脅威ハンティングの基本: 手動で始める

目次:
このブログの目的は、脅威ハンティングにおける手動(アラートベースでない)分析手法の必要性を説明することです。集計やスタックカウントによる効果的な手動分析の例が提供されています。
オートメーションは必要不可欠
オートメーションは絶対に重要であり、脅威ハンターとして我々は可能な限りオートメーション化を進めなければなりません。しかし、オートメーションはデータや特定の環境で効果的であるという前提に基づいています。多くの場合、これらの前提は他のアナリストやエンジニア、システム所有者などによって脅威ハンターに対して設定されます。例えば、一般的な前提は、アラートベースの検出において、System Center Configuration Monitor(SCCM)やその他のエンドポイント管理製品からのプロセス作成イベントをホワイトリストに追加することです。もう一つの例は、SIEMエンジニアがリソースを節約するために使用されていないログをフィルタリングすることです。攻撃者はこのような前提を特定し、それに隠れる方法を知りつつあります。例えば、システムのSysmon設定における弱点を特定するためのツールが作成されています [1] 。前提の層をはがして検査することで、脅威ハンターは可視性のギャップを特定し、それに基づいてギャップに対してハンティングを行い、妥協点を発見することに成功するかもしれません。このブログポストは、集計を使用して手動で興味深いデータを効率的にレビューすることで、これらの前提のいくつかを取り除くことに焦点を当てています。
手動アプローチが必要
おそらく支配的な脅威ハンティングの前提は「侵害を想定する」です。侵害への対応は、特にスコーピング中は、手動の人間の分析と介入をほぼ常に伴います。効果的なスコーピングは、単にアラートのレビューを行うだけではありません。効果的なスコーピングは、環境全体で検索することができる指標や行動を既知の妥協されたホストの手動分析を含みます。そのため、脅威ハンターとして、侵害を想定している場合、手動の分析が本質的に必要となります。別の見方として、アラートベースのデータのみをレビューすることで、成功した攻撃者が環境内で少なくとも一つのルールやアラートをトリガーし、その結果、侵害を特定するための明確で実行可能な決定を行うことができるという仮定を置いていることになります。しかし、脅威ハンターは、環境内のすべてのデータソースごとにすべてのログを手動で分析するという負担をかけるべきではありません。その代わりに、脳を使って関連データを効果的にレビューし、決定を下す方法を特定する必要があります。イベントに対してアラートを出すために使用した論理をはがし、アラートに使用するフィールドや文脈を集計することは、ほとんどの環境で効果的な手動分析の例です。
集計の例(スタックカウント)
手動ハンティングアプローチの最も簡単で効果的な方法の一つは、特定のコンテキストのもとでの受動的データ収集の興味深い/実行可能なフィールドの集計です。Microsoft Officeのピボットテーブル、Splunkのstatsコマンド、Arcsightの「top」コマンドを使用したことがあるなら、このコンセプトに精通しているでしょう。注: この手法は、スタックカウント、データスタッキング、スタッキング、またはピボットテーブルとも呼ばれています。初心者のハンターは集約の概念により馴染みがあると思われるので、ここではその用語を使用しています。Fireeyeはこのコンセプトを脅威ハンティングの文脈で最初に公開したようです[2]。
