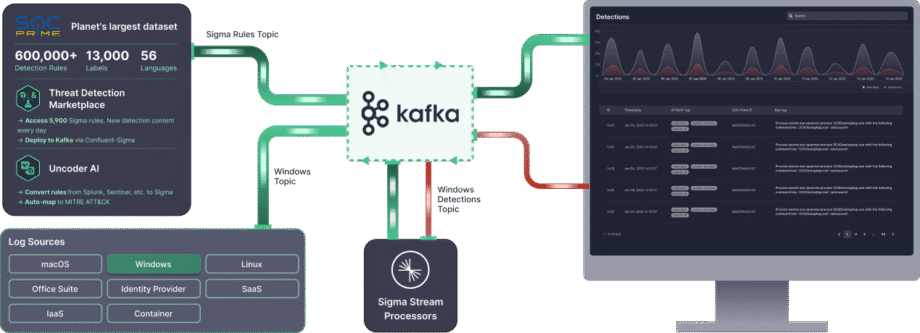
Security teams need faster and more flexible ways to detect threats in complex data environments. High-volume data streams make detection difficult when operations are fragmented across multiple tools, agility in incident response is limited, and managing large datasets is expensive.
Confluent Sigma addresses these challenges by enabling a Shift-Left threat detection strategy that moves detection logic out of the SIEM and into the stream-processing layer. This lets security teams detect threats closer to the source and act on high-fidelity signals while an attack is unfolding, rather than waiting until data is normalized, indexed, and stored.
Confluent Sigma uses Kafka Streams to run Sigma rules on source data before it reaches the SIEM. Sigma is the open-source, vendor-agnostic standard for describing log events. By applying rules to live data streams, Confluent Sigma combines the portability of Sigma with the speed and scalability of Apache Kafka.
This guide walks you through the installation of Confluent Sigma and presents practical scenarios for its major use cases, helping security teams adopt Detection as Code and respond to threats more effectively.
For security teams requiring immediate scale and advanced enterprise features, SOC Prime Platform provides a fully supported, enterprise-grade solution based on Confluent Sigma.
Confluent Sigma Modules & Processing Logic
Confluent Sigma is composed of three main modules:
- sigma-parser: A Java library that provides the core functionality for reading and processing Sigma rules.
- sigma-streams-ui: A development-oriented UI for interacting with the Sigma Streams process, enabling users to view published rules, add or edit rules, monitor processor statuses, and visualize detections.
- sigma-streams: The main module of the project, which contains the actual stream processor and associated command-line scripts.
The Sigma Streams processor leverages Kafka Streams to efficiently apply detection logic based on the rule type:
- Simple Topology: This topology supports one sub-topology to many rules and is used for non-aggregating detections based on a single event record. The processor uses the Kafka Streams’
flatMapValuesfunction to transform records. It iterates through each rule for filtering, validates the streaming data against the DSL rule, and adds the match results to an output list. This process is highly efficient, and the final detection record is sent immediately to the dynamic output topic. - Aggregate Topology: This topology requires one sub-topology for each rule to manage state and is used for complex, stateful detections involving counting or time windows. For advanced rules, the processor first validates the data and then groups it by a defined key (e.g.,
id_orig_h). It applies a sliding window from the rule (e.g.,timeframe: 10s), counts the number of instances within that window, and finally filters based on the aggregation and operation in the rule (e.g.,count() > 10). The final aggregated detection record is then sent to the dynamic output topic.
When a match occurs, the resulting detection event is enriched before output:
- Rule Metadata: The event includes the matching rule’s
title,author,product, andservice. - Field Mapping: If the rule uses a regular expression (regex), the extracted fields are added to the output.
- Custom Fields: Any custom metadata defined in the rule is included for context and downstream routing.
- Dynamic Output: The result is sent to the topic specified by the rule’s
outputTopicfield.
How to Install Confluent Sigma
Step 1: Getting Started
Confluent Sigma relies on three main Kafka topics to function. The Sigma Streams processor continuously monitors these topics to apply logic and output detections.
- Rule topic: Contains Sigma rules
- Input data topic: Contains incoming event data (e.g., logs).
- Output topic: Contains events that matched one or more Sigma rules.
Sigma rules are published to a dedicated Kafka topic, which the Sigma Streams processor monitors. These rules are then applied in real time to data from another subscribed topic. Any records matching the rules are forwarded to a designated output topic.
Note: All three topics must be defined in the configuration. However, rules can override the output destination to route to different topics based on the specific rule logic.
Before you get started with Confluent Sigma, make sure you have the following in place:
- Kafka Environment
- A running Apache Kafka cluster (local or production).
- Access to Kafka CLI tools (kafka-topics, kafka-console-producer, kafka-console-consumer).
- Proper network connection and appropriate permissions to create and manage topics.
- Sigma Streams Application
- Download and install the Confluent Sigma Streams application.
- Ensure the
bin/confluent-sigma.shscript is executable.
- Sigma Rules
- Valid Sigma rule files in the YAML or JSON format.
- Each rule should follow the Sigma specification.
