Les équipes de sécurité ont besoin de méthodes plus rapides et plus flexibles pour détecter les menaces dans des environnements de données complexes. Les flux de données à haut volume rendent la détection difficile lorsque les opérations sont fragmentées entre plusieurs outils, que la réactivité aux incidents est limitée et que la gestion de grandes quantités de données est coûteuse.
Confluent Sigma répond à ces défis en permettant une stratégie de détection des menaces Shift-Left qui déplace la logique de détection hors du SIEM et dans la couche de traitement en flux. Cela permet aux équipes de sécurité de détecter les menaces plus près de la source et d’agir sur des signaux de haute fidélité pendant qu’une attaque se déroule, plutôt que d’attendre que les données soient normalisées, indexées et stockées.
Confluent Sigma utilise Kafka Streams pour exécuter des règles Sigma sur les données source avant qu’elles n’atteignent le SIEM. Sigma est la norme open-source, indépendante des fournisseurs, pour décrire les événements de journalisation. En appliquant des règles aux flux de données en direct, Confluent Sigma combine la portabilité de Sigma avec la vitesse et l’évolutivité d’Apache Kafka.
Ce guide vous accompagne dans l’installation de Confluent Sigma et présente des scénarios pratiques pour ses principaux cas d’utilisation, aidant les équipes de sécurité à adopter la Détection en tant que Code et à répondre aux menaces plus efficacement.
Pour les équipes de sécurité nécessitant une mise à l’échelle immédiate et des fonctionnalités d’entreprise avancées, SOC Prime Platform fournit une solution d’entreprise entièrement supportée, basée sur Confluent Sigma.
Modules Confluent Sigma & Logique de Traitement
Confluent Sigma se compose de trois modules principaux :
- sigma-parser: Une bibliothèque Java qui fournit la fonctionnalité de base pour lire et traiter les règles Sigma.
- sigma-streams-ui : Une interface utilisateur orientée développement pour interagir avec le processus Sigma Streams, permettant aux utilisateurs de voir les règles publiées, d’ajouter ou de modifier des règles, de surveiller les statuts des processeurs et de visualiser les détections.
- sigma-streams : Le module principal du projet, qui contient le processeur de flux réel et les scripts en ligne de commande associés.
Le processeur Sigma Streams exploite Kafka Streams pour appliquer efficacement la logique de détection basée sur le type de règle :
- Topologie Simple : Cette topologie supporte une sous-topologie pour de nombreuses règles et est utilisée pour des détections non-agrégantes basées sur un seul enregistrement d’événement. Le processeur utilise la fonction
flatMapValuesde Kafka Streams pour transformer les enregistrements. Il itère à travers chaque règle pour filtrer, valide les données en streaming par rapport à la règle DSL, et ajoute les résultats de la correspondance à une liste de sortie. Ce processus est très efficace, et l’enregistrement de détection final est envoyé immédiatement au sujet de sortie dynamique. - Topologie Agrégée : Cette topologie nécessite une sous-topologie pour chaque règle afin de gérer l’état et est utilisée pour des détections complexes et basées sur l’état impliquant des comptes ou des fenêtres temporelles. Pour les règles avancées, le processeur commence par valider les données et les groupe ensuite par une clé définie (par exemple,
id_orig_h). Il applique une fenêtre glissante de la règle (par exemple,timeframe: 10s), compte le nombre d’occurrences dans cette fenêtre, et enfin filtre en fonction de l’agrégation et de l’opération dans la règle (par exemple,count() > 10). L’enregistrement de détection agrégé final est ensuite envoyé au sujet de sortie dynamique.
Lorsqu’une correspondance se produit, l’événement de détection résultant est enrichi avant la sortie :
- Métadonnées de Règle : L’événement inclut la règle correspondante
title,author,product, etservice. - Cartographie des Champs : Si la règle utilise une expression régulière (regex), les champs extraits sont ajoutés à la sortie.
- Champs Personnalisés : Toute métadonnée personnalisée définie dans la règle est incluse pour le contexte et le routage aval.
- Sortie Dynamique : Le résultat est envoyé au sujet spécifié par le
outputTopicde la règle.