注: パッシブデータは、それがセキュリティ関連かどうかに関係なくイベントについて教えてくれるデータソースです。例えば、パッシブデータソースは、プロセスが作成された、ネットワーク接続が確立された、ファイルが読み込まれた/書き込まれたなどを教えてくれるかもしれません。ホストログ、例えばWindowsイベントログは、パッシブデータソースの優れた例です。パッシブデータソースは、ほとんどの脅威ハンティングプログラムのバックボーンの主な部分を構成します。例として、イメージ1は、環境内で30日間にわたるすべてのsysmonのネットワーク接続イベントを、宛先ポート22(SSH)で集計した一部を示しています。脅威ハンターは、この集計を使用して、通常ポート22の接続と関連付けられないプロセスを「狩る」ことができます。
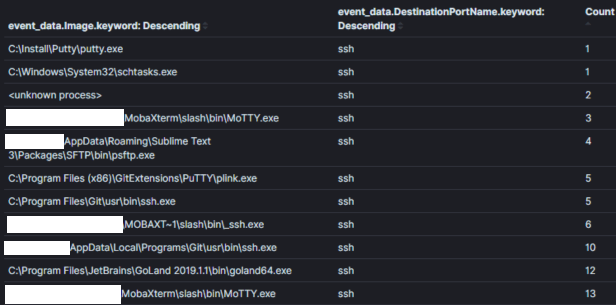 イメージ1: Kibanaにおける簡単な集計
イメージ1: Kibanaにおける簡単な集計
イメージ1:
集計フィールド: プロセス名コンテキスト: 30日以内にポート22を使用するプロセス結果: 120分析の時間: < 1 分脅威ハンティングにおいては、コンテキストが鍵であり、それにはハンティング仮説の意図が含まれています。集計のコンテキストは通常、基礎となるクエリで設定され、我々が集計し観察するフィールドを通じてアナリストに公開されます。イメージ1では「ポート22を使うプロセス」というコンテキストが、クエリ論理(syemon_eid == 3 AND 宛先ポート == 22)に変換され、プロセス名を含むフィールドの集計/表示によって表現されています。集計においてコンテキストが狭すぎたり広すぎたりしないようにバランスを取ることが重要です。イメージ2では、前のイメージからコンテキストを広げてネットワーク接続を持つすべてのプロセスを返すようにしました。このコンテキストでも悪意を見つけることが可能ですが、明らかに異常なプロセス名やネットワーク活動を持たないプロセスでない限り、データに関する決定を下すのが難しくなります(これは徐々に珍しくなっています)。イメージ2:
集計フィールド: プロセス名コンテキスト: ネットワーク接続を持つプロセス結果: 1000+分析の時間: 1 分
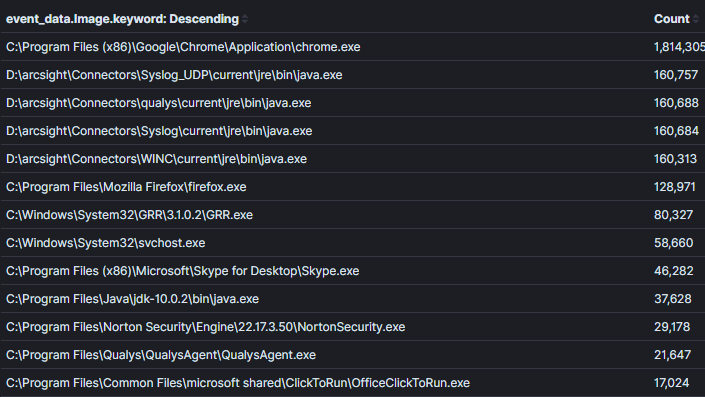 イメージ2: 十分なコンテキストがない場合の効果的でない集計最後に、意思決定に使用されないフィールドに対する集計は効果的ではなくなります。イメージ3では、最後の集計に「プロセスID」フィールドを追加しました。プロセスIDを知ることは、不自然なプロセスを特定した後に役立つかもしれませんが、各プロセス名とIDの組み合わせごとに重複エントリを作成します。この実行例では、結果は4倍以上に増加し、多くのプロセス名が重複した。意思決定を可能にするフィールドに基づいて集計することが重要です。特定のホストやユーザーを特定するために必要な情報は、狭いコンテキストでの追加のクエリを使用して特定するべきです。イメージ1の例では、puttyを使用してSSHしているユーザーを特定したい場合、(process_name==「*putty.exe」AND sysmon_eid==3)の論理を使用できます。私の意見では、クエリとダッシュボードの間を効率的に移行できるKibanaのピン可能なフィルタリングシステムが、私が使用した他の分析ツールよりも優れていると思います[4]。
イメージ2: 十分なコンテキストがない場合の効果的でない集計最後に、意思決定に使用されないフィールドに対する集計は効果的ではなくなります。イメージ3では、最後の集計に「プロセスID」フィールドを追加しました。プロセスIDを知ることは、不自然なプロセスを特定した後に役立つかもしれませんが、各プロセス名とIDの組み合わせごとに重複エントリを作成します。この実行例では、結果は4倍以上に増加し、多くのプロセス名が重複した。意思決定を可能にするフィールドに基づいて集計することが重要です。特定のホストやユーザーを特定するために必要な情報は、狭いコンテキストでの追加のクエリを使用して特定するべきです。イメージ1の例では、puttyを使用してSSHしているユーザーを特定したい場合、(process_name==「*putty.exe」AND sysmon_eid==3)の論理を使用できます。私の意見では、クエリとダッシュボードの間を効率的に移行できるKibanaのピン可能なフィルタリングシステムが、私が使用した他の分析ツールよりも優れていると思います[4]。
