

Purpose:
With Elastic increasing their foothold in the cybersecurity space through the speed and scalability of their solution, we expect more new Elastic users. These users will approach Elastic armed with an intuition built from experience with other platforms and SIEMs. Often this intuition will be directly challenged after a few searches in Elastic. The purpose of this series is to get security analysts up to speed with the uniqueness of Elastic. This post provides readers with a guide for building proper searches against string data in Elastic.
Misunderstanding how the analyzed Text and non-analyzed Keyword datatypes affect searching string based data will lead to misleading results. By reading this post you will be better equipped to perform searches against strings that match your analytical intentions.
Outline:
- Before We Get Going
- Which Datatype are you Using?
- Summary of Differences
- Difference 1: Tokenizing & Terms
- Difference 2: Case Sensitivity
- Difference 3: Symbol Matching
Before We Get Going:
Lucene
This blog post uses Lucene. KQL doesn’t support regular expressions (yet) and we need them.
Terms: Datatypes, Mappings, and Analyzers:
When discussing how data is stored in Elastic’s indexes, one must be familiar with the terms Mappings, Datatypes, and Analyzers.
- Datatype – The “type”, “the type of data”, or “data type” that a value is stored/indexed as. Examples of datatypes are: String, Boolean, Integer, and IP. Strings are stored/indexed as a “Text” or “Keyword” datatype.
- Mapping – This is the setting that assigns (maps) each field to a datatype. Accessible through the get mapping API. When you “get the mapping” you are returned the field the datatype it is mapped to.
- Analyzer – before string data is stored/indexed, the value is pre-processed to optimize storage and searching. Analyzers help make searching against strings fast.
How Strings are Stored:
There are two primary datatypes for strings: Keyword and Text.
- Keyword – strings of the type Keyword are stored as their raw value. No analyzer is applied.
- Text – strings of the type Text are analyzed. The default and most common analyzer is the standard (text) analyzer. In this post when we refer to the “Text” datatype we are referring to the Text datatype with the standard analyzer. There are other analyzers, and custom analyzers are possible.
Which Datatype are you Using?
It is highly likely that your Elastic instance is using both the Text and Keyword datatypes for strings. However, the Elastic Common Schema (ECS) and Winlogbeat primarily use the Keyword datatype.
Even if you are using ECS, admins can customize mappings! To know for certain how a field is mapped, you should query your Elastic instance. To do this you can use the get field mapping API or get mapping API. It is good practice to keep up on the latest mappings for fields you regularly search or have built content against. Mappings can change while field names may stay the same. Restated, today’s Keyword field could be a Text field tomorrow.
The noteworthy differences between Keyword and Text are detailed in the section below. Additionally, each difference that will affect search results will be explored in their own section.
Summary of Differences
We don’t expect you to look at this section and immediately make sense of why the types match when they do. Each of the differences is expanded upon in their own section. Each of the examples in the tables is also placed in a table within the section that explains the behavior.
Differences
The following table provides a brief overview of the major differences in the datatypes.
| Difference | Standard (text) | Keyword |
| Tokenized | Split into terms (tokenized), original value lost but is faster | Not tokenized, original value maintained |
| Case Sensitivity | Case insensitive, case sensitive queries are not possible | Case sensitive, case insensitive queries possible via regex |
| Symbols | Generally, non-alphanumeric characters are not stored. But, retains non-alphanumeric characters in certain contexts | Retains non-alphanumeric characters / Retains symbols |
Differences in Behavior
The following table provides real world examples of how types affect search behavior.
| Example Value | Query | Text Match | Keyword Match |
| Powershell.exe –encoded TvqQAAMA | process.args:encoded | Yes | No |
| Powershell.exe –encoded TvqQAAMA | process.args:/.*[Ee][Nn][Cc][Oo][Dd][Ee][Dd].*/ | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:*Powershell.exe*Tvq* | No | Yes |
| TVqQAAMA | process.args:*TVqQAAMA* | Yes | Yes |
| TVqQAAMA | process.args:*tvqqaama* | Yes | No |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
| CmD.ExE | process.name:cmd.exe | Yes | No |
| CmD.ExE | process.name:/[Cc][Mm][Dd]\.[Ee][Xx][Ee]/ | Yes | Yes |
| \\*$\* | process.args:*\\\\*$* | No | Yes |
| \\C$\Windows\System32 | process.args:*C$\\* | Yes | Yes |
_
Difference 1: Analyzer, Tokenizing & Terms
Difference
| Difference | Text (standard analyzer) | Keyword |
| Tokenized | Split into terms (tokenized) | Not Analyzed, Not Tokenized. Original value maintained. |
Why…?
