Nozioni di base sul Threat Hunting: Entrare nel Manuale

Indice:
Lo scopo di questo blog è spiegare la necessità di metodi di analisi manuale (non basati su avvisi) nel threat hunting. Viene fornito un esempio di analisi manuale efficace tramite aggregazioni/conta stack.
L’automazione è necessaria
L’automazione è assolutamente cruciale e come threat hunters dobbiamo automatizzare il più possibile dove possibile.
Tuttavia, l’automazione si basa su assunzioni sui dati o su come l’automazione sarà efficace in un dato ambiente. Molte volte queste assunzioni sono state fatte per il threat hunter da altri analisti, ingegneri, proprietari di sistemi, ecc. Un esempio comune è la whitelist degli eventi di creazione del processo di System Center Configuration Monitor (SCCM) o altri prodotti di gestione degli endpoint nelle rilevazioni basate su avvisi. Un altro esempio è quando gli ingegneri SIEM filtrano i log inutilizzati per risparmiare risorse. I malintenzionati sono sempre più consapevoli di identificare tali assunzioni e rimanere nascosti all’interno di esse. Ad esempio, sono stati scritti strumenti per identificare le debolezze nella configurazione sysmon di un sistema [1].
Rimuovendo e ispezionando gli strati di assunzioni i threat hunters possono avere successo nell’identificare lacune nella visibilità e cacciare su queste lacune per scoprire una compromissione. Questo post del blog si concentra sulla rimozione di alcune di queste assunzioni utilizzando aggregazioni per esaminare manualmente in modo efficiente i dati interessanti.
Gli approcci manuali sono necessari
Forse la premessa dominante del threat hunting è “Assumere Compromesso”. Rispondere a un compromesso (quasi) sempre comporta analisi e interventi manuali soprattutto durante la delimitazione. Una delimitazione efficace non si limita solo a esaminare gli avvisi. Una delimitazione efficace comporta l’analisi manuale degli host noti compromessi per indicatori e comportamenti che possono essere cercati nel restante ambiente. Pertanto, come threat hunters se stiamo “Assumendo Compromesso”, l’analisi manuale è intrinsecamente richiesta.
Un altro modo di vedere la cosa è osservare che esaminando solo i dati basati su avvisi, stiamo assumendo che un attaccante riuscito innescherà almeno una regola/avviso nel nostro ambiente che è chiaro e abbastanza azionabile da permetterci di prendere una decisione che porta all’identificazione della compromissione.
Detto questo, i threat hunters non dovrebbero caricarsi dell’analisi manuale di ogni log per ogni fonte di dati nell’ambiente. Invece dobbiamo identificare un modo per far esaminare i nostri cervelli i dati rilevanti e prendere decisioni nel modo più efficace possibile.
Rimuovendo la logica che usiamo per avvisare gli eventi e aggregando sui campi e contesti che usiamo nei nostri avvisi è un esempio di analisi manuale efficace per la maggior parte degli ambienti.
Aggregazione come esempio (Conta Stack)
Uno dei metodi più semplici ed efficaci per approcci di caccia manuale è l’aggregazione sui campi interessanti/azionabili della raccolta passiva dei dati dato un contesto specifico.
Se hai mai usato le tabelle pivot di Microsoft Office, il comando stats di Splunk, o il comando “top” di Arcsight sei familiare con questo concetto.Nota: Questa tecnica è anche comunemente chiamata conta stack, stacking dei dati, stacking, o tabelle pivot :). Credo che i cacciatori alle prime armi saranno più familiari con il concetto di aggregazione, quindi uso quel termine qui. Fireeye sembra essere stata la prima a pubblicare questo concetto nel contesto del threat hunting [2].
Nota: I dati passivi sono una fonte di dati che ti informa su un evento, sia esso rilevante per la sicurezza o meno. Ad esempio, una fonte di dati passivi potrebbe dirti che un processo è stato creato, una connessione di rete è stata stabilita, un file è stato letto/scritto, ecc. I log degli host, come i log eventi di Windows, sono ottimi esempi di una fonte di dati passivi. Le fonti di dati passivi costituiscono una parte importante della spina dorsale per la maggior parte dei programmi di threat hunting.Ad esempio, l’Immagine 1 mostra parte di un’aggregazione di tutti gli eventi di connessione di rete sysmon con porta di destinazione 22 (SSH) in un ambiente su un periodo di 30 giorni. Un threat hunter potrebbe utilizzare questa aggregazione per ‘cacciare’ processi che normalmente non sarebbero associati a connessioni sulla porta 22.
