Elastic für Sicherheitsanalysten. Teil 1: Strings durchsuchen.


Inhaltsverzeichnis:
Zweck:
Da Elastic seinen Einfluss im Bereich der Cybersicherheit durch die Geschwindigkeit und Skalierbarkeit ihrer Lösung ausbaut, erwarten wir mehr neue Elastic-Nutzer. Diese Nutzer werden sich Elastic mit einer Intuition nähern, die aus Erfahrungen mit anderen Plattformen und SIEMs entstanden ist. Oft wird diese Intuition nach einigen Suchen in Elastic direkt herausgefordert. Der Zweck dieser Serie ist es, Sicherheitsanalysten mit der Einzigartigkeit von Elastic vertraut zu machen. Dieser Beitrag bietet den Lesern eine Anleitung zum Erstellen geeigneter Suchen gegen Stringdaten in Elastic.Missverständnisse darüber, wie die analysierten Text und nicht analysierten Schlüsselwörter Datentypen die Suche nach stringbasierten Daten beeinflussen, führen zu irreführenden Ergebnissen. Wenn Sie diesen Beitrag lesen, sind Sie besser darauf vorbereitet, Suchen gegen Strings durchzuführen, die Ihren Analyseabsichten entsprechen.
Gliederung:
- Bevor wir loslegen
- Welchen Datentyp verwenden Sie?
- Zusammenfassung der Unterschiede
- Unterschied 1: Tokenisierung & Begriffe
- Unterschied 2: Groß- und Kleinschreibung
- Unterschied 3: Symbolübereinstimmung
Bevor Wir Loslegen:
Lucene
Dieser Blogbeitrag verwendet Lucene. KQL unterstützt noch keine regulären Ausdrücke, und wir benötigen diese.
Begriffe: Datentypen, Zuordnungen und Analysatoren:
Bei der Diskussion, wie Daten in Elasticsearch-Indizes gespeichert werden, muss man die Begriffe Zuordnungen, Datentypen und Analysatoren kennen.
- Datentyp – Der „Typ“, „der Datentyp“ oder „Datentyp“, als der ein Wert gespeichert/indexiert wird. Beispiele für Datentypen sind: String, Boolean, Integer und IP. Strings werden gespeichert/indexiert als „Text“ oder „Schlüsselwörter“ Datentyp.
- Zuordnung – Dies ist die Einstellung, die jedem Feld einen Datentyp zuweist (zuordnet). Zugänglich über die get mapping API. Wenn Sie die Zuordnung abrufen, wird Ihnen das Feld zurückgegeben, dem der Datentyp zugeordnet ist.
- Analysator – Bevor String-Daten gespeichert/indexiert werden, wird der Wert vorverarbeitet, um Speicherung und Suche zu optimieren. Analysatoren helfen, das Suchen gegen Strings schnell zu machen.
Wie Strings Gespeichert Werden:
Es gibt zwei primäre Datentypen für Strings: Schlüsselwörter and Text.
- Schlüsselwörter – Strings des Typs Schlüsselwörter werden als ihr Rohwert gespeichert. Kein Analysator wird angewendet.
- Text – Strings des Typs Text werden analysiert. Der Standard- und häufigste Analysator ist der Standard (Text) Analysator. In diesem Beitrag bezieht sich der Begriff „Text“ auf den Text Datentyp mit dem Standardanalysator. Es gibt andere Analysatoren und benutzerdefinierte Analysatoren sind möglich.
Welchen Datentyp verwenden Sie?
Es ist sehr wahrscheinlich, dass Ihre Elastic-Instanz beide Text and Schlüsselwörter Datentypen für Strings verwendet. Das Elastic Common Schema (ECS) und Winlogbeat verwenden hauptsächlich den Schlüsselwörter Datentyp.
Selbst wenn Sie ECS verwenden, können Administratoren Zuordnungen anpassen! Um sicher zu wissen, wie ein Feld zugeordnet ist, sollten Sie Ihre Elastic-Instanz abfragen. Dafür können Sie die get field mapping API oder die get mapping API verwenden. Es ist eine gute Praxis, sich über die neuesten Zuordnungen für Felder auf dem Laufenden zu halten, die Sie regelmäßig durchsuchen oder gegen die Sie Inhalte erstellt haben. Zuordnungen können sich ändern, während Feldnamen gleich bleiben können. Das heutige Schlüsselwörter Feld könnte morgen ein Text Feld sein.
