보안 팀은 복잡한 데이터 환경에서 위협을 탐지하기 위해 더 빠르고 유연한 방법이 필요합니다. 대량의 데이터 스트림은 여러 도구에 걸쳐 운영이 분산될 때 탐지를 어렵게 하며, 사건 대응의 민첩성이 제한되고 대용량 데이터 세트를 관리하는 데 비용이 많이 듭니다.
Confluent Sigma는 탐지 로직을 SIEM에서 스트림 처리 계층으로 이동시켜 Shift-Left 위협 탐지 전략을 가능하게 함으로써 이러한 과제를 해결합니다. 이를 통해 보안 팀은 데이터가 정규화, 인덱싱, 저장되기 전에 위협을 원천에 더 가깝게 탐지하고 공격이 진행 중일 때 높은 정확도의 신호에 대응할 수 있습니다.
Confluent Sigma는 Kafka Streams 를 사용하여 Sigma 규칙을 SIEM에 도달하기 전에 소스 데이터에 적용합니다. Sigma 는 로그 이벤트를 설명하는 공급자 중립의 오픈 소스 표준입니다. 라이브 데이터 스트림에 규칙을 적용함으로써 Confluent Sigma는 Sigma의 이식성을 Apache Kafka의 속도와 확장성과 결합합니다.
이 가이드에서는 Confluent Sigma의 설치 과정을 안내하고 주요 사용 사례를 위한 실용적인 시나리오를 제공합니다. 이를 통해 보안 팀은 Detection as Code를 채택하고 위협에 보다 효과적으로 대응할 수 있습니다.
즉각적인 규모와 고급 기업 기능이 필요한 보안 팀을 위해, SOC Prime Platform 은 Confluent Sigma를 기반으로 완전히 지원되는 기업급 솔루션을 제공합니다.
Confluent Sigma 모듈 및 처리 로직
Confluent Sigma 는 세 가지 주요 모듈로 구성됩니다:
- sigma-parser: Sigma 규칙을 읽고 처리하는 핵심 기능을 제공하는 Java 라이브러리입니다.
- sigma-streams-ui: Sigma Streams 프로세스를 상호작용할 수 있는 개발 지향적 UI로, 사용자가 게시된 규칙을 보고, 규칙을 추가하거나 편집하고, 프로세서 상태를 모니터링하며, 탐지를 시각화할 수 있습니다.
- sigma-streams: 실제 스트림 프로세서와 관련된 커맨드 라인 스크립트를 포함하는 프로젝트의 주요 모듈입니다.
Sigma Streams 프로세서는 규칙 유형에 기반하여 효율적으로 탐지 로직을 적용하기 위해 Kafka Streams를 활용합니다:
- 간단한 토폴로지: 이 토폴로지는 하나의 서브토폴로지를 여러 규칙에 지원하며, 단일 이벤트 기록에 기반한 비집계 탐지에 사용됩니다. 프로세서는 Kafka Streams의
flatMapValues함수를 사용하여 기록을 변환합니다. 필터링을 위해 각 규칙을 반복하고, DSL 규칙에 대해 스트리밍 데이터를 검증하고, 일치 결과를 출력 목록에 추가합니다. 이 과정은 매우 효율적이며, 최종 탐지 기록은 즉시 동적 출력 주제로 전송됩니다. - 집계 토폴로지: 이 토폴로지는 각 규칙에 대해 상태 관리를 위한 서브토폴로지가 필요하며, 집계 또는 시간 창을 포함한 복잡하고 상태가 있는 탐지를 위해 사용됩니다. 고급 규칙의 경우, 프로세서는 먼저 데이터를 검증하고 지정된 키(e.g.,
id_orig_h)로 그룹화합니다. 규칙에서 슬라이딩 창을 적용(e.g.,timeframe: 10s)하고, 그 창 내의 인스턴스 수를 세고, 마지막으로 규칙의 집계 및 연산에 따라 필터링합니다(e.g.,count() > 10). 최종 집계된 탐지 기록은 이후 동적 출력 주제로 전송됩니다.
일치가 발생하면, 출력 전에 탐지 이벤트가 풍부하게 됩니다:
- 규칙 메타데이터: 이벤트에는 일치하는 규칙의
title,author,product, 그리고service. - 필드 매핑: 규칙이 정규 표현식(regex)을 사용하는 경우, 추출된 필드는 출력에 추가됩니다.