Comment Installer Confluent Sigma
Étape 1 : Commencer
Confluent Sigma repose sur trois sujets Kafka principaux pour fonctionner. Le processeur Sigma Streams surveille en continu ces sujets pour appliquer la logique et produire des détections.
- Sujet des règles : Contient les règles Sigma
- Sujet des données entrantes: Contient les données d’événements entrants (par exemple, des journaux).
- Sujet de sortie: Contient les événements qui ont correspondus à une ou plusieurs règles Sigma.
Les règles Sigma sont publiées dans un sujet Kafka dédié, que le processeur Sigma Streams surveille. Ces règles sont ensuite appliquées en temps réel aux données d’un autre sujet abonné. Tous les enregistrements correspondant aux règles sont transmis à un sujet de sortie désigné.
Remarque : Les trois sujets doivent être définis dans la configuration. Cependant, les règles peuvent remplacer la destination de sortie pour diriger vers différents sujets en fonction de la logique de règle spécifique.
Avant de commencer avec Confluent Sigma, assurez-vous d’avoir en place les éléments suivants :
- Environnement Kafka
- Un cluster Apache Kafka en cours d’exécution (local ou en production).
- Accès aux outils CLI de Kafka (kafka-topics, kafka-console-producer, kafka-console-consumer).
- Connexion réseau appropriée et permissions adéquates pour créer et gérer des sujets.
- Application Sigma Streams
- Téléchargez et installez l’application Confluent Sigma Streams.
- Assurez-vous que le script
bin/confluent-sigma.shest exécutable.
- Règles Sigma
- Fichiers de règles Sigma valides au format YAML ou JSON.
- Chaque règle doit suivre la spécification Sigma.
- Chargeur de Règles Sigma (optionnel)
- Installez l’utilitaire SigmaRuleLoader si vous prévoyez de charger des règles en masse.
- Fichiers de Configuration
Assurez-vous d’avoir un fichier de configuration sigma.properties valide avec :- Sujet des règles
- Sujet des données entrantes
- Sujet de sortie
- Paramètres du serveur de démarrage
Étape 2 : Création d’un Sujet de Règle Sigma
Avant d’ajouter une règle Sigma, assurez-vous de créer un sujet de règle Sigma. Voici un exemple de création d’un sujet de règle Sigma :kafka-topics --bootstrap-server localhost:9092 --topic sigma_rules --replication-factor 1 --partitions 1 --config cleanup.policy=compact --create
Remarque : Pour les déploiements en production, utilisez un facteur de réplication d’au moins 3. Étant donné que les règles sont relativement peu nombreuses par rapport aux données d’événements, une one partition est généralement suffisante.
Étape 3 : Chargement des Règles Sigma
Les règles Sigma sont stockées dans un sujet Kafka spécifié par l’utilisateur. Chaque clé d’enregistrement Kafka doit répondre aux exigences suivantes :
- Type :
string - Définie sur le champ titre de la règle
Remarque : La spécification Sigma ne nécessite pas de champ ID, les titres de règles doivent donc être uniques. Les règles nouvellement publiées ou mises à jour sont automatiquement détectées par un processeur Sigma Streams en cours d’exécution.
Les règles peuvent être ingérées dans Kafka en utilisant :
- l’application SigmaRuleLoader
- The l’outil en ligne de commande
kafka-console-producerIngestion de Règles via SigmaRuleLoader
Rule Ingestion via SigmaRuleLoader
L’application SigmaRuleLoader permet l’ingestion en masse ou individuelle de règles sous forme de fichiers YAML.