Die bemerkenswerten Unterschiede zwischen Schlüsselwörter and Text sind im folgenden Abschnitt detailliert dargestellt. Zusätzlich wird jeder Unterschied, der sich auf die Suchergebnisse auswirkt, in einem eigenen Abschnitt betrachtet.
Zusammenfassung der Unterschiede
Wir erwarten nicht, dass Sie diesen Abschnitt lesen und sofort verstehen, warum die Typen sich so verhalten, wie sie es tun. Jeder der Unterschiede wird in einem eigenen Abschnitt vertieft. Jeder der Beispiele in den Tabellen ist ebenfalls in einer Tabelle innerhalb des Abschnitts platziert, der das Verhalten erklärt.
Unterschiede
Die folgende Tabelle bietet einen kurzen Überblick über die Hauptunterschiede in den Datentypen.
| Unterschied | Standard (Text) | Schlüsselwörter |
| Tokenisiert | In Begriffe unterteilt (tokenisiert), Originalwert verloren, aber schneller | Nicht tokenisiert, Originalwert erhalten |
| Groß- und Kleinschreibung | Nicht case-sensitiv, case-sensitive Abfragen sind nicht möglich | Case-sensitiv, case-insensitive Abfragen über Regex möglich |
| Symbole | Im Allgemeinen werden nicht alphanumerische Zeichen nicht gespeichert. Aber, behält nicht alphanumerische Zeichen in bestimmten Kontexten bei | Behält nicht alphanumerische Zeichen bei / Behält Symbole bei |
Unterschiede im Verhalten
Die folgende Tabelle bietet realistische Beispiele dafür, wie Typen das Suchverhalten beeinflussen.
| Beispielwert | Abfrage | Texttreffer | Schlüsselworttreffer |
| Powershell.exe –encoded TvqQAAMA | process.args:encoded | Yes | No |
| Powershell.exe –encoded TvqQAAMA | process.args:/.*[Ee][Nn][Cc][Oo][Dd][Ee][Dd].*/ | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:*Powershell.exe*Tvq* | No | Yes |
| TVqQAAMA | process.args:*TVqQAAMA* | Yes | Yes |
| TVqQAAMA | process.args:*tvqqaama* | Yes | No |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
| CmD.ExE | process.name:cmd.exe | Yes | No |
| CmD.ExE | process.name:/[Cc][Mm][Dd].[Ee][Xx][Ee]/ | Yes | Yes |
| \*$* | process.args:*\\*$* | No | Yes |
| \C$WindowsSystem32 | process.args:*C$\* | Yes | Yes |
_
Unterschied 1: Analysator, Tokenisierung & Begriffe
Unterschied
| Unterschied | Text (Standardanalysator) | Schlüsselwörter |
| Tokenisiert | In Begriffe unterteilt (tokenisiert) | Nicht analysiert, nicht tokenisiert. Originalwert erhalten. |
Warum…?
The Text Der Datentyp / Standardanalysator verwendet Tokenisierung, die einen String in Stücke (Tokens) aufteilt. Diese Tokens basieren auf Wortgrenzen (z.B.: ein Leerzeichen), Interpunktion und mehr.
Als Beispiel, wenn wir den folgenden String mit dem Standardanalysator tokenisieren:„searching for things with Elastic is straightforward“Die resultierenden Begriffe wären:„searching“ | „for“ | „thing“ | „with“ | „elastic“ | „is“ | „straightforward“Beachten Sie, dass alles auf Leerzeichen (Wortgrenzen) tokenisiert wurde, jetzt klein geschrieben ist und das „s“ von „things“ entfernt wurde.
Tokenisierung ermöglicht das Matching auf einzelne Begriffe ohne „contains“ oder Wildcards. Wenn wir zum Beispiel eine Suche nach „Elastic“ the Text Datentyp-String, der “searching for things with Elastic is straightforward” würde übereinstimmen. Dies unterscheidet sich von anderen SIEMs, die stark auf Wildcards oder ‚contains‘-Logik angewiesen sind.