The Text datatype / standard analyzer uses tokenization which splits a string into chunks (tokens). These tokens are based upon word boundaries (ie: a space), punctuation. and more.
As an example if we tokenized the following string with the standard analyzer:
“searching for things with Elastic is straightforward”
The resulting terms would be:
“searching” | “for” | “thing” | “with” | “elastic” | “is” | “straightforward”
Notice everything was tokenized on spaces (word boundaries), is now lowercase, and the “s” was removed from things.
Tokenizing enables matching on single terms without contains or wildcards. For instance, if we performed a search for “Elastic” the Text datatype string containing “searching for things with Elastic is straightforward” would match. This is different from other SIEMs which rely heavily on wildcards or ‘contains’ logic.
However, tokenizing breaks on wildcards between terms. For instance, “*searching*Elastic*” would not match the standard analyzed string “searching with Elastic is straightforward”.
Note: You can address this with proximity, but order is not maintained. For example, “searching Elastic”~1 would match “searching with Elastic” and “Elastic with searching”.
Often times in security we need exact match and the ability to use wildcards between terms. This one reason the Keyword datatype has become the defacto datatype in ECS. For what you lose in speed you gain the ability to perform more precise searches.
Examples
| Example Value | Query | Text Match | Keyword Match |
| Powershell.exe –encoded | process.args:”Powershell.exe –encoded” | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:/.*[Ee][Nn][Cc][Oo][Dd][Ee][Dd].*/ | Yes | Yes |
| Powershell.exe –encoded TvqQAAMA | process.args:encoded | Yes | No |
| Powershell.exe –encoded TvqQAAMA | process.args:*Powershell.exe*encoded* | No | Yes |
_
Difference 2: Case Sensitivity
Difference
| Difference | Text (standard analyzer) | Keyword |
| Case Sensitivity | Stored entirely in lower case and is therefore case insensitive. Case sensitive queries are not possible. | Case sensitive. Case insensitive queries possible using regular expressions. |
Why…?
Case sensitivity issues are one of the leading causes for confusion in Elastic’s behavior as a security analyst. This is especially true for the Keyword datatype (hello ECS crowd). A single out-of-case character in a log can bypass an improperly built query against the Keyword fields. When an attacker controls parts of data that makes it into Keywords (think windows 4688 & 4104 events) you should be using regular expressions to ensure case insensitivity!
Furthermore, Elastic will not warn you if a document was barely missed because of a single out-of-case character. Therefore missing results or getting more results than intended is a leading cause for confusion as a security analyst.
Here is a basic example matching against “PoWeRsHeLl”. Notice how it only takes 1 out-of-case character to keep the query from matching.
| Example Value | Query | Text Match | Keyword Match |
| PoWeRsHeLl | process.args:PoWeRsHell | Yes | No |
| PoWeRsHeLl | process.args:PoWeRsHeLl | yes | yes |
| PoWeRsHeLl | process.args:/[Pp][Oo][Ww][Ee][Rr][Ss][Hh][Ee][Ll][Ll]/ | yes | Yes (matches all cases) |
For a real example in Kibana. In the image below, the Keyword type field “process.args” is queried for the string “windows”. To an unsuspecting analyst this may seem good enough… 42 results were returned. Well if they were hoping to obtain any document containing “windows” they would be wrong. As the search is case sensitive, therefore “Windows” would not match.
