Principes de base de la chasse aux menaces : se mettre au manuel

Table des matières :
L’objectif de ce blog est d’expliquer la nécessité des méthodes d’analyse manuelles (non basées sur des alertes) dans la traque des menaces. Un exemple d’analyse manuelle efficace via l’agrégation/compte des piles est fourni.
L’automatisation est nécessaire
L’automatisation est absolument cruciale et en tant que traqueurs de menaces, nous devons automatiser autant que possible là où c’est possible.
Cependant, l’automatisation repose sur des suppositions concernant les données ou sur l’efficacité de l’automatisation dans un environnement donné. Souvent, ces suppositions ont été faites pour le traqueur de menaces par d’autres analystes, ingénieurs, propriétaires de systèmes, etc. Par exemple, une supposition courante est la mise sur liste blanche des événements de création de processus à partir de System Center Configuration Monitor (SCCM) ou d’autres produits de gestion des bouts de la chaîne dans les détections basées sur des alertes. Un autre exemple est celui des ingénieurs SIEM filtrant les journaux inutilisés pour économiser des ressources. Les attaquants sont de plus en plus conscients d’identifier ces suppositions et de rester cachés en leur sein. Par exemple, des outils ont été développés pour identifier les faiblesses dans la configuration sysmon d’un système [1].
En décortiquant et en inspectant les couches de suppositions, les traqueurs de menaces peuvent réussir à identifier des lacunes dans la visibilité et chasser ces lacunes pour découvrir une compromission. Cet article de blog se concentre sur la suppression de certaines de ces suppositions en utilisant des agrégations pour examiner efficacement les données intéressantes manuellement.
Les approches manuelles sont nécessaires
Peut-être que le principe dominant de la traque des menaces est « Partir du principe qu’il y a une compromission ». Répondre à une compromission implique (presque) toujours une analyse et une intervention humaines manuelles, surtout lors du périmètre. Une délimitation efficace ne se limite pas à examiner des alertes. Une délimitation efficace implique une analyse manuelle des hôtes déjà compromis pour rechercher des indicateurs et des comportements qui peuvent être recherchés dans le reste de l’environnement. Ainsi, en tant que traqueurs de menaces, si nous « partons du principe qu’il y a une compromission », une analyse manuelle est intrinsèquement nécessaire.
Une autre façon de voir les choses est d’observer qu’en ne révisant que des données basées sur des alertes, nous supposons qu’un attaquant réussi déclenchera au moins une règle/alerte dans notre environnement suffisamment claire et exploitable pour que nous puissions prendre une décision qui résulte en l’identification de la compromission.
Cela étant dit, les traqueurs de menaces ne devraient pas se surcharger avec l’analyse manuelle de chaque journal pour chaque source de données dans l’environnement. Au lieu de cela, nous devons identifier un moyen de nous permettre de revoir des données pertinentes et de prendre des décisions aussi efficacement que possible.
Décortiquer la logique utilisée pour alerter sur les événements et agréger sur les champs et contextes que nous utilisons dans notre alerte est un exemple d’analyse manuelle efficace pour la plupart des environnements.
L’agrégation comme exemple (Compte des piles)
Une des méthodes les plus simples et les plus efficaces pour des approches de chasse manuelles est l’agrégation sur des champs intéressants/pertinents de la collecte de données passive dans un contexte spécifique.
Si vous avez déjà utilisé les tableaux croisés dynamiques de Microsoft Office, la commande stats de Splunk ou la commande “top” de Arcsight, vous êtes familier avec ce concept.Remarque : Cette technique est également communément appelée comptage des piles, empilement de données, empilage, ou tableaux croisés dynamiques :). Je crois que les chasseurs novices seront plus familiers avec le concept d’agrégation donc j’utilise ce terme ici. Fireeye semble être le premier à publier ce concept dans le contexte de la traque des menaces [2].
Remarque : Les données passives sont une source de données qui vous informe d’un événement, qu’il soit pertinent pour la sécurité ou non. Par exemple, une source de données passive peut vous indiquer qu’un processus a été créé, qu’une connexion réseau a été établie, qu’un fichier a été lu/écrit, etc. Les journaux hôtes, tels que Windows Event Logs, sont de bons exemples de sources de données passives. Les sources de données passives constituent une grande partie de l’épine dorsale de la plupart des programmes de traque des menaces.À titre d’exemple, l’Image 1 montre une partie d’une agrégation de tous les événements de connexions réseau sysmon avec le port de destination 22 (SSH) dans un environnement sur 30 jours. Un traqueur de menaces pourrait utiliser cette agrégation pour « chasser » les processus qui ne seraient normalement pas associés à des connexions sur le port 22.
