Observability began as a visibility problem. Yet, today it is framed just as much as a control challenge because teams have to manage the floods of telemetry moving daily through the business environment. Most organizations already collect large volumes of logs, metrics, events, and traces. The issue now lies in managing tons of that data before it reaches expensive downstream tools. Gartner defines observability platforms as systems that ingest telemetry to help teams understand the health, performance, and behavior of applications, services, and infrastructure. That matters because when systems slow down or fail, the impact reaches far beyond the technical side, affecting revenue, customer sentiment, and brand perception.
This creates a familiar paradox. Complex environments require broad telemetry coverage, yet large data volumes can quickly become expensive and difficult to manage. When every signal is forwarded by default, useful insight gets mixed with duplication, low-value data, and rising storage and processing costs. Gartner reports observability spend rising around 20% year over year, with many organizations already spending more than $800,000 annually. The trend shows that by 2028, 80% of enterprises without observability cost controls will overspend by more than 50%.
The pressure is pushing teams to look for more control earlier in the flow. Observability pipelines answer that need by giving teams a practical way to filter, enrich, transform, and route data before it turns into noise, waste, and operational drag downstream.
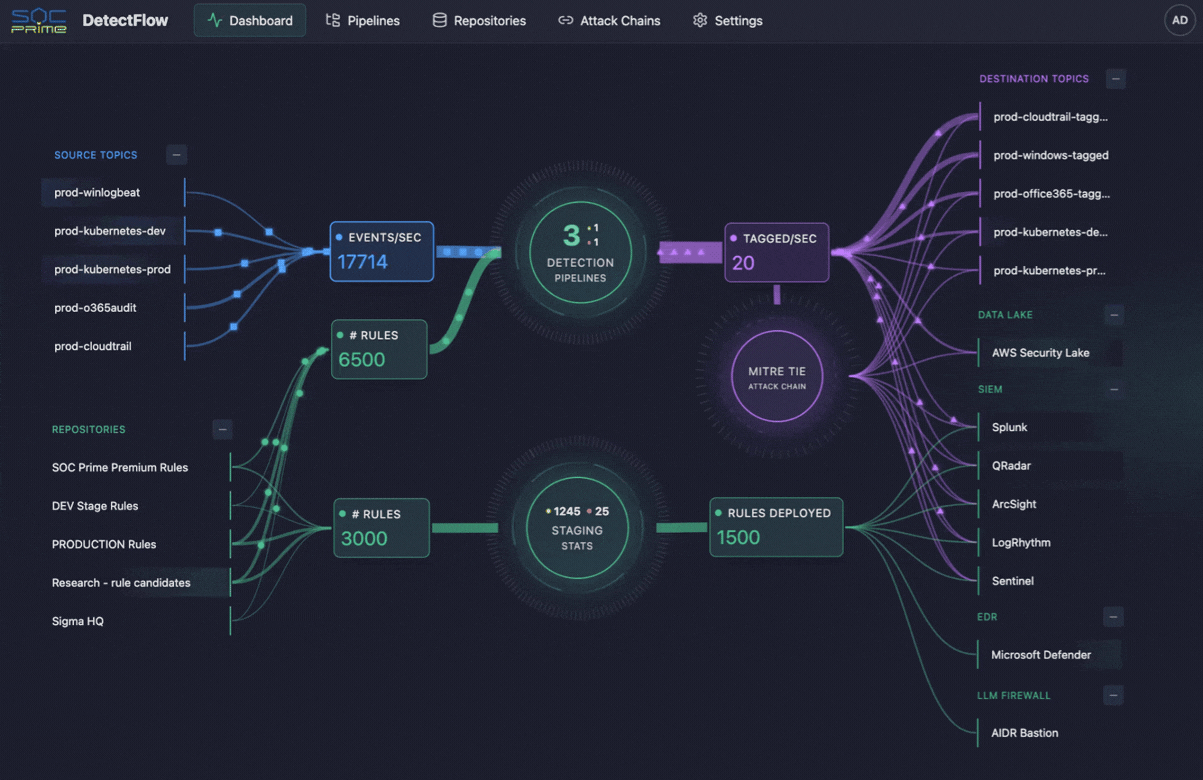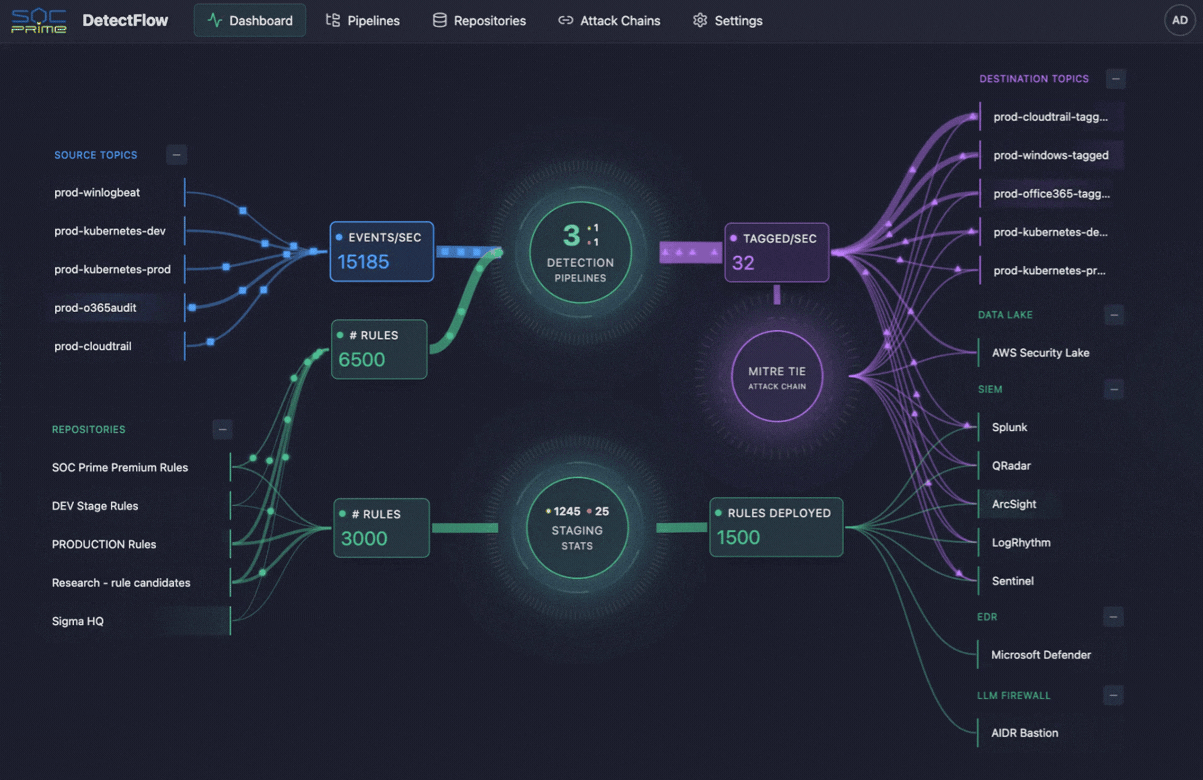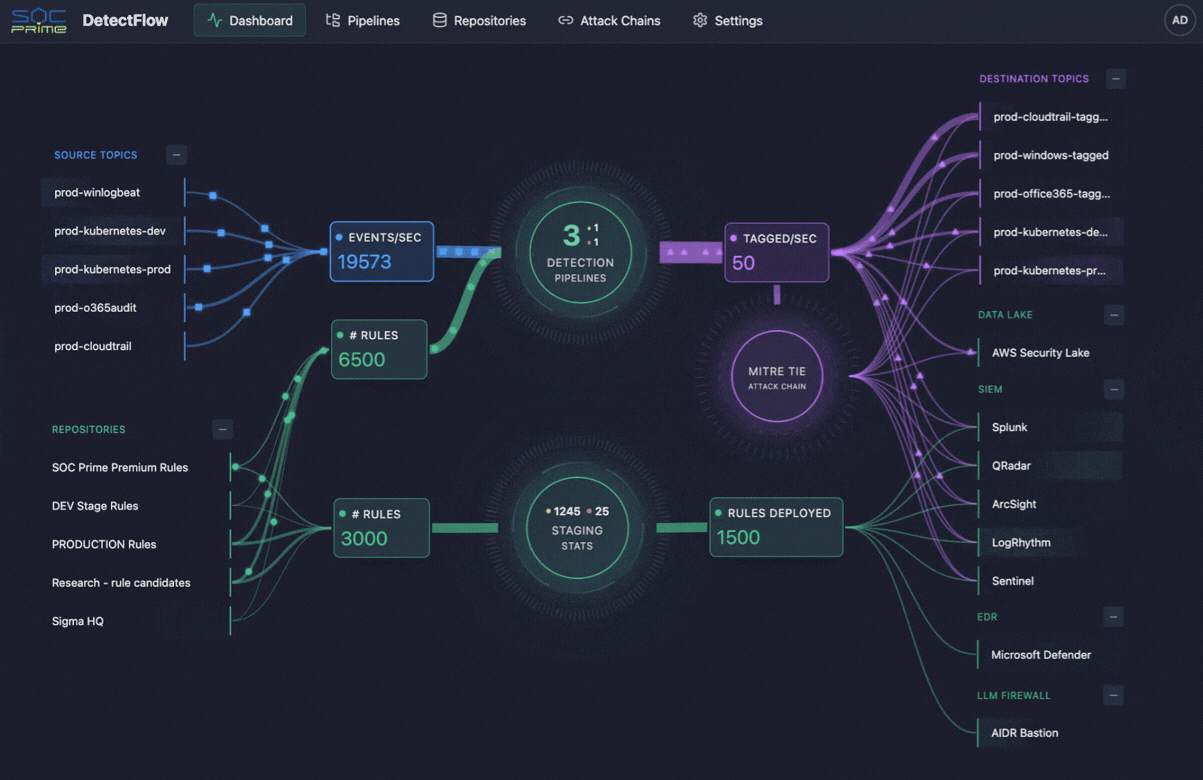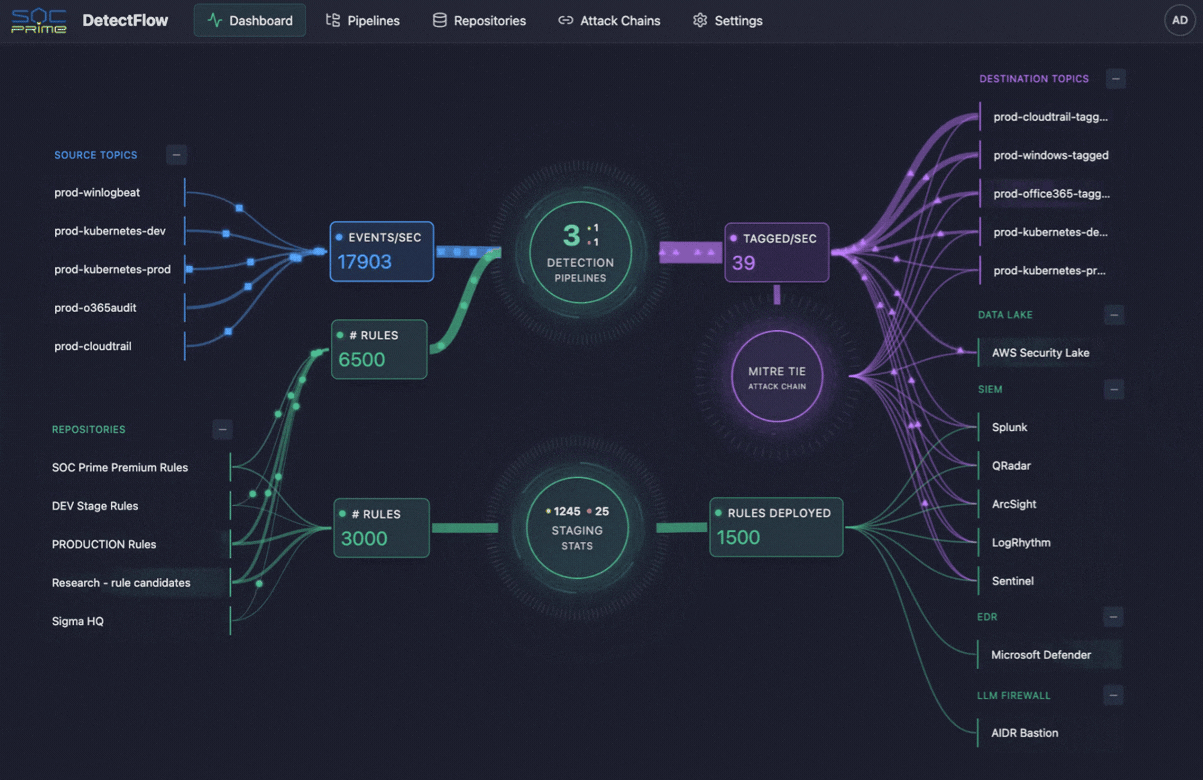
The same logic is starting to shape cybersecurity operations as well. This is where tools like SOC Prime’s DetectFlow enter the picture. DetectFlow moves the detection layer directly into the pipeline, enabling SOC teams to run tens of thousands of Sigma rules to live Kafka streams using Apache Flink, tagging, enriching, and chaining events at the pre-SIEM stage to scale without the usual vendor caps on speed, capacity, or cost.
What Is an Observability Pipeline?
An observability pipeline is the solution that moves telemetry from sources to destinations while performing tasks like transformation, enrichment, and aggregation. Specifically, it takes in logs, metrics, traces, and events, then prepares that data before it reaches monitoring platforms, SIEMs, data lakes, or long-term storage. Along the way, observability pipelines can filter noisy data, enrich records with context, aggregate high-volume streams, secure sensitive fields, and route each data type to the destination where it makes the most sense.
This becomes important as telemetry grows across microservices, containers, cloud services, and distributed systems. Without a pipeline, teams often forward everything by default, which increases cost, adds noise, and makes data handling harder to manage across multiple tools and environments.
