Bedrohungsjagd Grundlagen: Manuelles Vorgehen

Inhaltsverzeichnis:
Ziel dieses Blogs ist es, die Notwendigkeit von manuellen (nicht alarmbasierten) Analysemethoden im Threat Hunting zu erklären. Ein Beispiel für eine effektive manuelle Analyse mittels Aggregationen/Stack Counting wird bereitgestellt.
Automatisierung ist notwendig
Automatisierung ist absolut entscheidend und als Threat Hunter müssen wir dort, wo es möglich ist, so viel wie möglich automatisieren.
Allerdings basiert Automatisierung auf Annahmen über Daten oder wie die Automatisierung in einer bestimmten Umgebung effektiv sein wird. Viele dieser Annahmen werden von anderen Analysten, Ingenieuren, Systembesitzern usw. für den Threat Hunter getroffen. Ein häufiges Beispiel ist das Whitelisting von Prozesserstellungsereignissen von System Center Configuration Manager (SCCM) oder anderen Endpoint-Management-Produkten in alarmbasierten Erkennungen. Ein weiteres Beispiel sind SIEM-Ingenieure, die ungenutzte Logs herausfiltern, um Ressourcen zu sparen. Angreifer sind zunehmend darauf bedacht, solche Annahmen zu identifizieren und sich innerhalb dieser verborgen zu halten. Beispielsweise wurden Tools entwickelt, um Schwachstellen in der Sysmon-Konfiguration eines Systems zu identifizieren [1].
Indem sie die Schichten der Annahmen zurückziehen und inspizieren, können Threat Hunters möglicherweise Erfolg darin haben, Lücken in der Sichtbarkeit zu identifizieren und auf diesen Lücken zu jagen, um einen Kompromiss aufzudecken. Dieser Blogbeitrag konzentriert sich darauf, einige dieser Annahmen zu beseitigen, indem Aggregationen verwendet werden, um interessante Daten effizient manuell zu überprüfen.
Manuelle Ansätze sind notwendig
Vielleicht ist das dominierende Prinzip beim Threat Hunting „Kompromiss annehmen“. Die Reaktion auf einen Kompromiss beinhaltet (fast) immer manuelle menschliche Analyse und Intervention, insbesondere während des Scopings. Effektives Scoping beinhaltet nicht nur das Überprüfen von Alerts. Effektives Scoping beinhaltet die manuelle Analyse bekannter kompromittierter Hosts nach Indikatoren und Verhaltensweisen, die im Rest der Umgebung durchsucht werden können. Daher ist, wenn wir als Threat Hunter einen „Kompromiss annehmen“, eine manuelle Analyse von Natur aus erforderlich.
Ein anderer Blick darauf ist, dass wir, indem wir nur auf alarmbasierte Daten prüfen, annehmen, dass ein erfolgreicher Angreifer mindestens eine Regel/einen Alarm in unserer Umgebung auslösen wird, der klar und handlungsfähig genug ist, um eine Entscheidung zu treffen, die zur Identifizierung des Kompromisses führt.
Das bedeutet jedoch nicht, dass Threat Hunter sich mit der manuellen Analyse jedes Protokolls für jede Datenquelle in der Umgebung belasten sollten. Stattdessen müssen wir einen Weg finden, um relevante Daten zu überprüfen und Entscheidungen so effektiv wie möglich zu treffen.
Das Zurückziehen der Logik, die wir für das Alarming verwenden, und das Aggregieren der Felder und Kontexte, die wir in unserem Alarming verwenden, ist ein Beispiel für eine effektive manuelle Analyse für die meisten Umgebungen.
Aggregation als Beispiel (Stack Counting)
Einer der einfachsten und effektivsten Ansätze für manuelles Hunting ist das Aggregieren von interessanten/umsetzbaren Feldern bei der passiven Datenerfassung in einem bestimmten Kontext.