- 사용자 정의 필드: 규칙에 정의된 모든 사용자 지정 메타데이터가 문맥 및 다운스트림 라우팅을 위해 포함됩니다.
- 동적 출력: 결과는 규칙의
outputTopic필드에 지정된 주제로 전송됩니다.
Confluent Sigma 설치 방법
1단계: 시작하기
Confluent Sigma는 기능을 수행하기 위해 세 가지 주요 Kafka 주제에 의존합니다. Sigma Streams 프로세서는 이 주제를 지속적으로 모니터링하여 로직을 적용하고 탐지를 출력합니다.
- 규칙 주제: Sigma 규칙을 포함합니다
- 입력 데이터 주제: 들어오는 이벤트 데이터(e.g., 로그)를 포함합니다.
- 출력 주제: Sigma 규칙 하나 이상과 일치한 이벤트를 포함합니다.
Sigma 규칙은 Sigma Streams 프로세서가 모니터링하는 전용 Kafka 주제로 게시됩니다. 이러한 규칙은 다른 구독 주제의 데이터에 실시간으로 적용됩니다. 규칙과 일치하는 모든 기록은 지정된 출력 주제로 전달됩니다.
주의: 세 가지 주제 모두 구성에 정의되어야 합니다. 그러나 규칙은 특정 규칙 로직에 기반하여 다른 주제로의 라우팅을 위해 출력 대상을 재정의할 수 있습니다.
Confluent Sigma를 시작하기 전에 다음 사항을 준비합니다:
- Kafka 환경
- 실행 중인 Apache Kafka 클러스터(로컬 또는 프로덕션).
- Kafka CLI 도구 접근 권한(kafka-topics, kafka-console-producer, kafka-console-consumer).
- 올바른 네트워크 연결 및 주제를 생성하고 관리하기 위한 적절한 권한.
- Sigma Streams 애플리케이션
- Confluent Sigma Streams 애플리케이션을 다운로드하고 설치하세요.
- Ensure the
bin/confluent-sigma.sh스크립트가 실행 가능해야 합니다.
- Sigma 규칙
- YAML 또는 JSON 형식의 유효한 Sigma 규칙 파일들.
- 각 규칙은 Sigma 사양.
- Sigma Rule Loader (선택 사항)
- 규칙을 대량으로 로드하려는 경우 SigmaRuleLoader 유틸리티를 설치하세요.
- 구성 파일
유효한 sigma.properties 구성 파일을 갖추세요:- 규칙 주제
- 입력 데이터 주제
- 출력 주제
- 부트스트랩 서버 설정
2단계: Sigma 규칙 주제 생성
Sigma 규칙을 추가하기 전에 Sigma 규칙 주제를 생성하세요. 아래는 Sigma 규칙 주제를 생성하는 예제입니다:kafka-topics --bootstrap-server localhost:9092 --topic sigma_rules --replication-factor 1 --partitions 1 --config cleanup.policy=compact --create
주의: 프로덕션 배포의 경우, 최소한 3의 복제 인자를 사용하십시오. 규칙은 이벤트 데이터에 비해 상대적으로 적으므로, one 파티션이 일반적으로 충분합니다.
3단계. Sigma 규칙 로딩
Sigma 규칙은 사용자 지정 Kafka 주제에 저장됩니다. 각 Kafka 기록의 키는 다음 요구 사항을 충족해야 합니다:
- 유형:
string - 규칙의 제목 필드에 설정
주의: Sigma 사양에서는 ID 필드가 필요하지 않으므로, 규칙 제목은 고유해야 합니다. 새로 게시되거나 업데이트된 규칙은 실행 중인 Sigma Streams 프로세서에 의해 자동으로 수집됩니다.
Kafka에 규칙을 수집할 수 있습니다:
- SigmaRuleLoader 애플리케이션
- The
kafka-console-producer커맨드 라인 도구
SigmaRuleLoader를 통한 규칙 수집
SigmaRuleLoader 애플리케이션은 YAML 파일로 규칙을 대량 또는 개별적으로 수집할 수 있습니다.