Allerdings bricht die Tokenisierung bei Wildcards zwischen Begriffen ab. Zum Beispiel, „*searching*Elastic*“ würde nicht mit dem Standard-analysierten String „searching with Elastic is straightforward“ übereinstimmen.Hinweis: Sie können dies mit Nähe beheben, aber die Reihenfolge wird nicht beibehalten. Zum Beispiel, “searching Elastic“~1 würde mit „searching with Elastic“ und „Elastic with searching“ übereinstimmen.
Oftmals benötigen wir in der Sicherheit genaue Übereinstimmungen und die Möglichkeit, Wildcards zwischen Begriffen zu verwenden. Dies ist ein Grund, warum der Schlüsselwörter Datentyp zum De-facto-Datentyp in ECS geworden ist. Was Sie an Geschwindigkeit verlieren, gewinnen Sie an präziseren Suchmöglichkeiten.
Beispiele
| Beispielwert | Abfrage | Texttreffer | Schlüsselworttreffer |
| Powershell.exe –encoded | process.args:”Powershell.exe –encoded” | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:/.*[Ee][Nn][Cc][Oo][Dd][Ee][Dd].*/ | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:encoded | Yes | No |
| Powershell.exe –encoded TvqQAAMA | process.args:*Powershell.exe*encoded* | No | Yes |
_
Unterschied 2: Groß- und Kleinschreibung
Unterschied
| Unterschied | Text (Standardanalysator) | Schlüsselwörter |
| Groß- und Kleinschreibung | Wird vollständig in Kleinbuchstaben gespeichert und ist daher case-insensitive. Case-sensitive Abfragen sind nicht möglich. | Case-sensitiv. Case-insensitive Abfragen mit regulären Ausdrücken möglich. |
Warum…?
Probleme mit der Groß- und Kleinschreibung sind eine der Hauptursachen für Verwirrung im Verhalten von Elastic als Sicherheitsanalyst. Dies gilt insbesondere für den Schlüsselwörter Datentyp (Hallo ECS-Community). Ein einziges Zeichen mit falscher Groß- und Kleinschreibung in einem Log kann eine falsch erstellte Abfrage gegen die Schlüsselwörter Felder umgehen. Wenn ein Angreifer Teile von Daten kontrolliert, die in Schlüsselwörter (denken Sie an Windows 4688 & 4104 Ereignisse) gelangen, sollten Sie reguläre Ausdrücke verwenden, um eine Groß- und Kleinschreibungsunempfindlichkeit sicherzustellen!Darüber hinaus warnt Elastic Sie nicht, wenn ein Dokument knapp übersehen wurde, weil ein Zeichen mit falscher Groß- und Kleinschreibung verwendet wurde. Daher ist das Fehlen von Ergebnissen oder das Erhalten von mehr Ergebnissen als beabsichtigt eine Hauptursache für Verwirrung als Sicherheitsanalyst.
Hier ist ein einfaches Beispiel für eine Übereinstimmung gegen „PoWeRsHeLl“. Beachten Sie, dass es nur eines einzigen Zeichens mit falscher Groß- und Kleinschreibung bedarf, um zu verhindern, dass die Abfrage übereinstimmt.
| Beispielwert | Abfrage | Texttreffer | Schlüsselworttreffer |
| PoWeRsHeLl | process.args:PoWeRsHell | Yes | No |
| PoWeRsHeLl | process.args:PoWeRsHeLl | yes | yes |
| PoWeRsHeLl | process.args:/[Pp][Oo][Ww][Ee][Rr][Ss][Hh][Ee][Ll][Ll]/ | yes | Ja (stimmt mit allen Fällen überein) |
Für ein reales Kibana-Beispiel. In dem Bild unten wird im Feld „process.args“ des Typs nach der Zeichenfolge „windows“ abgefragt. Für einen ahnungslosen Analysten mag dies ausreichend erscheinen… 42 Ergebnisse wurden zurückgegeben. Wenn sie jedoch hofften, Dokumente zu erhalten, die „windows“ enthalten, wären sie falsch. Da die Suche case-sensitiv ist, wird „Windows“ nicht übereinstimmen. Schlüsselwörter type field “process.args” is queried for the string “windows”. To an unsuspecting analyst this may seem good enough… 42 results were returned. Well if they were hoping to obtain any document containing “windows” they would be wrong. As the search is case sensitive, therefore “Windows” would not match.