Wenn Sie jemals die Pivot-Tabellen von Microsoft Office, den Befehl „stats“ von Splunk oder den „top“-Befehl von Arcsight verwendet haben, kennen Sie dieses Konzept.Hinweis: Diese Technik wird auch häufig als Stack Counting, Daten-Stacking, Stacking oder Pivot-Tabellen bezeichnet :). Ich glaube, dass sich unerfahrene Hunter eher mit dem Konzept der Aggregation vertraut fühlen, daher verwende ich diesen Begriff hier. Fireeye scheint das erste Unternehmen zu sein, das dieses Konzept im Kontext des Threat Hunting veröffentlicht hat [2].
Hinweis: Passive Daten sind eine Datenquelle, die Ihnen über ein Ereignis berichtet, unabhängig davon, ob es für die Sicherheit relevant ist oder nicht. Beispielsweise könnte eine passive Datenquelle Ihnen mitteilen, dass ein Prozess erstellt wurde, eine Netzwerkverbindung hergestellt wurde, eine Datei gelesen/geschrieben wurde usw. Hostprotokolle, wie Windows Event Logs, sind großartige Beispiele für eine passive Datenquelle. Passive Datenquellen sind ein wichtiger Bestandteil des Rückgrats der meisten Threat Hunting Programme.Zum Beispiel zeigt Bild 1 einen Teil einer Aggregation aller Sysmon-Netzwerkverbindungsereignisse mit dem Zielport 22 (SSH) in einer Umgebung über 30 Tage. Ein Threat Hunter könnte diese Aggregation nutzen, um Prozesse zu ‚jagen‘, die normalerweise nicht mit Verbindungen über Port 22 in Verbindung gebracht werden.
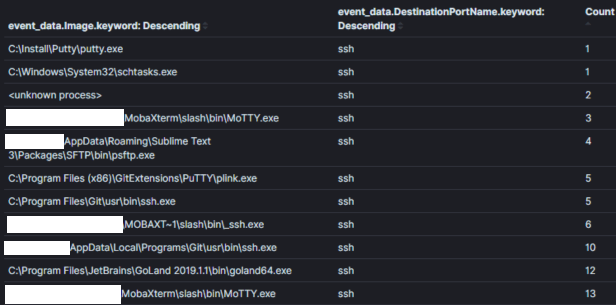 Bild 1: Einfache Aggregation in Kibana
Bild 1: Einfache Aggregation in Kibana
Bild Eins:
Aggregationsfeld: ProzessnameKontext: Prozesse, die Port 22 innerhalb von 30 Tagen verwendenErgebnisse: 120Zeit zur Analyse: < 1 minKontext ist im Jagdbereich mit Aggregationen König, da er die Absicht Ihrer Suchhypothese enthält. Der Kontext einer Aggregation wird typischerweise in der zugrunde liegenden Abfrage festgelegt und dem Analysten über die Felder, auf denen wir aggregieren und die wir beobachten, zugänglich gemacht. In Bild 1 wird der Kontext „Prozesse, die Port 22 verwenden“ in die Abfragelogik (symon_eid == 3 UND Zielport == 22) konvertiert und durch Aggregation/Darstellung des Feldes, das die Prozessnamen enthält.
