위협 헌팅 기본: 수동으로 접근하기

목차:
이 블로그의 목적은 위협 사냥에서 수동(경고 기반이 아닌) 분석 방법의 필요성을 설명하는 것입니다. 집계/스택 카운팅을 통한 효과적인 수동 분석의 예가 제공됩니다.
자동화는 필수적이다
자동화는 절대적으로 중요하며 위협 사냥꾼으로서 가능한 한 최대한 자동화해야 합니다.
하지만 자동화는 데이터에 대한 가정이나 주어진 환경에서 자동화가 효과적일지에 대한 가정에 기반하여 구축됩니다. 많은 경우 이러한 가정은 다른 분석가, 엔지니어, 시스템 소유자 등에 의해 위협 사냥꾼에게 전달됩니다. 예를 들어, 일반적인 가정은 경고 기반 탐지에서 시스템 센터 구성 관리자(SCCM) 또는 다른 엔드포인트 관리 제품의 프로세스 생성 이벤트를 화이트리스트화하는 것입니다. 또 다른 예로는 SIEM 엔지니어들이 리소스를 절약하기 위해 사용하지 않는 로그를 필터링하는 것이 있습니다. 공격자들은 점점 이러한 가정을 인식하고 그 안에 숨으려고 합니다. 예를 들어, 시스템의 sysmon 구성에서의 약점을 식별하기 위한 도구들이 작성되었습니다 [1].
가정의 레이어를 벗겨내고 점검함으로써 위협 사냥꾼은 시야의 격차를 식별하고 이러한 격차에서 사냥을 진행하여 타협을 발견할 수 있습니다. 이 블로그 게시물은 흥미로운 데이터를 수동으로 효율적으로 검토하기 위해 집계를 사용하여 이러한 가정을 일부 제거하는 데 초점을 맞추고 있습니다.
수동 접근법이 필요하다
아마도 지배적인 위협 사냥 전제는 “타협 가정”일 것입니다. 타협에 대응하는 것은 거의 항상 수동적인 인간 분석과 개입이 필요합니다, 특히 범위 결정 동안. 효과적인 범위 결정은 경고를 검토하는 것만 포함하지 않습니다. 효과적인 범위 결정은 나머지 환경에서도 검색할 수 있는 지표와 행동을 위해 알려진 타협된 호스트에 대한 수동 분석을 포함합니다. 따라서 우리는 “타협 가정”을 하고 있다면 수동 분석은 필연적으로 필요합니다. 이를 보는 또 다른 방법은 경고 기반 데이터만 검토함으로써 우리가 가정하는 것은 성공적인 공격자가 우리 환경 내에서 최소한 하나의 규칙/경고를 트리거할 것이고, 그 경고는 우리가 타협을 식별하는 결정을 내릴 수 있을 만큼 명확하고 실행 가능할 것이라는 가정입니다.
그렇다고 해서 위협 사냥꾼이 환경 내의 모든 데이터 소스에 대한 로그를 일일이 수동 분석하는 것은 아닙니다. 대신 관련 데이터를 검토하고 가능한 한 효과적으로 결정을 내릴 수 있는 방법을 식별해야 합니다.
이벤트에 대한 경고 논리를 벗겨보고 경고에 사용하는 필드와 컨텍스트에 대한 집계를 하는 것이 대부분의 환경에서 효과적인 수동 분석의 예입니다.
집계 예시 (스택 카운팅)
수동 사냥 접근법에 대한 가장 간단하고 효과적인 방법 중 하나는 특정 컨텍스트에서 수집된 수동 데이터 필드에 대한 집계를 하는 것입니다.
Microsoft Office의 피벗 테이블, Splunk의 stats 명령, 또는 Arcsight의 “top” 명령을 사용해 본 적이 있다면 이 개념에 익숙할 것입니다.비고: 이 기술은 스택 카운팅, 데이터 스택, 스태킹, 또는 피벗 테이블이라고도 흔히 불립니다. 초보 사냥꾼들이 집계라는 개념에 더 익숙할 것이라고 생각하여 여기에서는 그 용어를 사용합니다. Fireeye는 위협 사냥의 맥락에서 이 개념을 처음 출판한 것으로 보입니다 [2].
비고: 수동 데이터는 보안 관련 여부에 관계없이 이벤트에 대해 알려주는 데이터 소스입니다. 예를 들어, 수동 데이터 소스는 프로세스가 생성되었다거나 네트워크 연결이 이루어졌으며 파일이 읽기/쓰기되었을 때 알려줄 수 있습니다. Windows 이벤트 로그와 같은 호스트 로그는 수동 데이터 소스의 훌륭한 예입니다. 수동 데이터 소스는 대부분의 위협 사냥 프로그램의 중추적인 부분입니다.예를 들어, 이미지 1은 환경 내에서 30일 동안 목적지 포트 22(SSH)로의 모든 sysmon 네트워크 연결 이벤트의 집계 일부를 보여줍니다. 위협 사냥꾼은 보통 22번 포트와 연결되지 않을 프로세스를 ‘사냥’하기 위해 이 집계를 사용할 수 있습니다.
