Sicherheitsteams benötigen schnellere und flexiblere Möglichkeiten, Bedrohungen in komplexen Datenumgebungen zu erkennen. Datenströme mit hohem Volumen machen die Erkennung schwierig, wenn der Betrieb auf mehrere Tools fragmentiert ist, die Agilität bei der Reaktionsfähigkeit auf Vorfälle eingeschränkt ist und die Verwaltung großer Datensätze teuer ist.
Confluent Sigma begegnet diesen Herausforderungen, indem es eine Shift-Left-Bedrohungserkennungsstrategie ermöglicht, die die Erkennungslogik aus dem SIEM herausnimmt und in die Stream-Verarbeitungsebene verlagert. Dadurch können Sicherheitsteams Bedrohungen näher an der Quelle erkennen und auf hochqualitative Signale reagieren, während ein Angriff stattfindet, anstatt zu warten, bis Daten normalisiert, indexiert und gespeichert sind.
Confluent Sigma verwendet Kafka Streams , um Sigma-Regeln auf Quelldaten anzuwenden, bevor sie das SIEM erreichen. Sigma ist der quelloffene, herstellerunabhängige Standard zur Beschreibung von Log-Ereignissen. Indem Regeln auf Live-Datenströme angewendet werden, kombiniert Confluent Sigma die Portabilität von Sigma mit der Geschwindigkeit und Skalierbarkeit von Apache Kafka.
Dieser Leitfaden führt Sie durch die Installation von Confluent Sigma und präsentiert praktische Szenarien für dessen Hauptanwendungsfälle, um Sicherheitsteams zu helfen, Detection as Code zu übernehmen und effektiver auf Bedrohungen zu reagieren.
Für Sicherheitsteams, die sofortige Skalierbarkeit und fortschrittliche Enterprise-Funktionen benötigen, SOC Prime Platform bietet eine vollständig unterstützte, unternehmensreife Lösung basierend auf Confluent Sigma.
Confluent Sigma Module & Verarbeitungslogik
Confluent Sigma besteht aus drei Hauptmodulen:
- sigma-parser: Eine Java-Bibliothek, die die Kernfunktionalität zum Lesen und Verarbeiten von Sigma-Regeln bereitstellt.
- sigma-streams-ui: Eine entwicklungsorientierte Benutzeroberfläche für die Interaktion mit dem Sigma-Streams-Prozess, die es Benutzern ermöglicht, veröffentlichte Regeln anzuzeigen, Regeln hinzuzufügen oder zu bearbeiten, Prozessorstatus zu überwachen und Erkennungen zu visualisieren.
- sigma-streams: Das Hauptmodul des Projekts, das den eigentlichen Stream-Prozessor und zugehörige Kommandozeilenskripte enthält.
Der Sigma Streams-Prozessor nutzt Kafka Streams, um Erkennungslogik basierend auf dem Regeltyp effizient anzuwenden:
- Einfaches Topology: Diese Topologie unterstützt eine Sub-Topologie für viele Regeln und wird für nicht-aggregierende Erkennungen basierend auf einem einzelnen Ereigniseintrag verwendet. Der Prozessor verwendet die
flatMapValues-Funktion von Kafka Streams, um Datensätze zu transformieren. Er iteriert durch jede Regel für die Filterung, validiert die Streaming-Daten gegen die DSL-Regel und fügt die Übereinstimmungsergebnisse einer Ausgabeliste hinzu. Dieser Prozess ist sehr effizient, und der endgültige Erkennungsdatensatz wird sofort an das dynamische Ausgabethema gesendet. - Aggregierte Topologie: Diese Topologie erfordert eine Sub-Topologie für jede Regel zur Zustandsverwaltung und wird für komplexe, zustandsbehaftete Erkennungen verwendet, die Zählungen oder Zeitfenster beinhalten. Für fortgeschrittene Regeln validiert der Prozessor zuerst die Daten und gruppiert sie dann nach einem definierten Schlüssel (z. B.
id_orig_h). Es wird ein Gleitfenster aus der Regel angewendet (z. B.timeframe: 10s), die Anzahl der Instanzen innerhalb dieses Fensters gezählt und schließlich basierend auf der Aggregation und Operation in der Regel gefiltert (z. B.count() > 10). Der final aggregierte Erkennungsdatensatz wird dann an das dynamische Ausgabethema gesendet.