Pour charger un fichier de règle Sigma unique, utilisez l’option -file. Par exemple :sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -file zeek_sigma_rule.yml
Pour charger l’ensemble du répertoire contenant les règles Sigma, utilisez l’option -dir :sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -dir zeek_sigma_rules
Ingestion de Règles via CLI
Vous pouvez également charger manuellement des règles Sigma via un standard CLI Kafka, par exemple l’utilitaire l’outil en ligne de commande kafka-console-producer :kafka-console-producer --broker-list localhost:9092 --topic sigma-rules --property "key.separator=:"
Voici un extrait de code de l’ingestion de règle via CLI au format JSON :--property "key.separator=:"
{"title":Sigma Rule Test,"id":"123456789","status":"experimental","description":"This is just a test.", "author":"Test", "date":"1970/01/01","references":["https://confluent.io/"],"tags":["test.test"],"logsource": {"category":"process_creation","product":"windows"},"detection":{"selection":{"CommandLine|contains|all": [" /vss "," /y "]},"condition":"selection"},"fields":["CommandLine","ParentCommandLine"],"falsepositives": ["Administrative activity"],"level":"high"}
Étape 4 : Exécuter l’Application Sigma Streams
Le Confluent Sigma Streams est une application Java qui peut être exécutée directement ou via le script confluent-sigma.sh . Pour exécuter l’application via un script, utilisez la commande suivante :
bin/confluent-sigma.sh properties-file
Ordre de recherche de configuration pour Confluent Sigma Streams :
- Argument en ligne de commande (
properties-file). - Variable d’environnement
$SIGMAPROPS.
Remarque : Si vous ne spécifiez pas le properties-file, l’application vérifiera la variable Variable d’environnement $SIGMAPROPS.
- Si cette dernière n’est pas définie, l’application recherchera dans les répertoires suivants le fichier
properties-file:~/.config~/.confluent~/tmp
Voir les exemples de sigma.properties ici.
Recommandations de Mise en Œuvre
Rechargement à Chaud des Règles via un Sujet Kafka
Un défi opérationnel important est la mise à jour des règles de détection sans entraîner de temps d’arrêt. Redémarrer l’application de traitement de flux chaque fois qu’une règle Sigma est ajoutée ou modifiée est inefficace et entraîne des lacunes dans la couverture de détection.
- Recommandation : Créer un sujet Kafka dédié et compacté pour servir de « sujet de règles ». L’application confluent-sigma doit consommer de ce sujet en utilisant un GlobalKTable. Lorsqu’une nouvelle règle Sigma ou une règle mise à jour est publiée sur ce sujet (clés par un ID de règle unique), le GlobalKTable se mettra à jour automatiquement en quasi-temps réel. Le flux principal de traitement d’événements peut ensuite joindre contre ce GlobalKTable, garantissant qu’il dispose toujours du dernier ensemble de règles sans nécessiter un redémarrage.
- Impact : Cela permet un déploiement de règles sans interruption, permettant aux analystes de sécurité de réagir aux nouvelles menaces presque instantanément. Cela découple le cycle de gestion des règles du cycle de déploiement des applications.
Enrichir les Événements en Flux avant la Concordance des Règles
Les journaux de sécurité bruts manquent souvent du contexte nécessaire pour des alertes de haute fidélité. Par exemple, un journal brut pourrait contenir une adresse IP mais pas sa réputation, ou un ID utilisateur mais pas le département ou le rôle de l’utilisateur. Se fier au SIEM pour tout l’enrichissement peut retarder le contexte et créer des alertes plus bruyantes.
- Recommandation Spécifique : Avant la logique principale de concordance des règles Sigma, mettre en œuvre une phase d’enrichissement au sein de la topologie Kafka Streams. Utilisez des jointures stream-table pour enrichir le flux d’événements entrant.
- Renseignement sur les Menaces : Joindre le flux d’événements avec un GlobalKTable des IPs malveillantes connues, des domaines, ou des hachages de fichiers provenant d’un flux de renseignement sur les menaces.
- Informations Actif/Utilisateur : Joindre le flux d’événements avec un KTable peuplé à partir d’un CMDB ou d’un flux Active Directory pour ajouter des contextes tels que le propriétaire de l’appareil, la criticité du serveur ou le rôle de l’utilisateur.
- ImpactCela réduit considérablement les faux positifs and et augmente l’exactitude des priorités des alertes. Un événement impliquant un serveur critique ou un utilisateur privilégié peut être immédiatement escaladé. Cela rend également les alertes envoyées au SIEM beaucoup plus précieuses dès la sortie de la boîte.