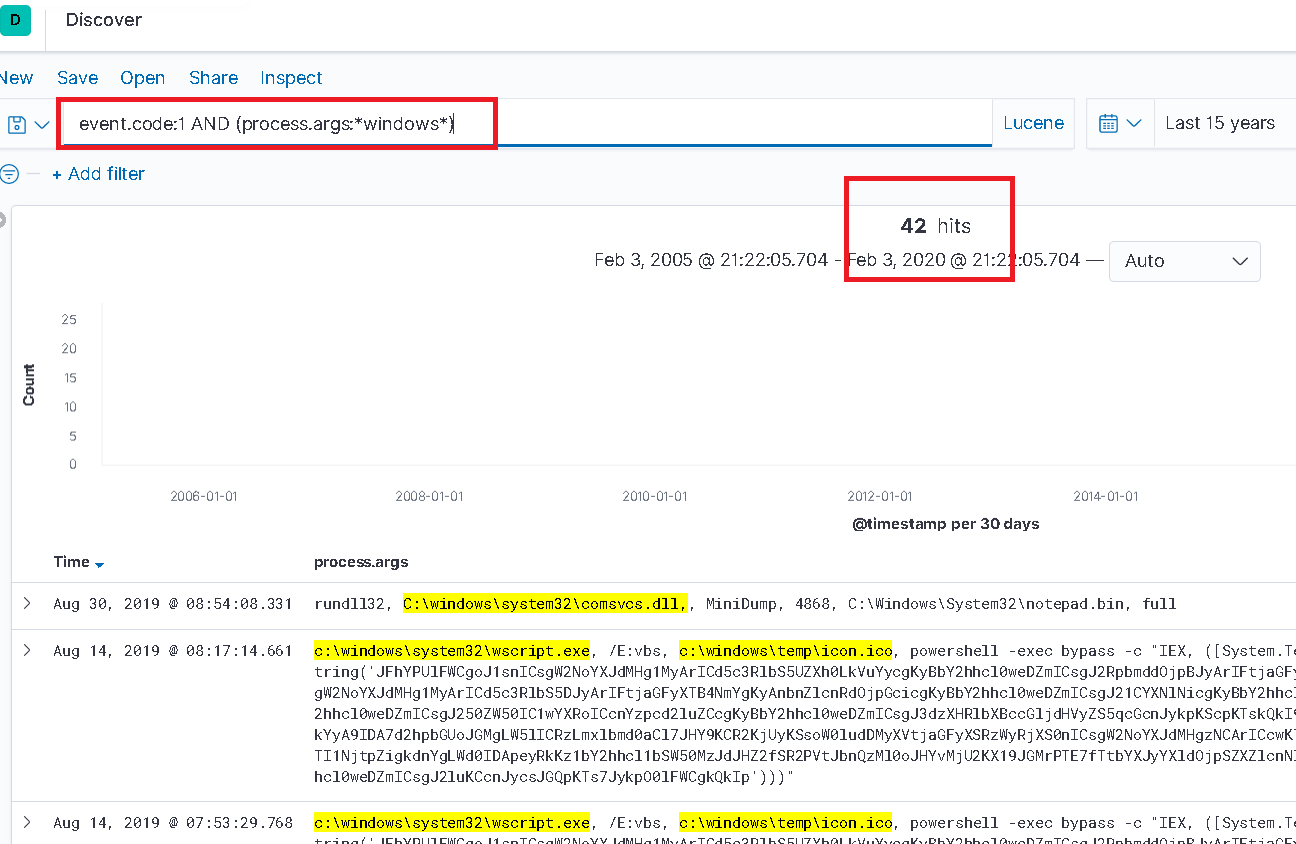
Begrenzte Ergebnisse aus case-sensitiver Suche
In der Abfrage unten, die einen regulären Ausdruck verwendet, um nach „windows“ zu suchen, werden entsprechend 567 Ergebnisse zurückgegeben, die zuvor „fehlten“!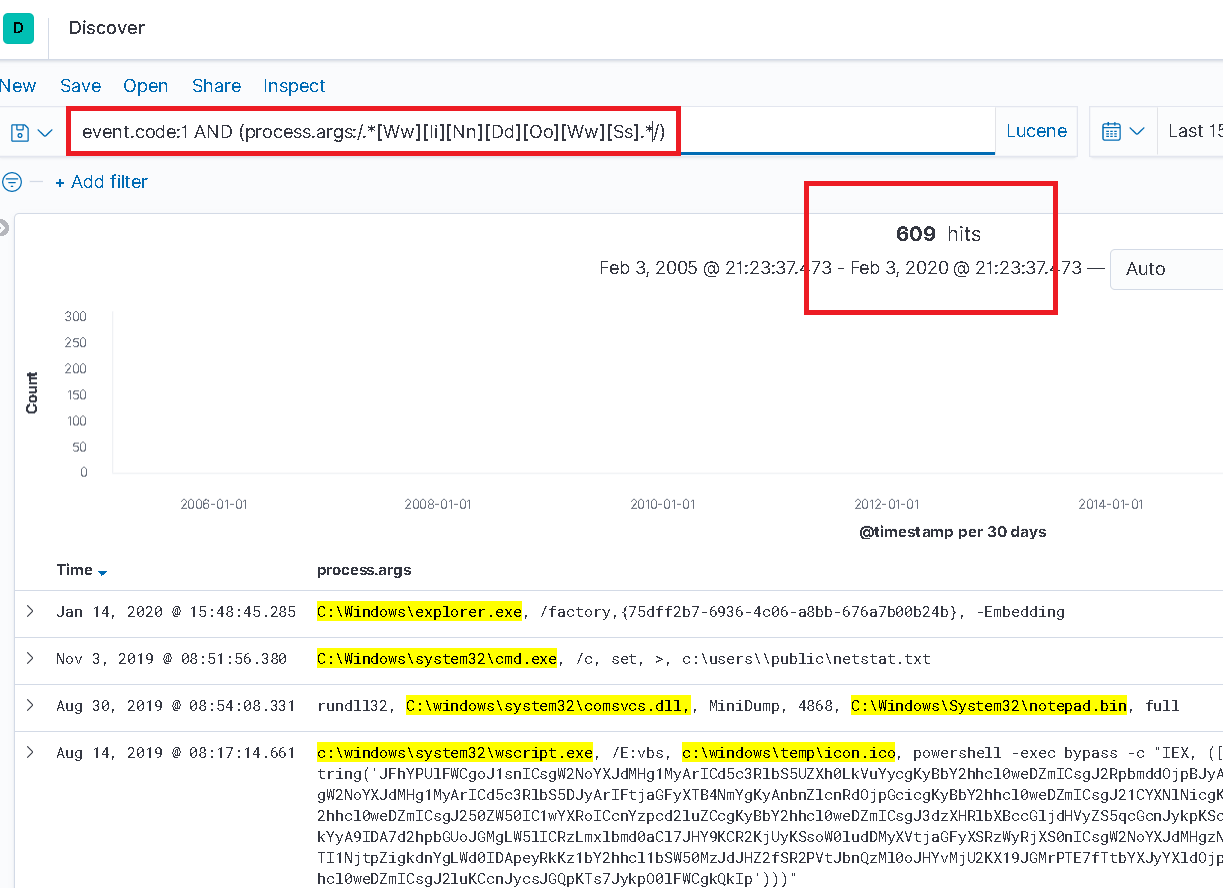
Maximale Ergebnisse
Hoffentlich ist nun klar, dass wenn wir mit dem Schlüsselwörter Typ suchen und keinen regulären Ausdruck verwenden, wir Varianten von „powershell“ verpassen werden, die über eine genaue Übereinstimmung hinausgehen. Es wird davon abgeraten, KQL (das kein Regex unterstützt) zu verwenden, um gegen vom Angreifer kontrollierte Daten zu matchen.Hinweis: Es gibt Anwendungsfälle, bei denen eine Groß- und Kleinschreibung in Schlüsselfeldern wie bei base64 gewünscht ist.Sie können jede Abfrage über Regex-Zeichensatzblöcke case-insensitive machen. Hier sind Beispiele:
