Noções Básicas de Caça a Ameaças: Obtendo o Manual

Índice:
O propósito deste blog é explicar a necessidade de métodos de análise manual (não baseados em alertas) na caça de ameaças. Um exemplo de análise manual eficaz por meio de agregações/contagem de pilhas é fornecido.
A Automação é Necessária
A automação é absolutamente crítica e, como caçadores de ameaças, devemos automatizar onde for possível o máximo possível.
No entanto, a automação é construída com base em suposições sobre dados ou sobre como a automação será eficaz em um determinado ambiente. Muitas vezes, essas suposições são feitas pelo caçador de ameaças por outros analistas, engenheiros, proprietários de sistemas, etc. Como exemplo, uma suposição comum é a lista de permissões de eventos de criação de processos do System Center Configuration Monitor (SCCM) ou outros produtos de gerenciamento de endpoint em detecções baseadas em alertas. Outro exemplo é o filtro de logs não utilizados pelos engenheiros de SIEM para economizar recursos. Os atacantes estão cada vez mais conscientes de identificar essas suposições e se manterem escondidos dentro delas. Por exemplo, ferramentas foram criadas para identificar fraquezas na configuração do sysmon de um sistema [1].
Ao retirar e inspecionar as camadas de suposições, os caçadores de ameaças podem ter sucesso ao identificar lacunas na visibilidade e caçar nessas lacunas para descobrir uma violação. Este post no blog foca em remover algumas dessas suposições usando agregações para revisar manualmente dados interessantes de forma eficiente.
Abordagens Manuais são Necessárias
Talvez o principal princípio da caça de ameaças seja “Assumir Comprometimento”. Responder a um comprometimento (quase) sempre envolve análise e intervenção humana manual, especialmente durante o escopo. Escopar de forma eficaz não envolve apenas a revisão de alertas. Envolve a análise manual de hosts comprometidos conhecidos em busca de indicadores e comportamentos que podem ser pesquisados no restante do ambiente. Portanto, como caçadores de ameaças, se estamos “Assumindo Comprometimento”, a análise manual é intrinsecamente necessária.
Outra forma de ver isso é observar que ao revisar apenas dados baseados em alertas, assumimos que um atacante bem-sucedido acionará pelo menos uma regra/alerta em nosso ambiente, suficientemente claro e acionável para que possamos tomar uma decisão que resulte na identificação do comprometimento.
Dito isso, os caçadores de ameaças não devem sobrecarregar-se com a análise manual de cada log para cada fonte de dados no ambiente. Em vez disso, devemos identificar uma maneira de colocar nossos cérebros revisando dados relevantes e tomando decisões de forma tão eficaz quanto possível.
Retirar a lógica que estamos usando para alertar em eventos e agregar nos campos e contextos que usamos em nossos alertas é um exemplo de análise manual eficaz para a maioria dos ambientes.
Agregação como um Exemplo (Contagem de Pilhas)
Um dos métodos mais simples e eficazes para abordagens de caça manual é agregar em campos interessantes/acessíveis de coleta de dados passivos em um contexto específico.
Se você já usou tabelas dinâmicas do Microsoft Office, o comando stats do Splunk ou o comando “top” do Arcsight, você está familiarizado com este conceito.Nota: Esta técnica também é comumente chamada de contagem de pilhas, empilhamento de dados, empilhamento, ou tabelas dinâmicas :). Acredito que os caçadores novatos estarão mais familiarizados com o conceito de agregação, então uso esse termo aqui. A Fireeye parece ser a primeira a publicar esse conceito no contexto de caça a ameaças [2].
Nota: Dados passivos são uma fonte de dados que informam sobre um evento, seja ele relevante para segurança ou não. Por exemplo, uma fonte de dados passiva pode indicar que um processo foi criado, uma conexão de rede foi estabelecida, um arquivo foi lido/escrito, etc. Logs de host, como os Logs de Eventos do Windows, são grandes exemplos de uma fonte de dados passiva. Fontes de dados passivos são uma parte importante da estrutura para a maioria dos programas de caça a ameaças.Como exemplo, a Imagem 1 mostra parte de uma agregação de todos os eventos de conexão de rede sysmon com porta de destino 22 (SSH) em um ambiente durante 30 dias. Um caçador de ameaças pode usar essa agregação para ‘caçar’ processos que normalmente não seriam associados a conexões pela porta 22.