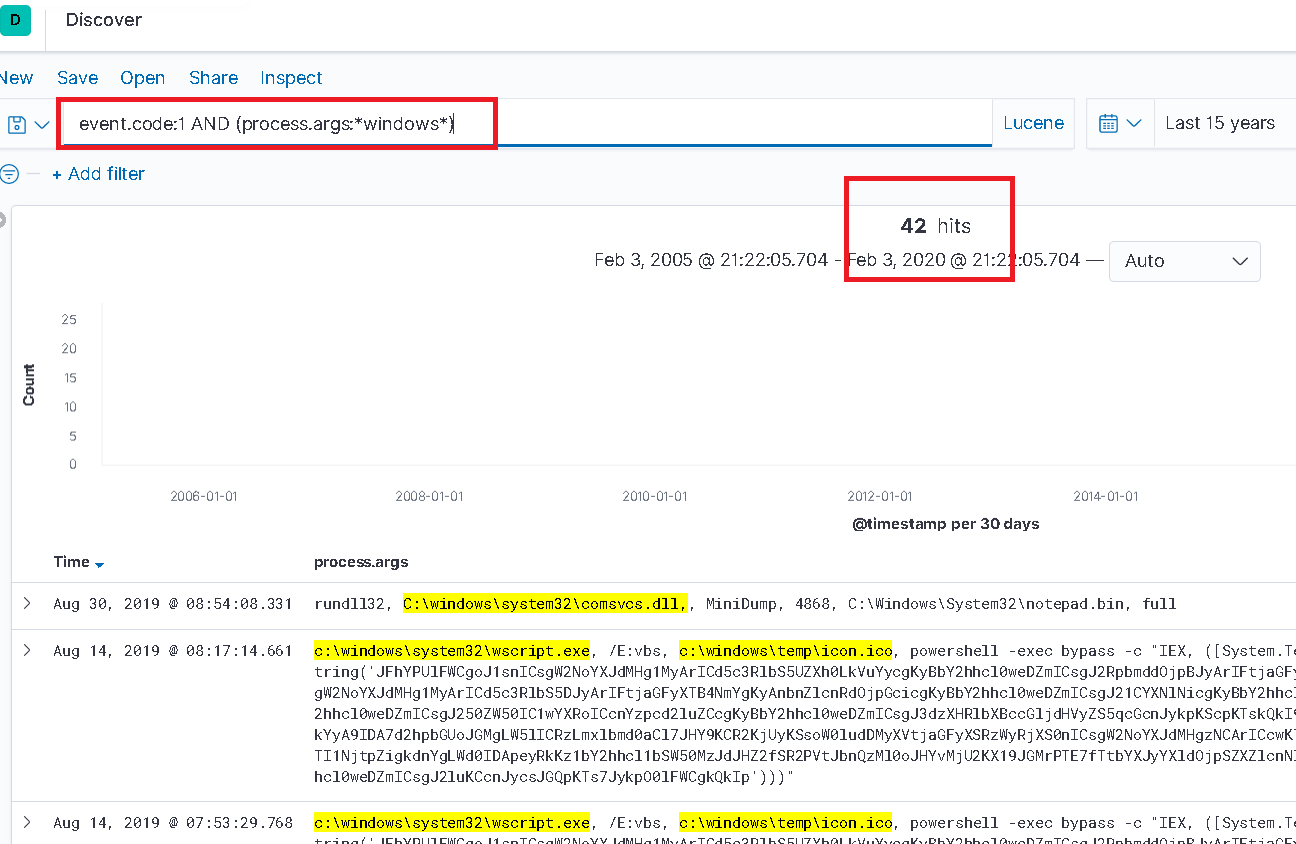
Limited results from case sensitive search
In the query below, using a regular expression to search for “windows” accordingly returns 567 results that were previously “missing”!
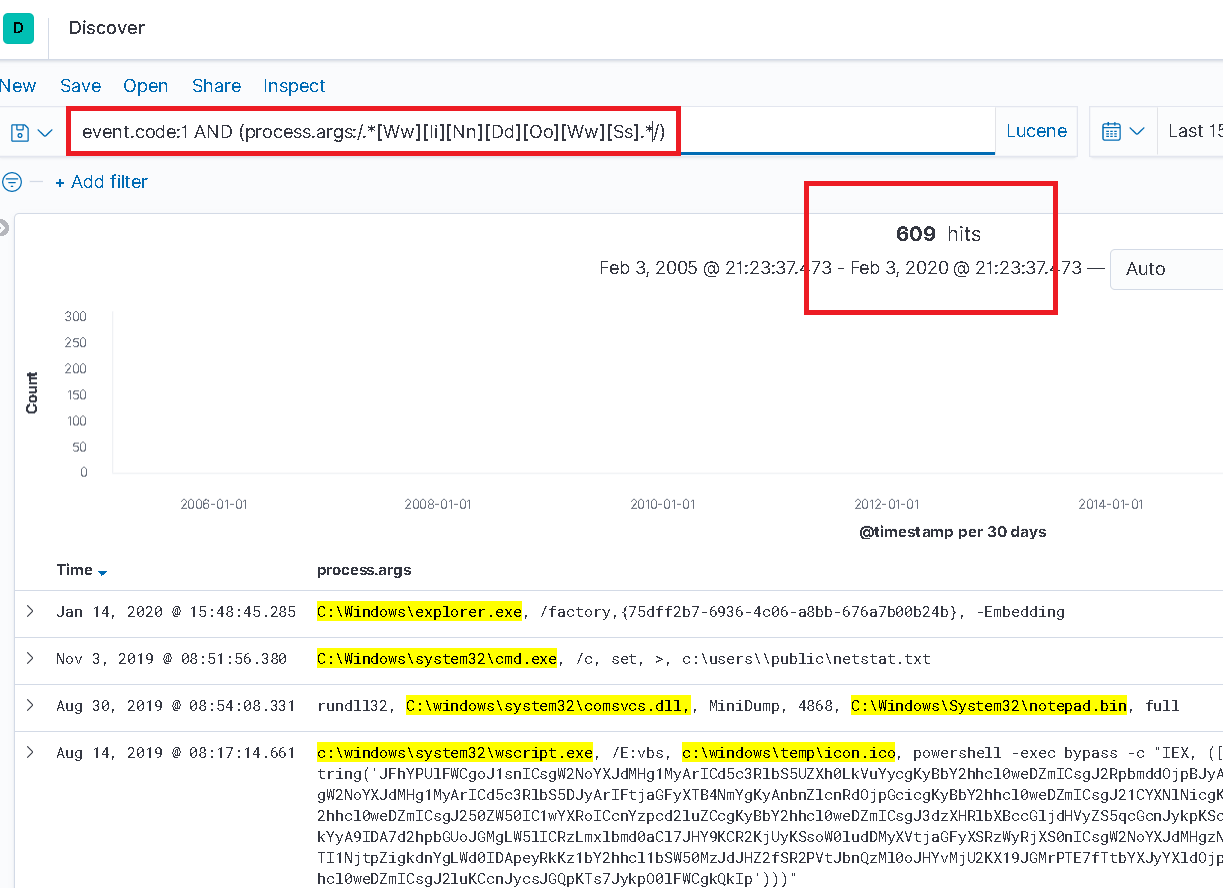
Maximum results
Hopefully it is now clear that if we are searching using the Keyword type and are not using a regular expression then we will miss variations of “powershell” beyond an exact match. Be warned against using KQL (which does not support regex) to match against data the attacker controls.
Note: There are use cases when you will want case sensitive matches in Keyword fields such as with base64.
You can make any query case insensitive using regex character sets. Here are examples:
| encoded | /[Ee][Nn][Cc][Oo][Dd][Ee][Dd]/ |
| cmd.exe | /[Cc][Mm][Dd]\.[Ee][Xx][Ee]/ |
| C:\windows\system32\* | /[Cc]:\\[Ww][Ii][Nn][Dd][Oo][Ww][Ss]\\[Ss][Yy][Ss][Tt][Ee][Mm]32\\.*/ |
Examples
| Example Value | Query | Text Match | Keyword Match |
| TVqQAAMA | process.args::*TVqQAAMA* | Yes | Yes |
| TVqQAAMA | process.args: *tvqqaama* | Yes | No |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
| CmD.ExE | process.name:cmd.exe | Yes | No |
| CmD.ExE | process.name:/[Cc][Mm][Dd]\.[Ee][Xx][Ee]/ | Yes | Yes |
_
Difference 3: Symbol Matching
Difference
| Difference | Text (standard analyzer) | Keyword |
| Symbols | Generally, non-alphanumeric characters are not stored. But, retains non-alphanumeric characters in certain contexts | Retains non-alphanumeric characters / Retains symbols |
Why?
All symbols are maintained by the Keyword type as the entire field is maintained exactly as the data is input (see note). However, for the standard analyzer a general rule to follow is that symbols will not be maintained. This is because the analyzer was made for whole word matching and symbols