Wenn eine Übereinstimmung auftritt, wird das resultierende Erkennungsereignis vor der Ausgabe angereichert:
- Regel-Metadaten: Das Ereignis enthält die Übereinstimmungsregel
title,author,product, undservice. - Feldzuordnung: Wenn die Regel einen regulären Ausdruck (Regex) verwendet, werden die extrahierten Felder der Ausgabe hinzugefügt.
- Benutzerdefinierte Felder: Jede in der Regel definierte benutzerdefinierte Metadaten werden für Kontexte und die nachgelagerte Weiterleitung eingefügt.
- Dynamische Ausgabe: Das Ergebnis wird an das im Feld
outputTopicder Regel festgelegte Thema gesendet.
Wie man Confluent Sigma installiert
Schritt 1: Erste Schritte
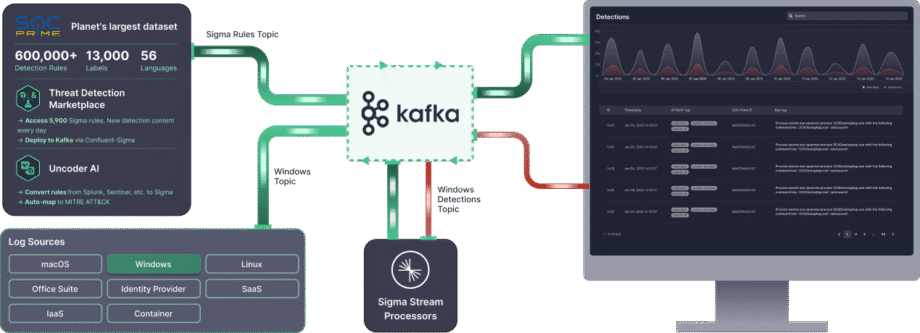
Confluent Sigma ist auf drei Haupt-Kafka-Themen angewiesen, um zu funktionieren. Der Sigma Streams-Prozessor überwacht diese Themen kontinuierlich, um Logik anzuwenden und Erkennungen auszugeben.
- Regel-Thema: Enthält Sigma-Regeln
- Eingabedaten-Thema: Enthält eingehende Ereignisdaten (z. B. Logs).
- Ausgabe-Thema: Enthält Ereignisse, die mit einer oder mehreren Sigma-Regeln übereinstimmten.
Sigma-Regeln werden in ein dediziertes Kafka-Thema veröffentlicht, das der Sigma Streams-Prozessor überwacht. Diese Regeln werden dann in Echtzeit auf Daten aus einem anderen abonnierten Thema angewendet. Alle den Regeln entsprechenden Datensätze werden an ein bestimmtes Ausgabethema weitergeleitet.
Hinweis: Alle drei Themen müssen in der Konfiguration definiert sein. Regeln können jedoch das Ausgabenziel überschreiben, um basierend auf der spezifischen Logik der Regel zu verschiedenen Themen weiterzuleiten.
Bevor Sie mit Confluent Sigma beginnen, stellen Sie sicher, dass Sie Folgendes bereit haben:
- Kafka Umgebung
- Ein laufender Apache Kafka-Cluster (lokal oder in Produktion).
- Zugriff auf Kafka-CLI-Tools (kafka-topics, kafka-console-producer, kafka-console-consumer).
- Eine ordnungsgemäße Netzwerkverbindung und entsprechende Berechtigungen zum Erstellen und Verwalten von Themen.
- Sigma Streams-Anwendung
- Laden Sie die Confluent Sigma Streams-Anwendung herunter und installieren Sie sie.
- Stellen Sie sicher, dass das
bin/confluent-sigma.sh-Skript ausführbar ist.