Bonnes pratiques
Sujets Kafka Dédiés
- Isolation : Utiliser des sujets dédiés pour différents flux de données offre une isolation entre eux. Cela signifie qu’un problème avec un flux de données (par exemple, un pic soudain de trafic) est moins susceptible d’affecter les autres.
- Performance : Les sujets dédiés peuvent également améliorer la performance en vous permettant d’optimiser la configuration de chaque sujet pour son cas d’utilisation spécifique. Par exemple, vous pouvez définir un nombre différent de partitions ou un facteur de réplication différent pour chaque sujet.
Scalabilité
- Mise à l’Échelle Horizontale : L’application Confluent Sigma peut être mise à l’échelle horizontalement en exécutant plusieurs instances de l’application en parallèle. Chaque instance traitera un sous-ensemble des données, ce qui augmentera le débit global du système.
- Partitionnement : Pour permettre la mise à l’échelle horizontale, vous devez partitionner vos sujets Kafka. Cela permettra à plusieurs instances de l’application de consommer des données du même sujet en parallèle. Vous devez choisir une clé de partitionnement qui distribuera les données uniformément à travers les partitions.
- Groupes de Consommateurs : Lorsque vous exécutez plusieurs instances de l’application Confluent Sigma, vous devez les configurer pour qu’elles fassent partie du même groupe de consommateurs. Cela garantira que chaque message dans le sujet d’entrée est traité par une seule instance de l’application.
Cryptage
Vous devriez utiliser TLS/SSL pour chiffrer les données en transit entre les producteurs, les consommateurs et les courtiers Kafka. Cela protègera les données contre l’écoute et la falsification.
Surveillance
Il est crucial de surveiller la santé et la performance de l’application Confluent Sigma dans un environnement de production. Vous devriez surveiller les métriques suivantes :
- Le nombre de messages traités
- Le nombre d’alertes générées
- La latence de l’application
- L’utilisation du CPU et de la mémoire de l’application
Métriques Clés
En plus des métriques mentionnées précédemment, vous devriez également surveiller les éléments suivants :
- Retard du Consommateur : C’est le nombre de messages dans un sujet qui n’ont pas encore été traités par le consommateur. Un retard de consommateur élevé peut indiquer que l’application ne parvient pas à suivre le rythme des données entrantes.
- Latence de Fin à Fin : C’est le temps qu’il faut pour qu’un message voyage du producteur au consommateur. Une latence de fin à fin élevée peut indiquer un problème avec le réseau ou le cluster Kafka.
Cas d’Utilisation de Confluent Sigma
Confluent Sigma permet aux équipes de sécurité de détecter les menaces en temps réel en appliquant les règles Sigma directement aux flux Kafka, permettant ainsi aux ingénieurs de détection de répondre aux anomalies avant que les données n’atteignent le SIEM et de rationaliser le raffinement des règles.
Les principaux cas d’utilisation incluent les suivants :
- Détection de Menaces Shift-Left : Appliquer la logique de détection à la source, avant que les journaux n’atteignent le SIEM, permettant une réponse plus rapide aux attaques en cours.
- Mettre en Place une Pipeline CI/CD pour les Détections : Automatiser le déploiement et les mises à jour des règles à travers les environnements tout en améliorant l’efficacité et la cohérence opérationnelles.
- Versionner les Règles à Travers les Environnements : Maintenir une structuration des versions des règles en utilisant des sujets Kafka ou Git, garantissant la traçabilité et facilitant les retours en arrière.
- Réduire les Coûts d’Ingestion des Journaux : Détecter les menaces à la volée sans ingérer chaque journal dans le SIEM, réduisant ainsi les coûts de stockage et de traitement.
- Éliminer la Latence des Requêtes SIEM : Accéder instantanément à des détections de haute fidélité en traitant les règles dans des flux en temps réel.
- Accélérer la Vitesse de Corrélation : Appliquer la logique d’agrégation et de fenêtre glissante au sein de Kafka Streams pour corréler rapidement les événements et générer des alertes.
Confluent Sigma Propulsé par la Technologie SOC Prime
Bien que le projet open-source Confluent Sigma offre une base robuste pour la détection Shift-Left, son véritable potentiel en matière d’échelle et de couverture avancée des menaces est déverrouillé lorsqu’il est intégré à des solutions de niveau entreprise comme SOC Prime. La comparaison ci-dessous met en évidence comment les capacités de base évoluent pour répondre aux exigences des environnements à grande échelle et complexes.