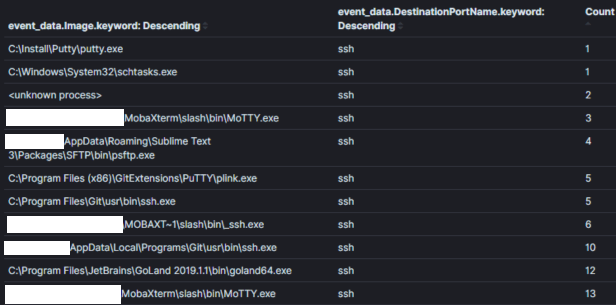 Immagine 1: Aggregazione semplice in Kibana
Immagine 1: Aggregazione semplice in Kibana
Immagine Uno:
Campo di Aggregazione: Nome del ProcessoContesto: Processi che usano la porta 22 entro 30 giorniRisultati: 120Tempo da Analizzare: < 1 minIl contesto è il re nella caccia con aggregazioni e contiene l’intenzione della tua ipotesi di caccia. Il contesto di un’aggregazione è tipicamente impostato nella query sottostante e viene esposto all’analista tramite i campi su cui aggreghiamo e osserviamo. Nell’Immagine 1 il contesto di “Processi che usano la porta 22” è convertito nella logica di query (symon_eid == 3 E porta di destinazione == 22) e aggregando/mostrando il campo contenente i nomi dei processi.
È importante trovare un equilibrio tra quanto ristretto o ampio sia il contesto in un’aggregazione. Ad esempio, nell’Immagine 2 ho ampliato il contesto rispetto all’Immagine precedente per restituire tutti i processi con connessioni di rete. È possibile trovare il male in questo contesto, tuttavia, sarà più difficile prendere decisioni sui dati a meno che non ci sia un nome di processo evidentemente insolito o un processo che non avrebbe mai realmente attività di rete (cosa sempre più rara).Immagine 2:
Campo di Aggregazione: Nome del ProcessoContesto: Processi con connessioni di reteRisultati: 1000+Tempo da Analizzare: 1 min
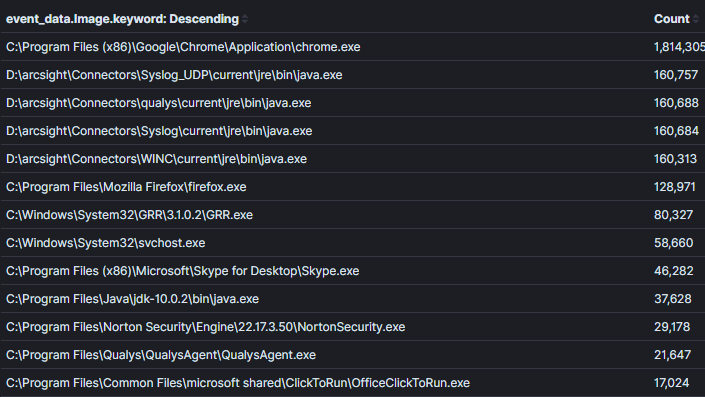 Immagine 2: Un’aggregazione meno efficace senza abbastanza contestoInfine, le aggregazioni diventano meno efficaci quando campi che non saranno usati per prendere decisioni vengono aggregati. Nell’Immagine 3, ho aggiunto il campo “ID processo” alla nostra ultima aggregazione. Conoscere l’ID del processo può essere utile una volta che identifichiamo un processo insolito, tuttavia, crea un duplicato per ogni combinazione unica di nome del processo e id. Nell’esempio corrente i risultati sono più che quadruplicati e molti nomi di processi sono stati duplicati. È importante aggregare su campi che ti permettono di prendere decisioni. Le informazioni che possono essere necessarie per identificare un host o utente specifico per triage dovrebbero essere identificate utilizzando una query aggiuntiva con contesto ristretto. Nell’esempio dell’immagine 1 se volessimo identificare chi stava usando putty per SSH, possiamo usare la logica (process_name==”*putty.exe” E sysmon_eid==3). A mio parere, questo è un campo dove Kibana supera altri strumenti analitici che ho usato perché il passaggio tra query e dashboard è altamente efficiente tramite il loro sistema di filtro pinabile [4].