| encoded | /[Ee][Nn][Cc][Oo][Dd][Ee][Dd]/ |
| cmd.exe | /[Cc][Mm][Dd].[Ee][Xx][Ee]/ |
| C:windowssystem32* | /[Cc]:\[Ww][Ii][Nn][Dd][Oo][Ww][Ss]\[Ss][Yy][Ss][Tt][Ee][Mm]32\.*/ |
Beispiele
| Beispielwert | Abfrage | Texttreffer | Schlüsselworttreffer |
| TVqQAAMA | process.args::*TVqQAAMA* | Yes | Yes |
| TVqQAAMA | process.args: *tvqqaama* | Yes | No |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
| CmD.ExE | process.name:cmd.exe | Yes | No |
| CmD.ExE | process.name:/[Cc][Mm][Dd].[Ee][Xx][Ee]/ | Yes | Yes |
_
Unterschied 3: Symbolübereinstimmung
Unterschied
| Unterschied | Text (Standardanalysator) | Schlüsselwörter |
| Symbole | Im Allgemeinen werden nicht alphanumerische Zeichen nicht gespeichert. Aber, behält nicht alphanumerische Zeichen in bestimmten Kontexten bei | Behält nicht alphanumerische Zeichen bei / Behält Symbole bei |
Warum?