Es ist wichtig, ein Gleichgewicht zwischen einem engen oder einem breiten Kontext innerhalb einer Aggregation zu finden. Zum Beispiel habe ich in Bild 2 den Kontext vom vorherigen Bild erweitert, um alle Prozesse mit Netzwerkverbindungen zurückzugeben. Es ist möglich, in diesem Kontext Böses zu finden, jedoch wird es schwieriger, Entscheidungen über die Daten zu treffen, es sei denn, es gibt einen offensichtlich ungewöhnlichen Prozessnamen oder einen Prozess, der eigentlich keine Netzwerkaktivität haben sollte (was zunehmend seltener wird).Bild 2:
Aggregationsfeld: ProzessnameKontext: Prozesse mit NetzwerkverbindungenErgebnisse: 1000+Zeit zur Analyse: 1 min
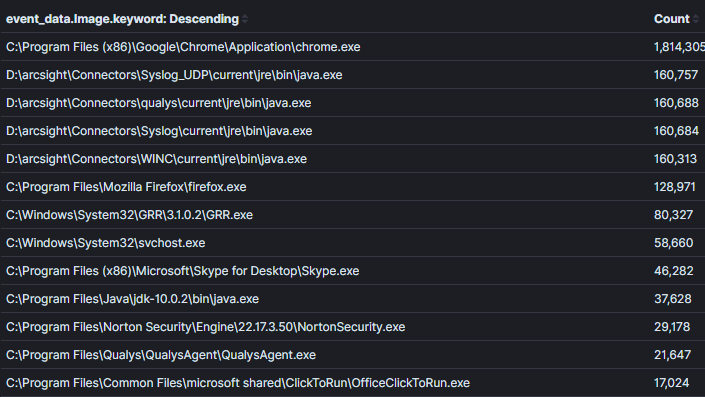 Bild 2: Eine weniger effektive Aggregation ohne ausreichenden KontextSchließlich werden Aggregationen weniger effektiv, wenn Felder aggregiert werden, die nicht für Entscheidungen verwendet werden sollen. In Bild 3 habe ich das Feld „Prozess-ID“ zur letzten Aggregation hinzugefügt. Die Kenntnis der Prozess-ID kann nützlich sein, sobald wir einen ungewöhnlichen Prozess identifizieren, jedoch entsteht dadurch ein doppelter Eintrag für jede einzigartige Kombination aus Prozessname und ID. In diesem Laufbeispiel vervierfachten sich die Ergebnisse mehr als und viele Prozessnamen wurden dupliziert. Es ist wichtig, auf Feldern zu aggregieren, die Ihnen ermöglichen, Entscheidungen zu treffen. Informationen, die möglicherweise erforderlich sind, um einen spezifischen Host oder Benutzer zur Triage zu identifizieren, sollten mithilfe einer zusätzlichen Abfrage mit engem Kontext identifiziert werden. Im Beispiel von Bild 1, wenn wir identifizieren möchten, wer Putty für SSH verwendet hat, können wir die Logik verwenden (process_name==”*putty.exe” UND sysmon_eid==3). Meiner Meinung nach ist dies ein Bereich, in dem Kibana andere von mir verwendete Analysetools übertrifft, da das Pivotieren zwischen Abfragen und Dashboards über ihr anheftbares Filtersystem hoch effizient ist [4].
Bild 2: Eine weniger effektive Aggregation ohne ausreichenden KontextSchließlich werden Aggregationen weniger effektiv, wenn Felder aggregiert werden, die nicht für Entscheidungen verwendet werden sollen. In Bild 3 habe ich das Feld „Prozess-ID“ zur letzten Aggregation hinzugefügt. Die Kenntnis der Prozess-ID kann nützlich sein, sobald wir einen ungewöhnlichen Prozess identifizieren, jedoch entsteht dadurch ein doppelter Eintrag für jede einzigartige Kombination aus Prozessname und ID. In diesem Laufbeispiel vervierfachten sich die Ergebnisse mehr als und viele Prozessnamen wurden dupliziert. Es ist wichtig, auf Feldern zu aggregieren, die Ihnen ermöglichen, Entscheidungen zu treffen. Informationen, die möglicherweise erforderlich sind, um einen spezifischen Host oder Benutzer zur Triage zu identifizieren, sollten mithilfe einer zusätzlichen Abfrage mit engem Kontext identifiziert werden. Im Beispiel von Bild 1, wenn wir identifizieren möchten, wer Putty für SSH verwendet hat, können wir die Logik verwenden (process_name==”*putty.exe” UND sysmon_eid==3). Meiner Meinung nach ist dies ein Bereich, in dem Kibana andere von mir verwendete Analysetools übertrifft, da das Pivotieren zwischen Abfragen und Dashboards über ihr anheftbares Filtersystem hoch effizient ist [4].