Immagine 2: Un’aggregazione meno efficace senza abbastanza contestoInfine, le aggregazioni diventano meno efficaci quando campi che non saranno usati per prendere decisioni vengono aggregati. Nell’Immagine 3, ho aggiunto il campo “ID processo” alla nostra ultima aggregazione. Conoscere l’ID del processo può essere utile una volta che identifichiamo un processo insolito, tuttavia, crea un duplicato per ogni combinazione unica di nome del processo e id. Nell’esempio corrente i risultati sono più che quadruplicati e molti nomi di processi sono stati duplicati. È importante aggregare su campi che ti permettono di prendere decisioni. Le informazioni che possono essere necessarie per identificare un host o utente specifico per triage dovrebbero essere identificate utilizzando una query aggiuntiva con contesto ristretto. Nell’esempio dell’immagine 1 se volessimo identificare chi stava usando putty per SSH, possiamo usare la logica (process_name==”*putty.exe” E sysmon_eid==3). A mio parere, questo è un campo dove Kibana supera altri strumenti analitici che ho usato perché il passaggio tra query e dashboard è altamente efficiente tramite il loro sistema di filtro pinabile [4].
Immagine 3:
Campo di Aggregazione: Nome del Processo + ID ProcessoContesto: Processi con connessioni di reteRisultati: 1000+Tempo da Analizzare: 10 min
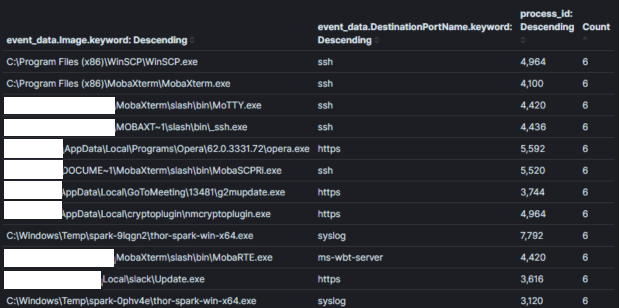 Immagine 3: Un’aggregazione meno efficace con campi non contestuali
Immagine 3: Un’aggregazione meno efficace con campi non contestuali
Nota: In certi sistemi come Kibana di elasticsearch è facile passare da una tabella di dati all’altra usando i loro dashboard. Altrimenti, una volta identificata un’aggregazione interessante, un analista passerà tipicamente a esaminare l’host o gli account che sono stati osservati compiere il comportamento interessante.
Nota: Dovresti essere consapevole della trappola del rilevamento degli outlier. Non affidarti al concetto di “comune è buono e “non comune è cattivo” nelle aggregazioni/conta stack. Questo non è necessariamente vero, poiché i compromessi coinvolgono generalmente più macchine e gli avversari possono cercare di approfittare di questa assunzione per creare rumori e apparire normali. Inoltre, software e casi d’uso di nicchia esistono in quasi ogni ambiente. È facile lasciarsi coinvolgere nell’analisi di ogni “stack meno comune” e perdere tempo a identificare falsi positivi. Conoscere l’ambiente prima del compromesso e affinare il tuo istinto sul comportamento degli attori di minaccia [3] ti aiuterà qui.
Ma scala?
L’analisi manuale dei log non scala altrettanto bene degli avvisi poiché un analista tipicamente osserverà un singolo contesto alla volta. Ad esempio, esaminare una singola aggregazione con decine o anche centinaia di migliaia di risultati è comune. Il tempo massimo in cui vuoi trovarti a esaminare un’aggregazione è probabilmente 10 min. Se come threat hunter ti trovi sopraffatto, potresti provare a restringere il contesto. Ad esempio, puoi dividere un ambiente di 20.000 host in due ambienti di 10.000 host con logica di query che separa gli host per i loro nomi. In alternativa puoi identificare asset/account critici contenenti i “nuggets d’oro” o le “chiavi del regno” e eseguire l’analisi manuale su quelli.
È possibile creare contenuti, esaminare avvisi e fare triage degli host abbastanza efficientemente da avere tempo per tecniche di threat hunting più manuali.
Il contenuto SIEM disponibile nella TDM di SOC Prime [5] è ricco di contenuti che possono essere completamente automatizzati come avvisi così come contenuti per abilitare approcci più manuali al threat hunting.
Risorse e ringraziamenti ai lavori precedenti:
[1] https://github.com/mkorman90/sysmon-config-bypass-finder
[2] https://www.fireeye.com/blog/threat-research/2012/11/indepth-data-stacking.html
[3] https://socprime.com/blog/warming-up-using-attck-for-self-advancement/
[4] https://www.elastic.co/guide/en/kibana/current/field-filter.html
[5] https://tdm.socprime.com/login/