Alle Symbole werden vom Schlüsselwörter Typ beibehalten, da das gesamte Feld genau so beibehalten wird, wie die Daten eingegeben werden (siehe Hinweis). Für den Standardanalysator gilt jedoch die allgemeine Regel, dass Symbole nicht beibehalten werden. Dies liegt daran, dass der Analysator für das Matching ganzer Wörter gemacht wurde und Symbole keine Wörter sind. Anders ausgedrückt, Symbole werden im Standardanalysator größtenteils nicht gespeichert. Also, Wenn Sie auf Symbole abzielen, verwenden Sie am besten den Schlüsselwörter Datentyp. Wenn Sie jedoch nur ein Textfeld haben und eine Gruppe von Symbolen übereinstimmen müssen, haben Sie Pech. Es gibt jedoch Kontexte, in denen Symbole im Standardanalysator beibehalten werden. Zum Beispiel werden Punkte in Begriffen wie „cmd.exe“ beibehalten. Die Autor:innen haben festgestellt, dass der einfachste Weg zu verstehen, wann Symbole im Standardanalysator beibehalten werden, darin besteht, einfach Testdaten in der Analyze-API auszuführen.
Beispiele
| Beispielwert | Abfrage | Texttreffer | Schlüsselworttreffer |
| \*$* | process.args:*\\*$* | No | Yes |
| \C$WindowsSystem32 | process.args:*C$\* | Yes | Yes |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
_
Fazit
Elastic ist ein leistungsstarkes Werkzeug. Es kann jedoch auch irreführend sein. Hoffentlich haben wir Ihnen ein wenig mehr Wissen und die Fähigkeit gegeben, sicher gegen stringbasierte Daten zu suchen.
Wenn Sie das Gefühl haben, dass Sie Hilfe beim Schreiben von Inhalten für Elastic benötigen, ist die Threat Detection Marketplace von SOC Prime voller Erkennungsinhalte, die mit unserer vorgeschlagenen Elastic-Konfiguration funktionieren.
Zukünftige Beiträge
Bleiben Sie dran für weitere Blogbeiträge, die die Grundlagen und nicht-so-hoch gestochenen Grundlagen der Nutzung von Elastic als Sicherheitsanalyst erkunden.
Zusätzliche Ressourcen für die Suche:
Diese Serie konzentriert sich auf die allgemeinen Schmerzpunkte für Analysten und vertieft sich nicht in das Thema der Syntax. Elastic bietet ausführliche Dokumentation zu ihrer Lucene-Syntax. Es gibt auch mehrere qualitativ hochwertige Community-Cheat-Sheets: insbesondere McAndres and Florian Roth und Thomas Patzke’s.
Meta:
Veröffentlicht – März 2020
Letzte Aktualisierung – 12. März
Autoren – Adam Swan (@acalarch) mit Hilfe von Nate Guagenti (@neu5ron)
Verwendete Elastic-Version: 7.5.2
Verwendete Logs in den Beispielen: https://github.com/sbousseaden/EVTX-ATTACK-SAMPLES


