gesehen keine Transformations-Technik; aber, in der Regel der beste Weg, Datenstruktur- und Formatprobleme anzugehen. Das Problem an der Quelle beheben und alles andere überspringen.
- Parsing/Feldauszüge – Eine Transformations-Operation (vor der Ingestion), die reguläre Ausdrücke (Regex) nutzt, um einen String in Zeichenfolgen (oder Gruppen von Strings) basierend auf Mustern zu unterteilen. Handhabt dynamische Werte gut, vorausgesetzt, die Gesamtstruktur ist statisch; kann jedoch leistungsschwach sein, wenn zu viele Platzhalter verwendet werden.
- Mapping – Eine Transformations-Operation, die eine Bibliothek von statischen Eingaben und Ausgaben verwendet. Kann verwendet werden, um Feldnamen und -werte zuzuweisen. Handhabt dynamische Eingaben nicht gut. Kann jedoch als effizienter als Parsing angesehen werden, wenn die Mapping-Tabelle klein ist.
- Feldaliasing – Ähnlich wie Mapping; erfolgt jedoch nach dem Laden und ändert nicht unbedingt die tatsächlich im SIEM gespeicherten Daten.
- Datenmodelle – Ähnlich wie Feldaliasing; erfolgt zur Suchzeit.
- Feldauszüge – Ähnlich wie Parsing kann vor oder nach der Ingestion erfolgen, abhängig von der Plattform.
Angenommen, wir haben viele Parser erstellt, um ein gemeinsames Feldschema durchzusetzen, die Feldwerte für den Verkehr von „erlaubt“ zu „erlaubt“ gemappt, den Web-Proxy so konfiguriert, dass die ursprüngliche Quell-IP und der Host weitergeleitet wird, unseren NGFW so konfiguriert, dass Hostnamen mit ihren FQDN protokolliert werden, und Funktionen zur Umwandlung von Zeitstempeln und zur Extraktion von IPv4-Adressen genutzt haben. Unsere Daten sehen nun so aus:Beispiel 1 – Anhang B
| Gerät | Zeit | Quelle IPv4 | Quelle FQDN | Anforderungs-URL | Verkehr |
| Web-Proxy | 24. Januar 2020 – 08:00 Uhr | 192.168.0.1 | myworkstation.domain.com | https://www.example.com/index | Erlaubt |
| Gerät | Zeit | Quelle IPv4 | Quelle FQDN | Anforderungs-URL | Verkehr |
| NGFW | 24. Januar 2020 – 08:01 Uhr | 192.168.0.1 | myworkstation.domain.com | www.example.com | Erlaubt |
Angenommen, der NGFW konnte uns die vollständige Anforderungs-URL nicht geben, da diese Informationen durch DNS-Auflösung an der Quelle angereichert wurden. Unser „ideales Pseudo-Logik“ sieht nun so aus:
- SELECT Quelle IPv4, Quelle FQDN, Anforderungs-URL
WHERE Device == NGFW AND Anforderungs-URL == Malicious AND Verkehr == Erlaubt
Da wir unseren Proxy so konfiguriert haben, dass die Quelleninformationen weitergeleitet werden, müssen wir uns nicht mehr auf zwei Datenquellen und unscharfe Zeitstempellogik verlassen, um Aktivitäten einer bestimmten Quelle zuzuordnen. Wenn wir Nachschlagetabellen und etwas ausgeklügelte Logik verwenden, können wir auch leicht herausfinden, was die vollständigen Anforderungs-URLs im Zusammenhang mit dem Verkehr sind, indem wir die allgemein formatierten Quelleninformationen als Eingaben verwenden.Beispiel 2Als abschließendes Beispiel nehmen wir an, dass wir einen Bericht erstellen wollten, der uns den gesamten erlaubten bösartigen Webverkehr in unserem Netzwerk zeigt; jedoch geht nur Segment A’s Verkehr durch den Web-Proxy und nur Segment B’s Verkehr durch den NGFW.
Unsere Abfrage würde so mit schlechter Datenbereinigung aussehen:
- SELECT Anforderungs-URL, RQ_URL, Quelle IP, SRC_IP, Quelle Host, SRC_HST
WHERE (Anforderungs-URL = Malicious AND Verkehr = Akzeptiert) OR (RQ_URL = Malicious AND Aktion = Erlaubt)
Und so mit guter Datenbereinigung:
- SELECT Anforderungs-URL, Quelle IPv4, Quelle FQDN,
WHERE Anforderungs-URL = Malicious AND Verkehr = Akzeptiert
Die gemeinsamen Formate, Schemas und Wertetypen verschaffen uns eine bessere Abfrageleistung und machen das Suchen und Erstellen von Inhalten wesentlich einfacher. Es gibt eine begrenzte Anzahl von Feldnamen, die man sich merken muss, und die Feldwerte werden größtenteils identisch aussehen, mit Ausnahme der Anforderungs-URL für das NGFW.
Ich kann gar nicht genug betonen, wie viel eleganter und effektiver dies für die schnelle Analyse und die Inhaltsentwicklung ist.SchlussfolgerungDies war ein sehr ausführlicher Weg, um zu sagen, dass die effektive Nutzung von SIEM (a) einen Plan, (b) starke funktionsübergreifende Zusammenarbeit und (c) eine klare Absicht zur Datenstrukturierung von Anfang an erfordert. Die Investition in diese frühen Phasen bereitet Sie auf schnelle Erfolge vor.
Wenn Ihnen dieser Artikel gefallen hat, teilen Sie ihn bitte mit anderen und achten Sie auf SIEM-Grundlagen (Teil 2): Verwendung von Warnungen, Dashboards und Berichten effektiv. Wenn Ihnen dieser Artikel wirklich gefallen hat und Sie etwas Unterstützung zeigen möchten, können Sie unser Threat Detection Marketplace (kostenlose SIEM-Inhalte), unser ECS Premium Log Source Pack (Datenreiniger für Elastic) und Vorausschauende Wartung (löst die hier diskutierten Probleme der Datenerfassung) auschecken.