단일 Sigma 규칙 파일을 로드하기 위해 -file 옵션을 사용하세요. 예를 들어:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -file zeek_sigma_rule.yml
Sigma 규칙이 포함된 디렉토리 전체를 로드하려면 -dir 옵션을 사용하세요:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -dir zeek_sigma_rules
CLI를 통한 규칙 수집
표준 Kafka CLI를 통해 Sigma 규칙을 수동으로 로드할 수도 있습니다, 예를 들어, kafka-console-producer 유틸리티를 사용하여:kafka-console-producer --broker-list localhost:9092 --topic sigma-rules --property "key.separator=:"
CLI를 통한 규칙 수집 코드 스니펫은 JSON 포맷으로 다음과 같습니다:--property "key.separator=:"
{"title":Sigma Rule Test,"id":"123456789","status":"experimental","description":"This is just a test.", "author":"Test", "date":"1970/01/01","references":["https://confluent.io/"],"tags":["test.test"],"logsource": {"category":"process_creation","product":"windows"},"detection":{"selection":{"CommandLine|contains|all": [" /vss "," /y "]},"condition":"selection"},"fields":["CommandLine","ParentCommandLine"],"falsepositives": ["Administrative activity"],"level":"high"}
4단계. Sigma Streams 애플리케이션 실행
Confluent Sigma Streams는 직접 실행하거나 confluent-sigma.sh 스크립트를 통해 실행할 수 있는 Java 애플리케이션입니다. 스크립트를 통해 애플리케이션을 실행하려면 다음 명령을 사용하세요:
bin/confluent-sigma.sh properties-file
Confluent Sigma Streams 구성 검색 순서:
- 커맨드 라인 인수 (
properties-file). $SIGMAPROPS환경 변수.
주의: 만약 properties-file를 지정하지 않으면, 애플리케이션은 $SIGMAPROPS 변수를 확인합니다.
- 전자가 설정되지 않은 경우, 앱은 다음 디렉토리에서
properties-file:~/.config~/.confluent~/tmp
다음의 예를 참조하여 sigma.properties 를 참조하세요.
구현 권장사항
Kafka 주제를 통한 규칙 핫 리로딩
주요 운영적 과제는 다운타임 없이 탐지 규칙을 업데이트하는 것입니다. Sigma 규칙이 추가되거나 수정될 때마다 스트림 처리 애플리케이션을 다시 시작하는 것은 비효율적이며 탐지 범위에 갭을 초래합니다.
- 권장사항: 전용 Kafka 주제를 “규칙 주제”로 작게 구성하세요. confluent-sigma 애플리케이션은 이 주제를 GlobalKTable을 사용하여 소비해야 합니다. 새로운 Sigma 규칙이 이 주제에 게시되면 (고유한 규칙 ID로 키가 지정됨), GlobalKTable은 실시간에 가깝게 자동으로 업데이트됩니다. 주요 이벤트 처리 스트림은 이 GlobalKTable과 연결될 수 있으며, 다시 시작할 필요 없이 항상 최신 규칙 세트를 보유하도록 합니다.
- 영향: 이는 무다운타임 규칙 배포를 제공하여 보안 분석가가 새로운 위협에 거의 즉시 대응할 수 있도록 합니다. 이는 규칙 관리 라이프사이클을 애플리케이션 배포 라이프사이클과 분리합니다.
규칙 매칭 전 스트림 내 이벤트 강화
원시 보안 로그는 고품질 알림에 필요한 문맥을 종종 부족합니다. 예를 들어, 원시 로그에는 IP 주소가 포함될 수 있지만 평판이 없거나 사용자 ID가 포함될 수 있지만 사용자의 부서 또는 역할이 없습니다. SIEM에 모든 강화를 의존하는 것은 문맥을 지연시키고 더 시끄러운 알림을 생성할 수 있습니다.
- 구체적인 권장사항: 주 스트림 규칙 매칭 로직 이전에 Kafka Streams 토폴로지 내에서 강화 단계를 구현하세요. 스트림-테이블 조인 을 사용하여 들어오는 이벤트 스트림을 강화하세요.
- 위협 인텔리전스: 위협 인텔리전스 피드에서 로드된 악성 IP, 도메인 또는 파일 해시의 GlobalKTable과 이벤트 스트림을 조인하세요.
- 자산/사용자 정보: CMDB 또는 Active Directory 피드에서 채워진 KTable과 이벤트 스트림을 조인하여 장치 소유자, 서버 중요도 또는 사용자 역할 등의 문맥을 추가하세요.
- 영향: 이는 극적으로 오탐을 줄이고 and 알림 우선 순위 정확성을 증가시킵니다. 중요 서버 또는 권한 있는 사용자를 포함하는 이벤트는 즉시 에스컬레이트될 수 있습니다. 또한 SIEM에 전송되는 경고는 기본적으로 더 가치 있게 만듭니다.