- Sigma-Regeln
- Gültige Sigma-Regeldateien im YAML- oder JSON-Format.
- Jede Regel sollte der Sigma-Spezifikation.
- Sigma Rule Loader (optional)
- Installieren Sie das SigmaRuleLoader-Dienstprogramm, wenn Sie Regeln in großer Menge laden möchten.
- Konfigurationsdateien
Stellen Sie sicher, dass Sie über eine gültige sigma.properties-Konfigurationsdatei mit folgenden Inhalten verfügen:- Regel-Thema
- Eingabedaten-Thema
- Ausgabe-Thema
- Bootstrap-Server-Einstellungen
Schritt 2: Erstellen eines Sigma-Regel-Themas
Bevor Sie eine Sigma-Regel hinzufügen, erstellen Sie ein Sigma-Regel-Thema. Unten sehen Sie ein Beispiel dafür, wie Sie ein Sigma-Regel-Thema erstellen:kafka-topics --bootstrap-server localhost:9092 --topic sigma_rules --replication-factor 1 --partitions 1 --config cleanup.policy=compact --create
Hinweis: Für Produktionsbereitstellungen verwenden Sie einen Replikationsfaktor von mindestens 3. Da Regeln im Vergleich zu Ereignisdaten relativ wenige sind, reicht one Partition typischerweise aus.
Schritt 3. Laden von Sigma-Regeln
Sigma-Regeln werden in einem vom Benutzer festgelegten Kafka-Thema gespeichert. Der Schlüssel jedes Kafka-Datensatzes sollte die folgenden Anforderungen erfüllen:
- Typ:
string - Festlegen auf das Titelfeld der Regel
Hinweis: Die Sigma-Spezifikation erfordert kein ID-Feld, daher müssen Regel-Titel eindeutig sein. Neu veröffentlichte oder aktualisierte Regeln werden von einem laufenden Sigma Streams-Prozessor automatisch aufgenommen.
Regeln können in Kafka ingestiert werden über:
- SigmaRuleLoader-Anwendung
- The
kafka-console-producer-Kommandozeilen-Tool
Regel-Ingestion über SigmaRuleLoader
Die SigmaRuleLoader-Anwendung ermöglicht das großvolumige oder Einzelregel-Ingestieren als YAML-Dateien.
Um eine einzelne Sigma-Regeldatei zu laden, verwenden Sie die Option -file. Zum Beispiel:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -file zeek_sigma_rule.yml
Um das gesamte Verzeichnis mit Sigma-Regeln zu laden, verwenden Sie die Option -dir:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -dir zeek_sigma_rules
Regel-Ingestion über CLI
Sie können Sigma-Regeln auch manuell über eine Standard-Kafka-CLI laden, zum Beispiel das kafka-console-producer Dienstprogramm:kafka-console-producer --broker-list localhost:9092 --topic sigma-rules --property "key.separator=:"
Hier ist ein Code-Schnipsel zur Regel-Ingestion über CLI im JSON-Format:--property "key.separator=:"
{"title":Sigma Rule Test,"id":"123456789","status":"experimental","description":"This is just a test.", "author":"Test", "date":"1970/01/01","references":["https://confluent.io/"],"tags":["test.test"],"logsource": {"category":"process_creation","product":"windows"},"detection":{"selection":{"CommandLine|contains|all": [" /vss "," /y "]},"condition":"selection"},"fields":["CommandLine","ParentCommandLine"],"falsepositives": ["Administrative activity"],"level":"high"}
Schritt 4. Ausführen der Sigma Streams-Anwendung
Die Confluent Sigma Streams ist eine Java-Anwendung, die direkt oder über das confluent-sigma.sh -Skript ausgeführt werden kann. Um die Anwendung über ein Skript auszuführen, verwenden Sie den folgenden Befehl:
bin/confluent-sigma.sh properties-file
Confluent Sigma Streams Konfigurations-Suchreihenfolge:
- Kommandozeilenargument (
properties-file). $SIGMAPROPSUmgebungsvariable.