are not words. Restated, symbols are (for the most part) not stored in the standard analyzer. So, If you intend to match on symbols it’s best to use the Keyword datatype, if you only have a text field and need to match on a group of symbols you are out of luck. However, there are contexts when symbols will be maintained in the standard analyzer. For instance, periods will be maintained in terms like “cmd.exe”. The authors have found that the easiest way to understand when symbols will be maintained in the standard analyzer is to just run test data in the analyze API.
Examples
| Example Value | Query | Text Match | Keyword Match |
| \\*$\* | process.args:*\\\\*$* | No | Yes |
| \\C$\Windows\System32 | process.args:*C$\\* | Yes | Yes |
| cmd.exe | process.name:cmd.exe | Yes | Yes |
_
Conclusion
Elastic is a powerful tool. However, it can also be misleading. Hopefully we have armed you with a little more knowledge and the power to search confidently against string-based data.
If you feel that you need help writing content for Elastic, SOC Prime’s Threat Detection Marketplace is filled with detection content that works with our suggested Elastic configuration.
Future Posts
Stay tuned for further blog posts exploring the fundamentals & not so fundamentals of using Elastic as a security analyst.
Additional Resources for Searching:
This series focuses on the common pain points for analysts over delving into the topic of syntax. Elastic provides detailed documentation on their Lucene syntax. Also, there are several quality community cheat sheets: notably McAndre’s and Florian Roth and Thomas Patzke’s.
Meta:
Published – March 2020
Last Updated – 12 March
Authors – Adam Swan (@acalarch) with help from Nate Guagenti (@neu5ron)
Elastic Version Used: 7.5.2
Logs Used In Examples: https://github.com/sbousseaden/EVTX-ATTACK-SAMPLES