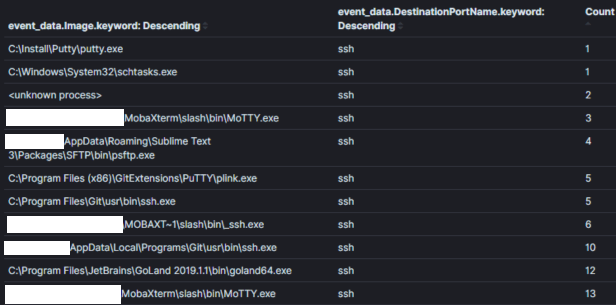 이미지 1: Kibana에서의 간단한 집계
이미지 1: Kibana에서의 간단한 집계
이미지 원:
집계 필드: 프로세스 이름컨텍스트: 30일 이내에 포트 22를 사용하는 프로세스결과: 120분석 시간: < 1 분집계를 통한 사냥에서 컨텍스트는 킹이며, 이는 사냥 가설의 의도를 포함합니다. 집계의 컨텍스트는 일반적으로 기본 쿼리에서 설정되며 우리가 집계하고 관찰하는 필드를 통해 분석가에게 노출됩니다. 이미지 1에서 “포트 22를 사용하는 프로세스”의 컨텍스트는 쿼리 논리 (symon_eid == 3 AND 목적지 포트 == 22)로 변환되고, 프로세스 이름을 포함하는 필드를 집계/디스플레이함으로써 이루어집니다.
집계 내에서 컨텍스트의 폭이 좁거나 넓은 것 사이의 균형을 맞추는 것이 중요합니다. 예를 들어, 이미지 2에서 이전 이미지와 비교하여 네트워크 연결이 있는 모든 프로세스를 반환하도록 컨텍스트를 확장했습니다. 이 컨텍스트에서는 악의를 발견할 수 있지만, 명백하게 비정상적인 프로세스 이름이나 실제로는 네트워크 활동이 없는 프로세스가 없는 한 데이터에 대한 결정을 내리는 것이 더 어려워질 것입니다.이미지 2:
집계 필드: 프로세스 이름컨텍스트: 네트워크 연결이 있는 프로세스결과: 1000+분석 시간: 1 분
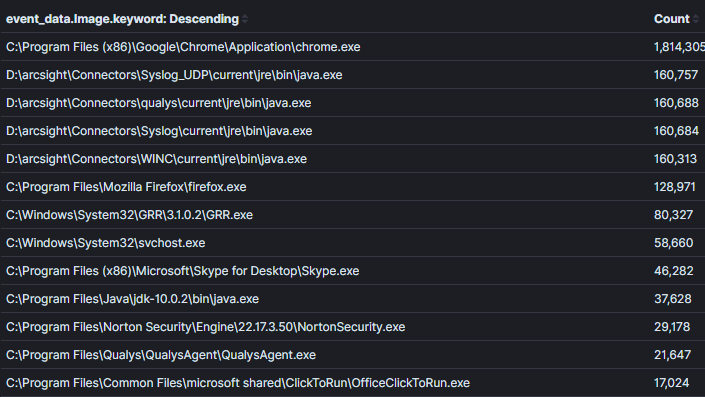 이미지 2: 컨텍스트가 부족한 덜 효과적인 집계결국, 의사결정에 사용되지 않을 필드가 집계될 경우 집계는 덜 효과적이 됩니다. 이미지 3에서는 마지막 집계에 ‘프로세스 id’ 필드를 추가했습니다. 프로세스 ID를 아는 것은 비정상적인 프로세스를 식별한 후 유용할 수 있지만, 이렇게 하면 각 고유 프로세스 이름과 ID 조합에 대해 중복 항목이 생성됩니다. 진행 중인 예제의 결과는 4배 이상 증가하였고, 많은 프로세스 이름이 중복되었습니다. 결정을 내릴 수 있는 필드에 대한 집계가 중요합니다. 특정 호스트나 사용자 식별에 필요한 정보는 컨텍스트가 좁은 추가 쿼리를 사용하여 식별해야 합니다. 이미지 1의 예를 들면 SSH에 putty를 사용하는 사용자를 식별하려면 (process_name==”*putty.exe” AND sysmon_eid==3) 논리를 사용할 수 있습니다. 개인적으로 Kibana가 사용해본 다른 분석 도구보다 뛰어나다고 생각하는 부분으로, 그들의 핀 가능한 필터링 시스템을 통해 쿼리와 대시보드 간에 피벗팅이 매우 효율적입니다 [4].