Bild 3:
Aggregationsfeld: Prozessname + Prozess-IDKontext: Prozesse mit NetzwerkverbindungenErgebnisse: 1000+Zeit zur Analyse: 10 min
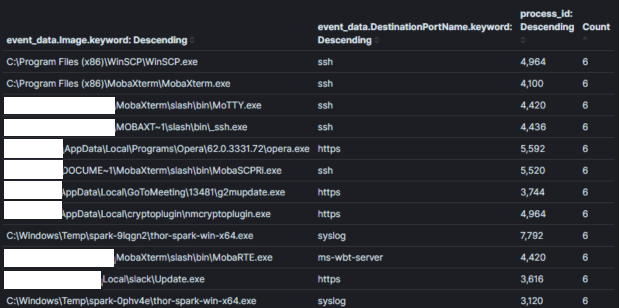 Bild 3: Eine weniger effektive Aggregation mit nicht-kontextuellen Feldern
Bild 3: Eine weniger effektive Aggregation mit nicht-kontextuellen Feldern
Hinweis: In bestimmten Systemen wie Elasticsearchs Kibana ist es einfach, von einer Datentabelle zu einer anderen über deren Dashboards zu pivotieren. Andernfalls wechselt ein Analyst, nachdem er eine interessante Aggregation identifiziert hat, typischerweise zur Überprüfung der Hosts oder Konten, die das interessante Verhalten gezeigt haben.
Hinweis: Sie sollten sich der Falle der Ausreißererkennung bewusst sein. Verlassen Sie sich nicht auf das Konzept von „gewöhnlich ist gut“ und „ungewöhnlich ist schlecht“ bei Aggregationen/Stack Counting. Dies ist nicht unbedingt wahr, da Kompromisse in der Regel mehrere Maschinen betreffen und Gegner versuchen können, diese Annahme auszunutzen, um Lärm zu erzeugen und normal zu erscheinen. Darüber hinaus existieren in fast jeder Umgebung Nischen-Software und Anwendungsfälle. Es ist leicht, sich in der Triagierung jedes „am wenigsten häufigen“ Stacks zu verfangen und Zeit damit zu verschwenden, false positives zu identifizieren. Das Kennen der Umgebung vor dem Kompromiss und das Schärfen Ihrer Instinkte über das Verhalten von Bedrohungsakteuren [3] wird Ihnen hier helfen.
Aber ist es skalierbar?
Die manuelle Analyse von Logs skaliert bei weitem nicht so gut wie das Alarming, da ein Analyst in der Regel nur einen einzelnen Kontext zu einer Zeit beobachtet. Zum Beispiel ist es üblich, eine einzige Aggregation mit zehntausenden oder sogar hunderttausenden Ergebnissen zu überprüfen. Die längste Zeit, die Sie sich für die Überprüfung einer Aggregation nehmen sollten, sind wahrscheinlich 10 Minuten. Falls Sie sich als Threat Hunter überfordert fühlen, könnte es helfen, den Kontext zu verengen. Zum Beispiel können Sie eine Umgebung mit 20.000 Hosts in zwei Umgebungen mit je 10.000 Hosts aufteilen, indem Sie Abfragelogik verwenden, die Hosts nach ihren Namen trennt. Alternativ können Sie kritische Assets/Konten identifizieren, die die „goldenen Nuggets“ oder „Schlüssel zum Königreich“ enthalten, und diese manuell analysieren.
Es ist möglich, Inhalte zu erstellen, Alerts zu überprüfen und Hosts effizient genug zu triagieren, um Zeit für mehr manuelle Threat Hunting-Techniken zu haben.
Die SIEM-Inhalte, die in SOC Primes TDM [5] verfügbar sind, sind reich an Inhalten, die vollständig als Alarming automatisiert werden können und auch Inhalte enthalten, die manuelle Ansätze zum Threat Hunting ermöglichen.
Ressourcen und Erwähnungen zu vorherigen Arbeiten:
[1] https://github.com/mkorman90/sysmon-config-bypass-finder
[2] https://www.fireeye.com/blog/threat-research/2012/11/indepth-data-stacking.html
[3] https://socprime.com/blog/warming-up-using-attck-for-self-advancement/
[4] https://www.elastic.co/guide/en/kibana/current/field-filter.html
[5] https://tdm.socprime.com/login/