Hinweis: Wenn Sie die properties-filenicht angeben, überprüft die Anwendung die $SIGMAPROPS Variable.
- Wenn die erstere nicht gesetzt ist, sucht die App in den folgenden Verzeichnissen nach der
properties-file:~/.config~/.confluent~/tmp
Sehen Sie die Beispiele von sigma.properties hier.
Umsetzungsempfehlungen
Regel-Hot-Reloading über ein Kafka-Thema
Eine bedeutende betriebliche Herausforderung besteht darin, Erkennungsregeln zu aktualisieren, ohne Ausfallzeiten zu verursachen. Das Neustarten der Stream-Verarbeitungsanwendung jedes Mal, wenn eine Sigma-Regel hinzugefügt oder geändert wird, ist ineffizient und führt zu Lücken in der Erkennungsabdeckung.
- Empfehlung: Erstellen Sie ein dediziertes, kompaktiertes Kafka-Thema als „Regel-Thema“. Die Confluent-Sigma-Anwendung sollte dieses Thema mit einem GlobalKTable konsumieren. Wenn eine neue oder aktualisierte Sigma-Regel in dieses Thema veröffentlicht wird (Schlüssel durch eine eindeutige Regel-ID), wird die GlobalKTable automatisch in nahezu Echtzeit aktualisiert. Der Hauptereignisverarbeitungsstream kann dann gegen diese GlobalKTable verbinden, sodass er immer den neuesten Satz von Regeln hat, ohne einen Neustart zu benötigen.
- Auswirkung: Dies ermöglicht eine unterbrechungsfreie Regelbereitstellung, sodass Sicherheitsanalysten fast sofort auf neue Bedrohungen reagieren können. Es entkoppelt den Regelverwaltungslebenszyklus vom Anwendungsbereitstellungslebenszyklus.
Ereignisse im Stream anreichern, bevor die Regelanpassung erfolgt
Roh-Sicherheitsprotokolle fehlen oft der Kontext, der für hochwertige Alarme erforderlich ist. Zum Beispiel könnte ein Roh-Protokoll eine IP-Adresse enthalten, aber nicht deren Ruf, oder eine Benutzer-ID, aber nicht die Abteilung oder Rolle des Benutzers. Wenn man sich allein auf das SIEM für die Anreicherung stützt, kann der Kontext verzögern und lautere Alarme erzeugen.
- Spezifische Empfehlung: Implementieren Sie eine Anreicherungsphase innerhalb der Kafka Streams-Topologie vor der primären Sigma-Regelanpassungslogik. Verwenden Sie Stream-Table Joins um den eingehenden Ereignisstrom anzureichern.
- Bedrohungsinformationen: Verbinden Sie den Ereignisstrom mit einem GlobalKTable von bekannten bösartigen IPs, Domains oder Dateihashes, die von einem Bedrohungsinformationsfeed geladen werden.
- Asset-/Benutzerinformationen: Verbinden Sie den Ereignisstrom mit einem KTable, das von einem CMDB- oder Active Directory-Feed bevölkert wird, um Kontext wie Gerätebesitzer, Server-Kritikalität oder Benutzerrolle zu verknüpfen.
- Auswirkung: Dies reduziert dramatisch falsche Positivmeldungen and erhöht die Genauigkeit der Alarmpriorität. Ein Ereignis, das einen kritischen Server oder einen privilegierten Benutzer einbezieht, kann sofort eskaliert werden. Es macht auch die an das SIEM gesendeten Alarme von Haus aus viel wertvoller.
Beste Praktiken
Dedizierte Kafka-Themen
- Isolation: Die Verwendung dedizierter Themen für verschiedene Datenströme bietet Isolation zwischen ihnen. Das bedeutet, dass ein Problem mit einem Datenstrom (z. B. ein plötzlicher Traffic-Anstieg) die anderen weniger wahrscheinlich beeinflusst.