Observability pipelines help solve several common challenges:
- Data overload. High telemetry volume makes it harder to separate useful signals from low-value data, especially when logs, metrics, and traces arrive from many different systems at once.
- Rising storage and processing costs. Sending all data to downstream platforms drives up ingest, indexing, and retention costs, even when much of that data adds little value.
- Noisy data. Duplicate, low-priority, or low-context telemetry can overwhelm the signals that actually matter for troubleshooting, security, and performance analysis.
- Compliance & security risks. Logs and telemetry streams may contain personal or regulated data, which increases compliance and privacy risks when it is forwarded or stored without proper masking or redaction.
- Complex Infrastructure. Teams often need to send different data sets to different destinations, such as monitoring tools, SIEMs, and lower-cost storage, which becomes difficult to manage without a central control plane.
- Migration and vendor flexibility. Pipelines make it easier to reshape and reroute telemetry for new tools or parallel destinations without rebuilding collection from scratch.
In simple terms, an observability pipeline gives teams more control over telemetry. It helps organizations keep the useful signals, improve context, and send each stream where it fits.
How Observability Pipelines Work
At a practical level, observability pipelines create a single flow for handling telemetry data. Instead of managing multiple handoffs between sources and destinations, teams can work through one control layer that prepares data for different operational and security use cases.
Collect
The first step is gathering data from across the organizational environment. That can include application logs, infrastructure metrics, cloud events, container data, and security records. Bringing those inputs into one pipeline gives teams a more consistent starting point and reduces the need for separate connections between every source and every tool.
Process
Once data enters the pipeline, it can be adjusted to match the needs of the business. Teams may standardize formats, enrich records with metadata, remove duplicate events, mask sensitive fields, or reduce unnecessary detail. This step helps make the data more usable, whether the goal is troubleshooting, compliance, long-term retention, or security analysis.
Route
After processing, the pipeline sends data to the right destination. High-priority records may go to a monitoring platform or SIEM for immediate visibility, while other data can be archived, stored in a data lake, or routed to lower-cost storage. This makes it easier to support different teams without forcing every system to handle the same data in the same way.