이미지 2: 컨텍스트가 부족한 덜 효과적인 집계결국, 의사결정에 사용되지 않을 필드가 집계될 경우 집계는 덜 효과적이 됩니다. 이미지 3에서는 마지막 집계에 ‘프로세스 id’ 필드를 추가했습니다. 프로세스 ID를 아는 것은 비정상적인 프로세스를 식별한 후 유용할 수 있지만, 이렇게 하면 각 고유 프로세스 이름과 ID 조합에 대해 중복 항목이 생성됩니다. 진행 중인 예제의 결과는 4배 이상 증가하였고, 많은 프로세스 이름이 중복되었습니다. 결정을 내릴 수 있는 필드에 대한 집계가 중요합니다. 특정 호스트나 사용자 식별에 필요한 정보는 컨텍스트가 좁은 추가 쿼리를 사용하여 식별해야 합니다. 이미지 1의 예를 들면 SSH에 putty를 사용하는 사용자를 식별하려면 (process_name==”*putty.exe” AND sysmon_eid==3) 논리를 사용할 수 있습니다. 개인적으로 Kibana가 사용해본 다른 분석 도구보다 뛰어나다고 생각하는 부분으로, 그들의 핀 가능한 필터링 시스템을 통해 쿼리와 대시보드 간에 피벗팅이 매우 효율적입니다 [4].
이미지 3:
집계 필드: 프로세스 이름 + 프로세스 ID컨텍스트: 네트워크 연결이 있는 프로세스결과: 1000+분석 시간: 10 분
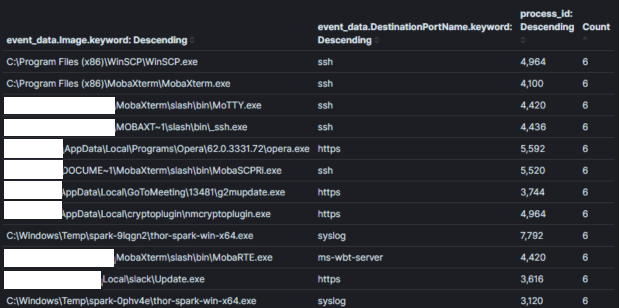 이미지 3: 비 컨텍스트 필드가 있는 덜 효과적인 집계
이미지 3: 비 컨텍스트 필드가 있는 덜 효과적인 집계
비고: elasticsearch의 Kibana와 같은 시스템에서는 대시보드를 사용하여 한 데이터 테이블에서 다른 테이블로 쉽게 피벗할 수 있습니다. 그렇지 않으면, 흥미로운 집계를 식별한 후에는 분석가가 흥미로운 행동을 수행한 호스트 또는 계정을 검토하는 데 전환할 것입니다.
비고: 이상치 탐지의 함정에 유의해야 합니다. 집계/스택 카운팅에서 “일반적이면 좋고, 비정상적이면 나쁘다”는 개념에 의존하지 마십시오. 이것은 반드시 사실이 아니며, 타협은 일반적으로 여러 대의 머신을 포함하고 적들은 소음을 만들어 일반적으로 보이게 하려고 할 수 있습니다. 또한 거의 모든 환경에 틈새 소프트웨어와 사용 사례가 존재합니다. 모든 “가장 적은 공통” 스택을 조사하며 거짓 양성을 식별하는데 시간을 낭비하기 쉽습니다. 타협 전 환경을 알고 위협 주체 행동에 대한 직감을 연마하면 도움이 됩니다 [3].
하지만 이것이 확장되는가?
로그의 수동 분석은 경고만큼 잘 확장되지 않으며, 분석가는 일반적으로 한 번에 단일 컨텍스트만 관찰합니다. 예를 들어, 수만에서 수십만 개의 결과가 있는 단일 집계를 검토하는 것이 일반적입니다. 집계를 검토하는데 가장 오래 시간을 보내고 싶어하는 시간은 아마도 10분일 것입니다. 위협 사냥꾼으로서 압도감을 느낀다면 컨텍스트를 좁혀볼 수 있습니다. 예를 들어, 20,000대 호스트 환경을 두 개의 10,000대 호스트 환경으로 쿼리 논리를 사용하여 이름으로 호스트를 구분하여 나눌 수 있습니다. 또는 ‘황금 덩어리’ 또는 ‘열쇠’를 포함하는 주요 자산/계정을 식별하고 수동 분석을 수행할 수 있습니다.
콘텐츠를 생성하고, 경고를 검토하며, 호스트를 효율적으로 조사하여 더 많은 수동 위협 사냥 기법에 시간을 쓸 수 있습니다.
SOC Prime의 TDM [5]에서 제공되는 SIEM 콘텐츠는 경고로 완전히 자동화될 수 있는 콘텐츠와 위협 사냥에 대한 더 수동적인 접근을 가능하게 하는 콘텐츠로 풍부합니다.
이전에 작업한 리소스 및 샤우트 아웃:
[1] https://github.com/mkorman90/sysmon-config-bypass-finder
[2] https://www.fireeye.com/blog/threat-research/2012/11/indepth-data-stacking.html
[3] https://socprime.com/blog/warming-up-using-attck-for-self-advancement/
[4] https://www.elastic.co/guide/en/kibana/current/field-filter.html
[5] https://tdm.socprime.com/login/