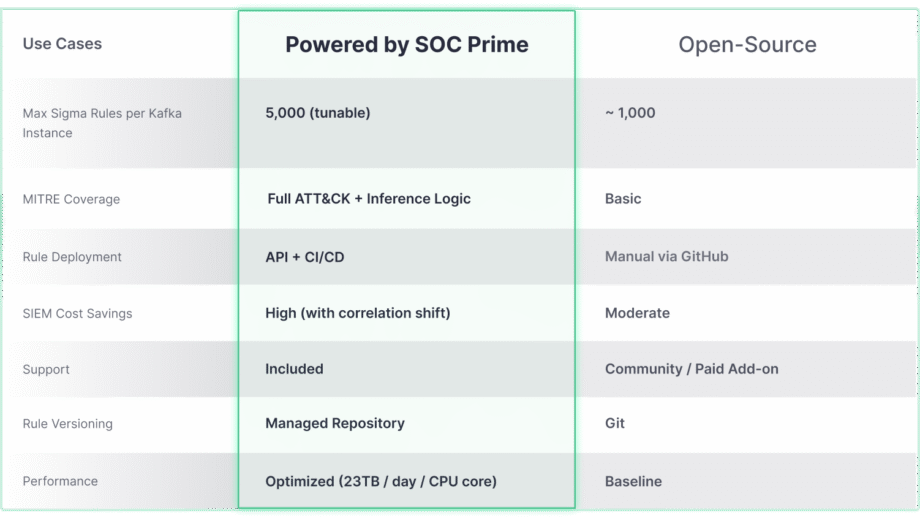
La solution Confluent Sigma & SOC Prime offre un accès direct aux outils et au contenu qui accélèrent considérablement le cycle de vie de la détection :
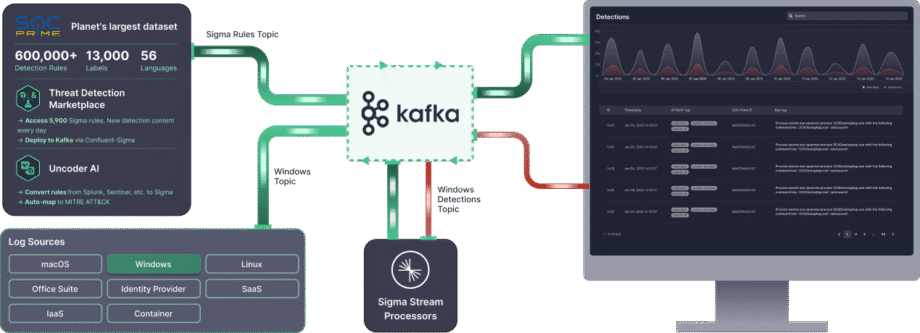
- Marketplace de Détection de Menaces : En tirant parti du Marketplace de Détection de Menaces, les équipes de sécurité peuvent choisir parmi plus de 15 000 règles Sigma qui traitent des menaces émergentes et les diffuser directement dans l’environnement Kafka de manière automatisée.
- Uncoder AI : Avec Uncoder AI de SOC Prime, un IDE et copilote pour l’ingénierie de détection de bout en bout, les défenseurs peuvent convertir du code de détection de plusieurs formats linguistiques en Sigma, le mapper automatiquement à MITRE ATT&CK, écrire du code à partir de zéro avec l’IA ou le modifier à la volée pour assurer une détection des menaces rationalisée..
- Excellence Opérationnelle : Le déploiement automatisé via API et CI/CD assure un déploiement de règles cohérent et reproductible, tandis que la performance à haut débit (jusqu’à 23 To/jour par cœur CPU) permet une détection des menaces en temps réel et à grande échelle dans n’importe quel environnement.
- Support Expert : Faites confiance à l’expertise technique de haut niveau de SOC Prime pour obtenir un support guidé sur l’installation, la gestion et l’évolutivité de la pile de détection open-source.