Benefits of Using Observability Pipeline
An observability pipeline helps teams to manage growing telemetry volumes, improve data quality, and control how information is used across operations and security. As environments become more distributed, that kind of control matters more for cost, performance, and faster decision-making.
Some of the main benefits include:
- Lower storage and processing costs. An observability pipeline helps reduce unnecessary spend by filtering low-value events, deduplicating records, and sending only the right data to high-cost platforms. This keeps teams from paying top price for data that adds little value.
- Better signal quality. When noisy or incomplete telemetry is cleaned up earlier, the data that reaches downstream tools becomes easier to search, analyze, and act on. That helps teams focus on what actually matters instead of sorting through clutter.
- Faster troubleshooting and investigations. Better-prepared data speeds up incident response. Operations teams can identify performance issues faster, while security teams can get cleaner and more relevant records into SIEMs and other detection tools without overwhelming analysts with noise.
- Stronger compliance and data protection. Logs and telemetry may contain sensitive or regulated information. A pipeline makes it easier to mask, redact, or route that data properly before it is stored or shared, which supports compliance and reduces risk.
- More flexibility across tools and teams. Different teams need different views of the same data. An observability pipeline makes it easier to route specific streams to monitoring platforms, data lakes, SIEMs, or lower-cost storage without rebuilding collection every time requirements change.
- Better scalability for modern environments. As infrastructure grows across cloud, containers, and distributed systems, pipelines help organizations scale telemetry handling in a more controlled and sustainable way.
In its essence, the value of an observability pipeline comes down to control. It helps teams cut waste, improve signal quality, support security and compliance, and make better use of telemetry across the business.
Observability Pipeline in the Cloud
Cloud environments make observability harder because they add more motion, more dependencies, and far more telemetry to manage. Microservices, containers, Kubernetes, and short-lived workloads all produce signals that change quickly and accumulate quickly. In Chronosphere’s cloud-native observability research summary, 87% of engineers said cloud-native architectures have made discovering and troubleshooting incidents more complex, and 96% said they feel stretched to their limits.
That complexity creates a practical problem for the business. Teams need broad visibility to understand what is happening across cloud services, applications, and infrastructure, but forwarding everything by default quickly becomes expensive and hard to manage. Experts describe the market shift as a move from volume to value, driven by rising telemetry costs, AI workloads, and the need for more disciplined visibility.
This is where observability pipelines become especially useful in the cloud. A pipeline gives teams a control layer between data sources and downstream tools, so they can filter noisy records, enrich important ones, and route each stream to the right destination. That means less waste in premium platforms, better-quality signals for troubleshooting, and more flexibility across monitoring, storage, and security tools. In cloud-native environments, that kind of control is no longer a nice extra.
The cloud angle also matters for cybersecurity. Security teams rely on the same cloud telemetry for threat detection, investigation, and compliance, but raw volume can overwhelm SIEMs and bury the events that matter. An observability pipeline helps earlier in the flow by reducing noise, improving context, and sending higher-value records to the right systems. That is also where SOC Prime’s DetectFlow fits naturally, moving detection closer to ingestion so teams can evaluate, enrich, and correlate events before they become downstream overload.
Observability Pipeline: A Smarter Layer for Security Operations
An observability pipeline gives teams something they increasingly need across modern environments: control before data turns into cost, noise, and slow decision-making. The more telemetry organizations collect, the more important it becomes to filter, enrich, transform, and route it with purpose. That makes observability pipelines useful far beyond monitoring alone. They help improve data quality, keep downstream platforms efficient, and create a stronger foundation for both operations and security.
Notably, security teams face the same telemetry problem, but with higher stakes. SIEMs have practical limits, rule counts do not scale forever, and too much raw data can put enourmous burned onto security analysis. This is where DetectFlow adds a meaningful value layer, extending observability pipeline logic into threat detection by moving detection closer to the ingestion layer.
DetectFlow runs tens of thousands of Sigma detections on live Kafka streams using Apache Flink, correlates events across multiple log sources at the pre-SIEM stage, and uses Flink Agent plus active threat context for AI-powered analysis. In practice, that means SOC teams can reduce noise earlier, surface attack chains faster, and improve investigative clarity before downstream tools get overwhelmed.