- Leistung: Dedizierte Themen können auch die Leistung verbessern, indem Sie die Konfiguration jedes Themas für seinen spezifischen Anwendungsfall optimieren können. Sie können beispielsweise eine unterschiedliche Anzahl von Partitionen oder einen unterschiedlichen Replikationsfaktor für jedes Thema festlegen.
Skalierbarkeit
- Horizontale Skalierung: Die Confluent Sigma-Anwendung kann horizontal skaliert werden, indem mehrere Instanzen der Anwendung parallel ausgeführt werden. Jede Instanz verarbeitet einen Teil der Daten, sodass der Gesamtdurchsatz des Systems erhöht wird.
- Partitionierung: Um horizontale Skalierung zu ermöglichen, müssen Sie Ihre Kafka-Themen partitionieren. Dadurch können mehrere Instanzen der Anwendung Daten aus demselben Thema parallel konsumieren. Sie sollten einen Partitionierungsschlüssel wählen, der die Daten gleichmäßig auf die Partitionen verteilt.
- Verbrauchergruppen: Wenn Sie mehrere Instanzen der Confluent Sigma-Anwendung ausführen, sollten Sie sie als Teil derselben Verbrauchergruppe konfigurieren. Dies stellt sicher, dass jede Nachricht im Eingabethema nur von einer Instanz der Anwendung verarbeitet wird.
Verschlüsselung
Verwenden Sie TLS/SSL, um die Daten während der Übertragung zwischen den Produzenten, Verbrauchern und den Kafka-Brokern zu verschlüsseln. Dies schützt die Daten vor Abhören und Manipulation.
Überwachung
Es ist entscheidend, die Gesundheit und Leistung der Confluent Sigma-Anwendung in einer Produktionsumgebung zu überwachen. Sie sollten die folgenden Metriken überwachen:
- Die Anzahl der verarbeiteten Nachrichten
- Die Anzahl der generierten Alarme
- Die Latenz der Anwendung
- Die CPU- und Speichernutzung der Anwendung
Schlüsselmetriken
Zusätzlich zu den vorher erwähnten Metriken sollten Sie auch folgende überwachen:
- Verbraucher-Lag: Dies ist die Anzahl der Nachrichten in einem Thema, die noch nicht vom Verbraucher verarbeitet wurden. Ein hoher Verbraucher-Lag kann darauf hinweisen, dass die Anwendung nicht mit der Rate der eingehenden Daten Schritt halten kann.
- End-to-End-Latenz: Dies ist die Zeit, die eine Nachricht benötigt, um vom Produzenten zum Verbraucher zu gelangen. Eine hohe End-to-End-Latenz kann auf ein Problem mit dem Netzwerk oder dem Kafka-Cluster hinweisen.
Confluent Sigma Anwendungsfälle
Confluent Sigma ermöglicht es Sicherheitsteams, Bedrohungen in Echtzeit zu erkennen, indem Sigma-Regeln direkt auf Kafka-Streams angewendet werden. Dadurch können Detection Engineers auf Anomalien reagieren, bevor Daten das SIEM erreichen und die Regelverfeinerung optimieren.
Wichtige Anwendungsfälle umfassen die folgenden:
- Shift-Left-Bedrohungserkennung: Anwendung von Erkennungslogik an der Quelle, bevor Logs das SIEM erreichen, ermöglicht eine schnellere Reaktion auf Live-Angriffe.
- Einrichten einer CI/CD-Pipeline für Erkennungen: Automatisieren der Regelbereitstellung und -aktualisierungen in verschiedenen Umgebungen bei gleichzeitiger Verbesserung der betrieblichen Effizienz und Konsistenz.
- Versioniere Regeln über Umgebungen hinweg: Pflegen eines strukturierten Regelversionsmanagements unter Verwendung von Kafka-Themen oder Git, um Nachvollziehbarkeit und einfachere Rollbacks zu gewährleisten.
- Reduzieren der Kosten für Log-Ingestion: Erkennen von Bedrohungen während des Transports, ohne jedes Log in das SIEM zu ingestieren, senkt Speicher- und Verarbeitungskosten.