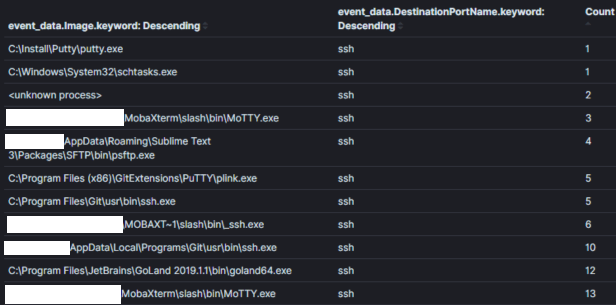 Image 1 : Agrégation simple dans Kibana
Image 1 : Agrégation simple dans Kibana
Image Une:
Champ d’agrégation: Nom du processusContexte: Processus utilisant le port 22 en 30 joursRésultats: 120Temps d’analyse: < 1 minLe contexte est essentiel pour la traque avec les agrégations et il contient l’intention de votre hypothèse de chasse. Le contexte d’une agrégation est typiquement défini dans la requête sous-jacente et exposé à l’analyste via les champs que nous agrégeons et observons. Dans l’Image 1, le contexte de « Processus utilisant le port 22 » est converti en logique de requête (symon_eid == 3 ET port de destination == 22) et en agrégeant/affichant le champ contenant les noms des processus.
Il est important de trouver un équilibre entre la portée étroite ou large du contexte au sein d’une agrégation. Par exemple, dans l’Image 2, j’ai élargi le contexte par rapport à l’image précédente pour renvoyer tous les processus avec des connexions réseau. Il est possible de trouver du mal dans ce contexte, cependant, il sera plus difficile de prendre des décisions sur les données à moins qu’il n’y ait un nom de processus inhabituel évident ou un processus pour lequel il n’y aurait jamais réellement d’activité réseau (ce qui est de moins en moins courant).Image 2:
Champ d’agrégation: Nom du processusContexte: Processus avec connexions réseauRésultats: 1000+Temps d’analyse: 1 min
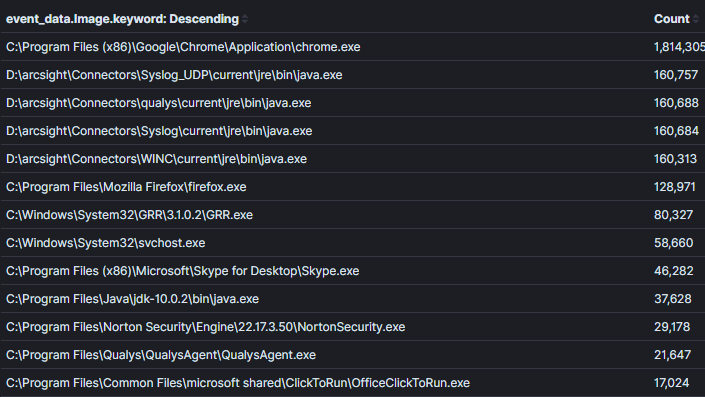 Image 2 : Une agrégation moins efficace sans suffisamment de contexteEnfin, les agrégations deviennent moins efficaces lorsque les champs qui ne seront pas utilisés pour prendre des décisions sont agrégés. Dans l’Image 3, j’ai ajouté le champ « ID du processus » à notre dernière agrégation. Connaître l’ID du processus peut être utile une fois que nous identifions un processus inhabituel, cependant, cela crée une entrée dupliquée pour chaque combinaison unique de nom de processus et d’ID. Dans l’exemple courant, les résultats ont plus que quadruplé et de nombreux noms de processus ont été dupliqués. Il est important d’agréger sur les champs qui vous permettent de prendre des décisions. Les informations qui peuvent être requises pour identifier un hôte ou un utilisateur spécifique pour le triage devraient être identifiées à l’aide d’une requête supplémentaire avec un contexte étroit. Dans l’exemple tiré de l’image 1, si nous voulions identifier qui utilisait putty pour SSH, nous pouvons utiliser la logique (process_name==”*putty.exe” AND sysmon_eid==3). À mon avis, c’est un domaine où Kibana surpasse les autres outils d’analytique que j’ai utilisés car pivoter entre requêtes et tableaux de bord est très efficace via leur système de filtrage épinglable [4].