- Sigma Rule Loader (optional)
- Install the SigmaRuleLoader utility if you plan to bulk-load rules.
- Configuration Files
Make sure you have a valid sigma.properties configuration file with:- Rule topic
- Input data topic
- Output topic
- Bootstrap server settings
Step 2: Creating a Sigma Rule Topic
Before adding a Sigma rule, make sure to create a Sigma rule topic. Below is an example of how to create a Sigma rule topic:kafka-topics --bootstrap-server localhost:9092 --topic sigma_rules --replication-factor 1 --partitions 1 --config cleanup.policy=compact --create
Note: For production deployments, use a replication factor of at least 3. Since rules are relatively few compared to event data, one partition is typically sufficient.
Step 3. Loading Sigma Rules
Sigma rules are stored in a user-specified Kafka topic. Each Kafka record’s key should meet the following requirements:
- Type:
string - Set to the rule’s title field
Note: The Sigma specification doesn’t require an ID field, so rule titles must be unique. Newly published or updated rules are automatically picked up by a running Sigma Streams processor.
Rules can be ingested into Kafka using:
- SigmaRuleLoader application
- The
kafka-console-producercommand-line tool
Rule Ingestion via SigmaRuleLoader
The SigmaRuleLoader application allows bulk or single rule ingestion as YAML files.
To load a single Sigma rule file, use the -file option. For example:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -file zeek_sigma_rule.yml
To load the entire directory containing Sigma rules, use the -dir option:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -dir zeek_sigma_rules
Rule Ingestion via CLI
You can also load Sigma rules manually via a standard Kafka CLI, for instance, the kafka-console-producer utility:kafka-console-producer --broker-list localhost:9092 --topic sigma-rules --property "key.separator=:"
Here’s a code snippet of the rule ingestion via CLI in the JSON format:--property "key.separator=:"
{"title":Sigma Rule Test,"id":"123456789","status":"experimental","description":"This is just a test.", "author":"Test", "date":"1970/01/01","references":["https://confluent.io/"],"tags":["test.test"],"logsource": {"category":"process_creation","product":"windows"},"detection":{"selection":{"CommandLine|contains|all": [" /vss "," /y "]},"condition":"selection"},"fields":["CommandLine","ParentCommandLine"],"falsepositives": ["Administrative activity"],"level":"high"}
Step 4. Running the Sigma Streams Application
The Confluent Sigma Streams is a Java application that can be executed directly or through the confluent-sigma.sh script. To run the application via a script, use the following command:
bin/confluent-sigma.sh properties-file
Confluent Sigma Streams configuration lookup order:
- Command-line argument (
properties-file). $SIGMAPROPSenvironment variable.
Note: If you do not specify the properties-file, the application will check the $SIGMAPROPS variable.
- If the former is not set, the app will search the following directories for the
properties-file:~/.config~/.confluent~/tmp
See the examples of sigma.properties here.
Implementation Recommendations
Rule Hot-Reloading via a Kafka Topic
A significant operational challenge is updating detection rules without incurring downtime. Restarting the stream processing application every time a Sigma rule is added or modified is inefficient and leads to gaps in detection coverage.
- Recommendation: Create a dedicated, compacted Kafka topic to serve as a “rules topic.” The confluent-sigma application should consume from this topic using a GlobalKTable. When a new or updated Sigma rule is published to this topic (keyed by a unique rule ID), the GlobalKTable will automatically update in near real-time. The main event processing stream can then join against this GlobalKTable, ensuring it always has the latest set of rules without needing a restart.
- Impact: This provides zero-downtime rule deployment, allowing security analysts to react to new threats almost instantly. It decouples the rule management lifecycle from the application deployment lifecycle.
Enrich Events In-Stream Before Rule Matching
Raw security logs often lack the context needed for high-fidelity alerts. For example, a raw log might contain an IP address but not its reputation, or a user ID but not the user’s department or role. Relying on the SIEM for all enrichment can delay context and create noisier alerts.
- Specific Recommendation: Before the primary Sigma rule matching logic, implement an enrichment phase within the Kafka Streams topology. Use stream-table joins to enrich the incoming event stream.
- Threat Intelligence: Join the event stream with a GlobalKTable of known malicious IPs, domains, or file hashes loaded from a threat intelligence feed.
- Asset/User Information: Join the event stream with a KTable populated from a CMDB or Active Directory feed to add context like device owner, server criticality, or user role.
- Impact: This dramatically reduces false positives and increases alert priority accuracy. An event involving a critical server or a privileged user can be immediately escalated. It also makes the alerts sent to the SIEM far more valuable out-of-the-box.
Best practices
Dedicated Kafka Topics
- Isolation: Using dedicated topics for different data streams provides isolation between them. This means that a problem with one data stream (e.g., a sudden spike in traffic) is less likely to affect the others.
- Performance: Dedicated topics can also improve performance by allowing you to optimize the configuration of each topic for its specific use case. For example, you can set a different number of partitions or a different replication factor for each topic.
Scalability
- Horizontal Scaling: The Confluent Sigma application can be scaled horizontally by running multiple instances of the application in parallel. Each instance will process a subset of the data, which will increase the overall throughput of the system.