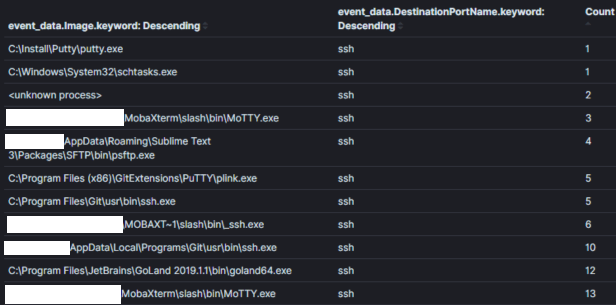 Imagem 1: Agregação Simples no Kibana
Imagem 1: Agregação Simples no Kibana
Imagem Um:
Campo de Agregação: Nome do ProcessoContexto: Processos usando a porta 22 em 30 diasResultados: 120Tempo para Análise: < 1 minO contexto é rei na caça com agregações e contém a intenção da sua hipótese de caça. O contexto de uma agregação geralmente é definido na consulta subjacente e exposto ao analista por meio dos campos que agregamos e observamos. Na Imagem 1, o contexto de “Processos usando a porta 22” é convertido para a lógica da consulta (symon_eid == 3 AND porta de destino == 22) e ao agregar/exibir o campo contendo nomes de processos.
É importante encontrar um equilíbrio entre quão estreito ou amplo é o contexto dentro de uma agregação. Como exemplo, na Imagem 2, ampliei o contexto da Imagem anterior para retornar todos os processos com conexões de rede. É possível encontrar algo malicioso neste contexto, no entanto, será mais difícil tomar decisões sobre os dados, a menos que haja um nome de processo obviamente incomum ou um processo que nunca teria realmente atividade de rede (o que é cada vez mais raro).Imagem 2:
Campo de Agregação: Nome do ProcessoContexto: Processos com conexões de redeResultados: 1000+Tempo para Análise: 1 min
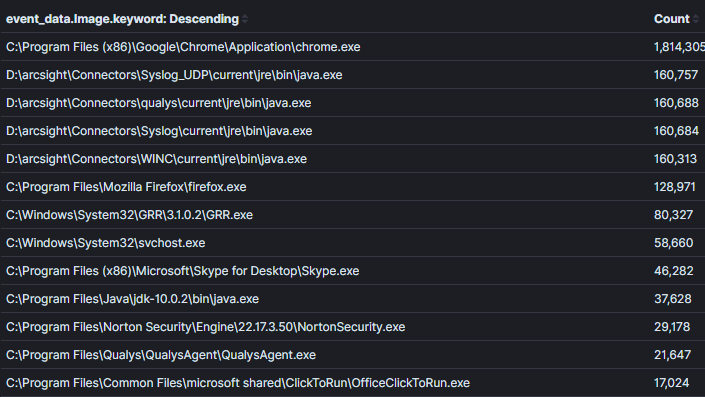 Imagem 2: Uma agregação menos eficaz sem contexto suficientePor fim, as agregações tornam-se menos eficazes quando campos que não serão usados para tomar decisões são agregados. Na Imagem 3, adicionei o campo “id do processo” à nossa última agregação. Saber o ID do processo pode ser útil quando identificamos um processo incomum, no entanto, ele cria uma entrada duplicada para cada combinação única de nome e id de processo. No exemplo prático, os resultados mais do que quadruplicaram e muitos nomes de processos foram duplicados. É importante agregar em campos que permitem tomar decisões. Informações que podem ser necessárias para identificar um host ou usuário específico para triagem devem ser identificadas usando uma consulta adicional com contexto estreito. No exemplo da imagem 1, se quisermos identificar quem estava usando o putty para SSH, podemos usar a lógica (process_name==”*putty.exe” AND sysmon_eid==3). Na minha opinião, este é um lugar onde o Kibana supera outras ferramentas de análise que usei porque a interligação entre consultas e dashboards é altamente eficiente por meio do seu sistema de filtros fixáveis [4].