- Entfernen von SIEM-Abfrage-Latenz: Zugriff auf hochqualitative Erkennungen sofort, indem Regeln in Echtzeit-Streams verarbeitet werden.
- Erhöhen Sie die Korrelationgeschwindigkeit: Anwendung von Aggregations- und Sliding-Window-Logik innerhalb von Kafka Streams, um schnell Ereignisse zu korrelieren und Alarme zu generieren.
Confluent Sigma unterstützt durch SOC Prime Technologie
Während das Open-Source Confluent Sigma-Projekt eine robuste Grundlage für Shift-Left-Erkennung bietet, wird sein wahres Potenzial für Skalierung und erweiterte Bedrohungsabdeckung erst mit der Integration von Unternehmenslösungen wie SOC Prime. Der folgende Vergleich hebt hervor, wie sich die Kernfunktionen entwickeln, um den Anforderungen von großangelegten und komplexen Umgebungen gerecht zu werden.
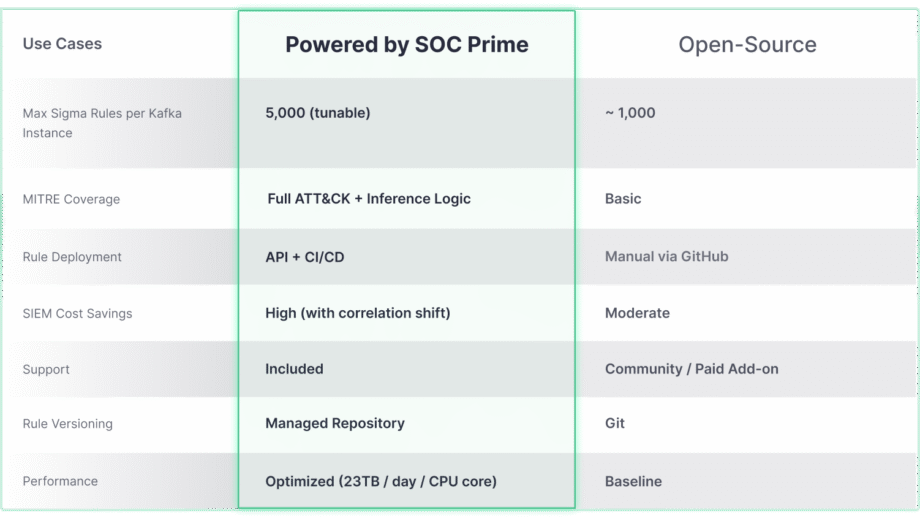
Die Confluent Sigma & SOC Prime-Lösung bietet direkten Zugang zu Tools und Inhalten, die den Erkennungslebenszyklus drastisch beschleunigen:
- Threat Detection Marketplace: Durch die Nutzung des Threat Detection Marketplace können Sicherheitsteams aus über 15.000 Sigma-Regeln wählen, die auf neu auftretende Bedrohungen abzielen, und diese automatisiert direkt in die Kafka-Umgebung streamen.
- Uncoder AI: Mit SOC Prime’s Uncoder AI, einer IDE und Co-Pilot für End-to-End-Detection-Engineering, können Verteidiger Erkennungscode aus mehreren Sprachformaten in Sigma konvertieren, ihn automatisch auf MITRE ATT&CK abbilden, Code von Grund auf mit KI schreiben oder ihn spontan abstimmen, um eine optimierte Bedrohungserkennung sicherzustellen..
- Betriebliche Exzellenz: Automatisierte Bereitstellung über APIs und CI/CD sorgt für eine konsistente, wiederholbare Regelverteilung, während die Hochdurchsatz-Leistung (bis zu 23 TB/Tag pro CPU-Kern) eine Echtzeit- und skalierbare Bedrohungserkennung in jeder Umgebung ermöglicht.
- Expertenunterstützung: Vertrauen Sie auf die herausragende Ingenieurkompetenz von SOC Prime, um geführte Unterstützung bei der Installation, Verwaltung und Skalierung des Open-Source-Erkennungs-Stacks zu erhalten.