모범 사례
전용 Kafka 주제
- 격리: 다른 데이터 스트림에 대해 전용 주제를 사용하면 이들 간의 격리가 제공됩니다. 이는 하나의 데이터 스트림(예: 급작스러운 트래픽 급증)과 관련된 문제가 다른 스트림에 영향을 미칠 가능성을 줄입니다.
- 성능: 전용 주제는 각 주제의 특정 사용 사례에 맞게 구성을 최적화하여 성능을 개선할 수 있습니다. 예를 들어, 각 주제에 대해 서로 다른 파티션 수나 복제 인자를 설정할 수 있습니다.
확장성
- 수평 확장: Confluent Sigma 애플리케이션은 여러 인스턴스를 병렬로 실행하여 수평 확장할 수 있습니다. 각 인스턴스는 데이터의 하위 집합을 처리하여 시스템의 전체 처리량을 증가시킵니다.
- 파티셔닝: 수평 확장을 가능하게 하려면 Kafka 주제를 파티셔닝해야 합니다. 이는 여러 인스턴스가 동일한 주제에서 데이터를 병렬로 소비할 수 있게 해줍니다. 데이터가 파티션에 고르게 분산되도록 파티션 키를 선택해야 합니다.
- 컨슈머 그룹: Confluent Sigma 애플리케이션의 여러 인스턴스를 실행할 때, 동일한 컨슈머 그룹의 일부가 되도록 구성해야 합니다. 이렇게 하면 입력 주제의 각 메시지가 애플리케이션의 인스턴스 중 하나에서만 처리됩니다.
암호화
프로듀서, 컨슈머 그리고 Kafka 브로커 간의 데이터 전송을 암호화하기 위해 TLS/SSL을 사용해야 합니다. 이는 데이터가 엿보거나 변조되는 것을 방지합니다.
모니터링
프로덕션 환경에서 Confluent Sigma 애플리케이션의 상태와 성능을 모니터링하는 것이 중요합니다. 다음 지표를 모니터링해야 합니다:
- 처리된 메시지 수
- 생성된 경고 수
- 애플리케이션 지연 시간
- 애플리케이션의 CPU 및 메모리 사용량
핵심 지표
앞서 언급한 지표 외에도, 다음을 모니터링해야 합니다:
- 컨슈머 지연: 소비자가 아직 처리하지 않은 주제의 메시지 수입니다. 높은 컨슈머 지연은 애플리케이션이 들어오는 데이터의 비율을 따라잡지 못하고 있음을 나타낼 수 있습니다.
- 엔드 투 엔드 지연: 프로듀서에서 컨슈머로 메시지가 이동하는 데 걸리는 시간을 말합니다. 높은 엔드 투 엔드 지연은 네트워크 또는 Kafka 클러스터의 문제를 나타낼 수 있습니다.
Confluent Sigma 사용 사례
Confluent Sigma는 보안 팀이 고재생액 탐지를 실시간으로 Kafka 스트림에 직접 Sigma 규칙을 적용하여, 탐지 엔지니어가 데이터가 SIEM에 도달하기 전에 이상 현상에 대응하고 규칙 개선을 간소화할 수 있도록 합니다.
주요 사용 사례는 다음과 같습니다:
- Shift-Left 위협 탐지: SIEM에 로그가 도달하기 전에 원천에서 탐지 로직을 적용하여 실시간 공격에 대한 빠른 대응을 가능하게 합니다.
- 탐지를 위한 CI/CD 파이프라인 설정: 환경 전반에 걸쳐 규칙 배포와 업데이트를 자동화하여 운영 효율성과 일관성을 향상합니다.
- 환경 간 규칙 버전 관리: Kafka 주제 또는 Git을 사용하여 구조화된 규칙 버전 관리를 유지하여 추적 가능성을 보장하고 롤백을 쉽게 만듭니다.
- 로그 수집 비용 절감: 모든 로그를 SIEM에 수집하지 않고 비행 중 위협을 감지하여 저장 및 처리 비용을 절감합니다.
- SIEM 쿼리 지연 제거: 실시간 스트림에서 규칙을 처리하여 고재생탐지를 즉시 액세스 가능합니다.
- 상관 속도 향상: Kafka Streams 내에서 집계 및 슬라이딩 윈도우 로직을 적용하여 이벤트를 신속하게 상관시키고 경고를 생성합니다.