Imagem 2: Uma agregação menos eficaz sem contexto suficientePor fim, as agregações tornam-se menos eficazes quando campos que não serão usados para tomar decisões são agregados. Na Imagem 3, adicionei o campo “id do processo” à nossa última agregação. Saber o ID do processo pode ser útil quando identificamos um processo incomum, no entanto, ele cria uma entrada duplicada para cada combinação única de nome e id de processo. No exemplo prático, os resultados mais do que quadruplicaram e muitos nomes de processos foram duplicados. É importante agregar em campos que permitem tomar decisões. Informações que podem ser necessárias para identificar um host ou usuário específico para triagem devem ser identificadas usando uma consulta adicional com contexto estreito. No exemplo da imagem 1, se quisermos identificar quem estava usando o putty para SSH, podemos usar a lógica (process_name==”*putty.exe” AND sysmon_eid==3). Na minha opinião, este é um lugar onde o Kibana supera outras ferramentas de análise que usei porque a interligação entre consultas e dashboards é altamente eficiente por meio do seu sistema de filtros fixáveis [4].
Imagem 3:
Campo de Agregação: Nome do Processo + ID do ProcessoContexto: Processos com conexões de redeResultados: 1000+Tempo para Análise: 10 min
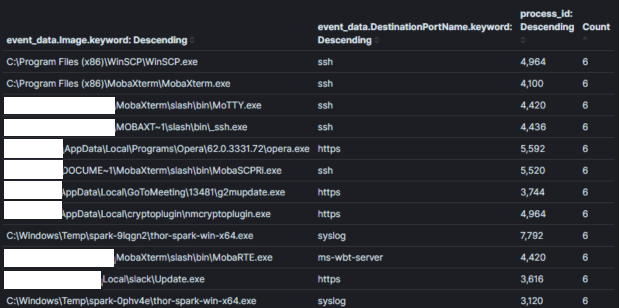 Imagem 3: Uma agregação menos eficaz com campos não contextuais
Imagem 3: Uma agregação menos eficaz com campos não contextuais
Nota: Em certos sistemas, como o Kibana do Elasticsearch, é fácil alternar de uma tabela de dados para outra usando seus dashboards. Caso contrário, assim que você identificar uma agregação interessante, um analista normalmente passará a revisar o(s) host(s) ou conta(s) que foram observados realizando o comportamento interessante.
Nota: Você deve estar ciente da armadilha da detecção de outliers. Não confie no conceito de “comum é bom e incomum é ruim” em agregações/contagem de pilhas. Isso não é necessariamente verdade, pois comprometimentos geralmente envolvem várias máquinas e os adversários podem tentar aproveitar essa suposição para criar ruído e parecer normal. Além disso, existem softwares e casos de uso de nicho em quase todos os ambientes. É fácil se envolver na triagem de cada pilha “menos comum” e perder tempo identificando falsos positivos. Conhecer o ambiente antes do comprometimento e aguçar seus instintos sobre o comportamento dos atores de ameaças [3] ajudará aqui.
Mas será que escala?
A análise manual de logs não escala tão bem quanto o alerta, pois um analista tipicamente observará um único contexto por vez. Por exemplo, revisar uma única agregação com dezenas ou até centenas de milhares de resultados é comum. O tempo mais longo que você gostaria de se ver revisando uma agregação é provavelmente de 10 minutos. Se como caçador de ameaças você se encontra sobrecarregado, pode tentar estreitar o contexto. Por exemplo, você pode dividir um ambiente de 20.000 hosts em dois ambientes de 10.000 hosts com a lógica de consulta que separa hosts por seus nomes. Alternativamente, você pode identificar ativos/críticas que contenham os “tesouros” ou “chaves do reino” e realizar análise manual nesses.
É possível criar conteúdo, revisar alertas e triagem de hosts com eficiência para ter tempo para mais técnicas manuais de caça a ameaças.
O conteúdo de SIEM disponível no TDM da SOC Prime [5] é rico em conteúdo que pode ser completamente automatizado como alertas, bem como conteúdo para habilitar abordagens mais manuais de caça a ameaças.
Recursos e Agradecimentos ao trabalho anterior:
[1] https://github.com/mkorman90/sysmon-config-bypass-finder
[2] https://www.fireeye.com/blog/threat-research/2012/11/indepth-data-stacking.html
[3] https://socprime.com/blog/warming-up-using-attck-for-self-advancement/
[4] https://www.elastic.co/guide/en/kibana/current/field-filter.html
[5] https://tdm.socprime.com/login/