- Partitioning: To enable horizontal scaling, you need to partition your Kafka topics. This will allow multiple instances of the application to consume data from the same topic in parallel. You should choose a partitioning key that will distribute the data evenly across the partitions.
- Consumer Groups: When you run multiple instances of the Confluent Sigma application, you should configure them to be part of the same consumer group. This will ensure that each message in the input topic is processed by only one instance of the application.
Encryption
You should use TLS/SSL to encrypt the data in transit between the producers, consumers, and the Kafka brokers. This will protect the data from eavesdropping and tampering.
Monitoring
It is crucial to monitor the health and performance of the Confluent Sigma application in a production environment. You should monitor the following metrics:
- The number of messages processed
- The number of alerts generated
- The latency of the application
- The CPU and memory usage of the application
Key Metrics
In addition to the metrics mentioned previously, you should also monitor the following:
- Consumer Lag: This is the number of messages in a topic that have not yet been processed by the consumer. A high consumer lag can indicate that the application is not able to keep up with the rate of incoming data.
- End-to-End Latency: This is the time it takes for a message to travel from the producer to the consumer. A high end-to-end latency can indicate a problem with the network or the Kafka cluster.
Confluent Sigma Use Cases
Confluent Sigma enables security teams to detect threats in real time by applying Sigma rules directly to Kafka streams, allowing Detection Engineers to respond to anomalies before data reaches the SIEM and streamline rule refinement.
Key use cases include the following:
- Shift-Left Threat Detection: Apply detection logic at the source, before logs reach the SIEM, allowing faster response to live attacks.
- Set up CI/CD Pipeline for Detections: Automate rule deployment and updates across environments while improving operational efficiency and consistency.
- Version Rules Across Environments: Maintain structured rule versioning using Kafka topics or Git, ensuring traceability and easier rollbacks.
- Reduce Costs of Log Ingestion: Detect threats in-flight without ingesting every log into the SIEM, lowering storage and processing costs.
- Remove SIEM Query Latency: Access high-fidelity detections instantly by processing rules in real-time streams.
- Boost Correlation Speed: Apply aggregation and sliding-window logic within Kafka Streams to quickly correlate events and generate alerts.
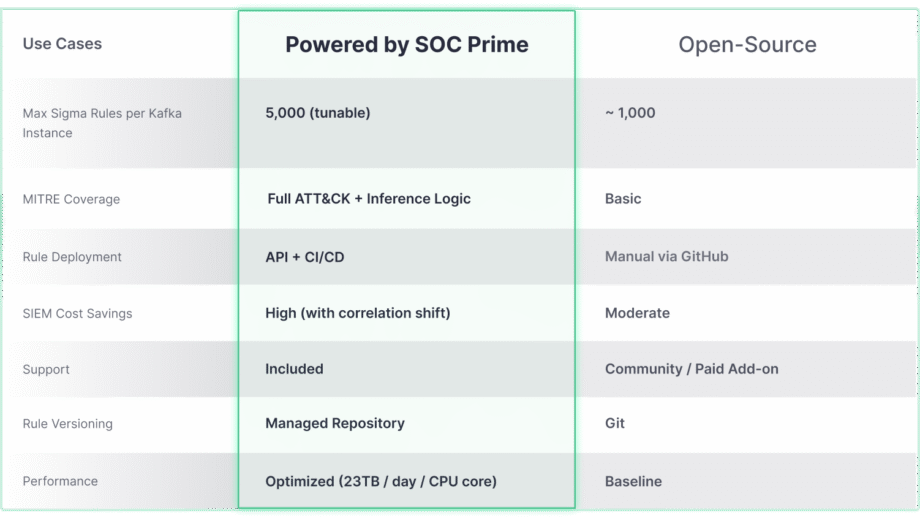
Confluent Sigma Powered by SOC Prime Technology
While the open-source Confluent Sigma project provides a robust foundation for Shift-Left detection, its true potential for scale and advanced threat coverage is unlocked when integrated with enterprise-grade solutions like SOC Prime. The comparison below highlights how the core capabilities evolve to meet the demands of large-scale and complex environments.
Confluent Sigma & SOC Prime solution provides direct access to tools and content that dramatically accelerate the detection lifecycle:
- Threat Detection Marketplace: By leveraging the Threat Detection Marketplace, security teams can choose from 15K+ Sigma rules that address emerging threats and stream them directly to the Kafka environment in an automated manner.
- Uncoder AI: With SOC Prime’s Uncoder AI, an IDE and co-pilot for end-to-end detection engineering, defenders can convert detection code from multiple language formats to Sigma, auto-map it to MITRE ATT&CK, write code from scratch with AI, or tune it on the fly to ensure streamlined threat detection.
- Operational Excellence: Automated deployment via APIs and CI/CD ensures consistent, repeatable rule rollout, while high-throughput performance (up to 23 TB/day per CPU core) enables real-time, scalable threat detection in any environment.
- Expert Support: Rely on SOC Prime’s top engineering expertise to receive guided support on installing, managing, and scaling the open-source detection stack.