イメージ3:
集計フィールド: プロセス名 + プロセスIDコンテキスト: ネットワーク接続を持つプロセス結果: 1000+分析の時間: 10 分
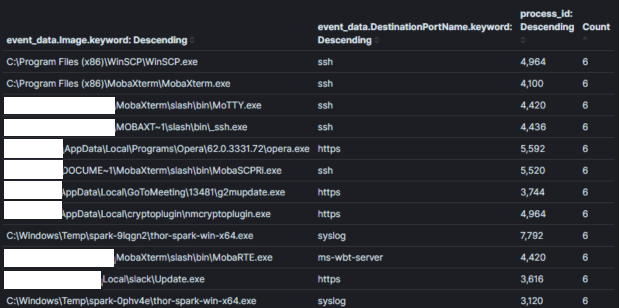 イメージ3: ノンコンテキストフィールドを持つ効果的でない集計
イメージ3: ノンコンテキストフィールドを持つ効果的でない集計
注: elastisearchのKibanaのような特定のシステムでは、ダッシュボードを使用して1つのデータテーブルから別のデータテーブルに簡単に移行できます。それ以外の場合は、興味深い集計を特定すると、アナリストは通常、興味深い動作を行ったホストやアカウントをレビューするために移行します。
注: 外れ値の検出の罠に注意してください。集計/スタックカウントにおける「一般的なものは良い」、「一般的でないものは悪い」という概念に頼らないでください。これは必ずしも正しくありません。なぜなら、妥協は一般的に複数のマシンを伴い、攻撃者はこの仮定を利用してノイズを作り、正常に見せかけることもあるからです。さらに、ほとんどの環境にはニッチなソフトウェアやユースケースが存在します。すべての「最も一般的でない」スタックをトリアージし、時間を無駄にして誤検知を特定することに陥りがちです。環境の事前妥協を理解し、脅威アクターの動作への直感を磨くことが、ここで役立つでしょう[3]。
しかし、スケールするのか?
ログの手動分析は、通常アナリストが1つのコンテキストを一度に観察するため、アラートほどスケールしません。たとえば、数万または数十万の結果を持つ単一の集計をレビューすることが一般的です。集計をレビューする時間は、せいぜい10分以内が理想です。脅威ハンターとして圧倒されていると感じた場合、コンテキストを狭めることを試みるかもしれません。たとえば、20,000のホスト環境をホスト名によってホストを分けるクエリロジックを使って2つの10,000ホスト環境に分けることができます。あるいは、「黄金のナゲット」や「王国の鍵」を含む重要な資産/アカウントを特定し、これらに対して手動分析を行うことが考えられます。
貴社は効率的にコンテンツを制作し、アラートをレビューし、ホストをトリアージすることができ、より手動の脅威ハンティング技術に時間を割くことができます。
SOC PrimeのTDM [5] にあるSIEMコンテンツは、アラートとして完全に自動化できるコンテンツと、より手動の脅威ハンティングアプローチを促進するコンテンツが豊富です。
リソースと以前の作業に対する感謝:
[1] https://github.com/mkorman90/sysmon-config-bypass-finder
[2] https://www.fireeye.com/blog/threat-research/2012/11/indepth-data-stacking.html
[3] https://socprime.com/blog/warming-up-using-attck-for-self-advancement/
[4] https://www.elastic.co/guide/en/kibana/current/field-filter.html
[5] https://tdm.socprime.com/login/