Image 2 : Une agrégation moins efficace sans suffisamment de contexteEnfin, les agrégations deviennent moins efficaces lorsque les champs qui ne seront pas utilisés pour prendre des décisions sont agrégés. Dans l’Image 3, j’ai ajouté le champ « ID du processus » à notre dernière agrégation. Connaître l’ID du processus peut être utile une fois que nous identifions un processus inhabituel, cependant, cela crée une entrée dupliquée pour chaque combinaison unique de nom de processus et d’ID. Dans l’exemple courant, les résultats ont plus que quadruplé et de nombreux noms de processus ont été dupliqués. Il est important d’agréger sur les champs qui vous permettent de prendre des décisions. Les informations qui peuvent être requises pour identifier un hôte ou un utilisateur spécifique pour le triage devraient être identifiées à l’aide d’une requête supplémentaire avec un contexte étroit. Dans l’exemple tiré de l’image 1, si nous voulions identifier qui utilisait putty pour SSH, nous pouvons utiliser la logique (process_name==”*putty.exe” AND sysmon_eid==3). À mon avis, c’est un domaine où Kibana surpasse les autres outils d’analytique que j’ai utilisés car pivoter entre requêtes et tableaux de bord est très efficace via leur système de filtrage épinglable [4].
Image 3:
Champ d’agrégation: Nom du processus + ID du processusContexte: Processus avec connexions réseauRésultats: 1000+Temps d’analyse: 10 mins
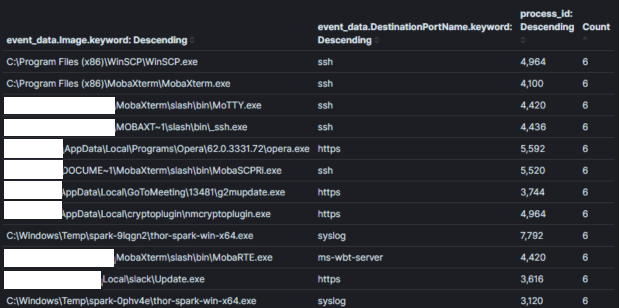 Image 3 : Une agrégation moins efficace avec des champs non contextuels
Image 3 : Une agrégation moins efficace avec des champs non contextuels
Remarque : Dans certains systèmes comme Kibana d’Elasticsearch, il est facile de pivoter d’un tableau de données à un autre en utilisant leurs tableaux de bord. Sinon, une fois que vous identifiez une agrégation intéressante un analyste passera typiquement à l’examen des machines hôtes ou comptes qui ont été observés effectuant le comportement intéressant.
Remarque : Vous devez être conscient du piège de la détection d’anomalies. Ne vous fiez pas au concept de « ce qui est commun est bon et ce qui est inhabituel est mauvais » dans les agrégations/comptes de piles. Ce n’est pas nécessairement vrai, car les compromissions impliquent généralement plusieurs machines et les adversaires peuvent essayer de tirer parti de cette supposition pour créer du bruit et paraître normaux. De plus, des logiciels de niche et des cas d’utilisation existent dans presque chaque environnement. Il est facile de se laisser entraîner à trier chaque pile « la moins commune » et perdre du temps à identifier les faux positifs. Connaître l’environnement avant compromission et affiner votre instinct au sujet du comportement des acteurs malveillants [3] vous aidera ici.
Mais est-ce que ça évolue ?
L’analyse manuelle des journaux ne s’adapte pas aussi bien que les alertes car un analyste observera typiquement un seul contexte à la fois. Par exemple, examiner une seule agrégation avec des dizaines voire des centaines de milliers de résultats est courant. Le plus longtemps que vous voudrez vous retrouver à examiner une agrégation est probablement de 10 minutes. Si en tant que traqueur de menaces vous vous trouvez submergé, vous pourriez essayer de réduire le contexte. Par exemple, vous pouvez diviser un environnement de 20 000 hôtes en deux environnements de 10 000 hôtes avec une logique de requête qui sépare les hôtes par leurs noms. Alternativement, vous pourriez identifier des actifs/comptes critiques contenant les « pépites d’or » ou les « clés du royaume » et effectuer une analyse manuelle sur ceux-ci.
Il est possible de créer du contenu, de réviser des alertes et de trier des hôtes de manière assez efficace pour avoir du temps pour des techniques de chasse aux menaces plus manuelles.
Le contenu SIEM disponible dans le TDM de SOC Prime [5] est riche en contenu qui peut être complètement automatisé en tant qu’alertes ainsi qu’en contenu pour permettre des approches plus manuelles de la traque des menaces.
Ressources et remerciements pour les travaux précédents :
[1] https://github.com/mkorman90/sysmon-config-bypass-finder
[2] https://www.fireeye.com/blog/threat-research/2012/11/indepth-data-stacking.html
[3] https://socprime.com/blog/warming-up-using-attck-for-self-advancement/
[4] https://www.elastic.co/guide/en/kibana/current/field-filter.html
[5] https://tdm.socprime.com/login/