Confluent Sigma는 SOC Prime 기술로 구동됩니다
오픈 소스 Confluent Sigma 프로젝트는 Shift-Left 탐지에 대한 강력한 기반을 제공하지만, 이를 기업급 솔루션과 통합할 때 그 진정한 확장성과 고급 위협 커버리지 잠재력을 발휘합니다. SOC Prime. 아래의 비교는 대규모 및 복잡한 환경의 요구를 충족시키기 위해 핵심 기능이 어떻게 발전해 나가는지를 강조합니다.
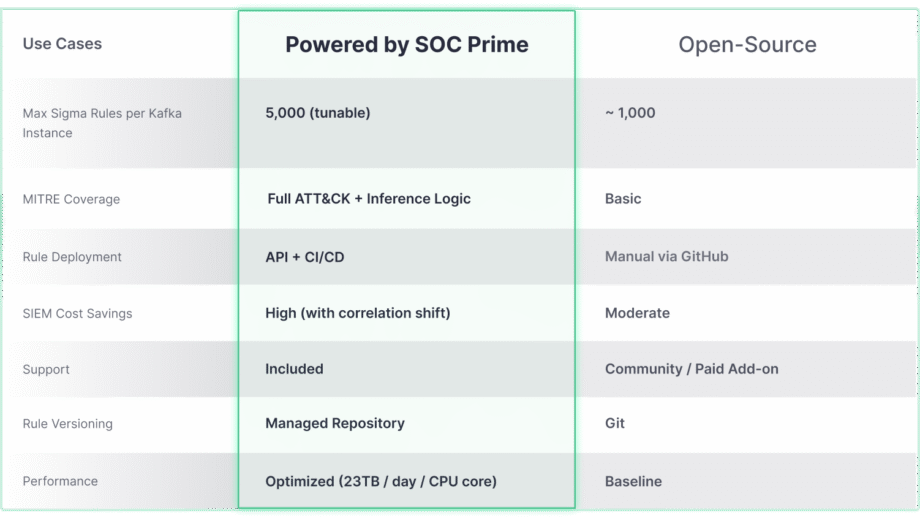
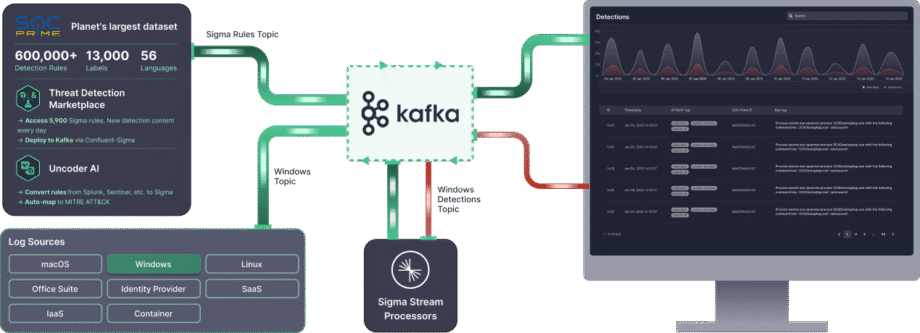
Confluent Sigma & SOC Prime 솔루션은 탐지 수명 주기를 극적으로 가속화하는 도구와 콘텐츠에 직접 액세스할 수 있도록 제공합니다:
- 위협 탐지 마켓플레이스: 위협 탐지 마켓플레이스를 활용하여 보안팀은 15K+ Sigma 규칙 중에서 신종 위협을 다루는 규칙을 선택하고 이를 자동화된 방식으로 Kafka 환경에 직접 스트리밍할 수 있습니다.
- Uncoder AI: SOC Prime의 Uncoder AI를 통해, 종단 간 탐지 엔지니어링의 IDE이자 코파일럿으로서 방어자들은 다양한 언어 형식의 탐지 코드를 Sigma로 변환하고, 자동으로 MITRE ATT&CK에 매핑하며, AI로부터 코드를 처음부터 작성하거나 즉석에서 조정하여 효율적인 위협 탐지를 보장할 수 있습니다..
- 운영 우수성: API 및 CI/CD를 통한 자동화된 배포는 일관적이고 반복 가능한 규칙 롤아웃을 보장하며, 높은 처리량 성능(하루당 CPU 코어당 최대 23TB)으로 실시간, 확장 가능한 위협 탐지를 어떤 환경에서도 가능하게 합니다.
- 전문가 지원: SOC Prime의 최상급 엔지니어링 전문성을 활용하여 오픈 소스 탐지 스택의 설치, 관리 및 확장에 대한 안내를 받을 수 있습니다.