L’observabilité a commencé comme un problème de visibilité. Cependant, aujourd’hui, elle est tout autant considérée comme un défi de contrôle, car les équipes doivent gérer les flots de télémétrie circulant quotidiennement dans l’environnement professionnel. La plupart des organisations collectent déjà de grands volumes de journaux, de métriques, d’événements et de traces. Le problème réside maintenant dans la gestion de ces masses de données avant qu’elles n’atteignent des outils coûteux en aval. Gartner définit les plateformes d’observabilité comme des systèmes qui ingèrent des télémétries pour aider les équipes à comprendre la santé, la performance et le comportement des applications, des services et de l’infrastructure. C’est important car lorsque les systèmes ralentissent ou échouent, l’impact dépasse largement le côté technique, affectant les revenus, le sentiment des clients et la perception de la marque.
Cela crée un paradoxe bien connu. Les environnements complexes nécessitent une large couverture télémétrique, mais les grands volumes de données peuvent rapidement devenir coûteux et difficiles à gérer. Lorsque chaque signal est transmis par défaut, les informations utiles se mélangent avec les doublons, les données de faible valeur et les coûts de stockage et de traitement croissants. Gartner rapporte que les dépenses d’observabilité augmentent d’environ 20% d’année en année, de nombreuses organisations dépensant déjà plus de 800 000 $ par an. La tendance montre que d’ici 2028, 80% des entreprises sans contrôle des coûts d’observabilité dépenseront plus de 50% de trop.
La pression pousse les équipes à chercher plus de contrôle plus tôt dans le flux. Les pipelines d’observabilité répondent à ce besoin en offrant aux équipes un moyen pratique de filtrer, enrichir, transformer et diriger les données avant qu’elles ne se transforment en bruit, en déchets et en frein opérationnel en aval.
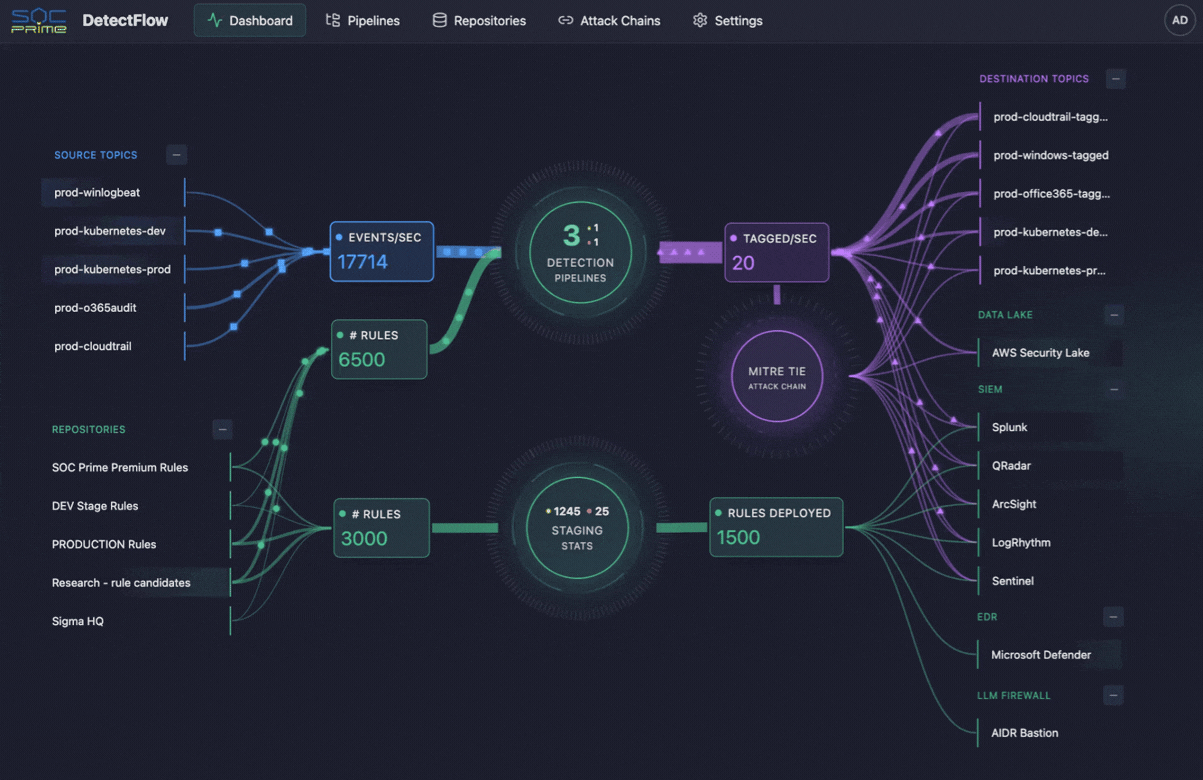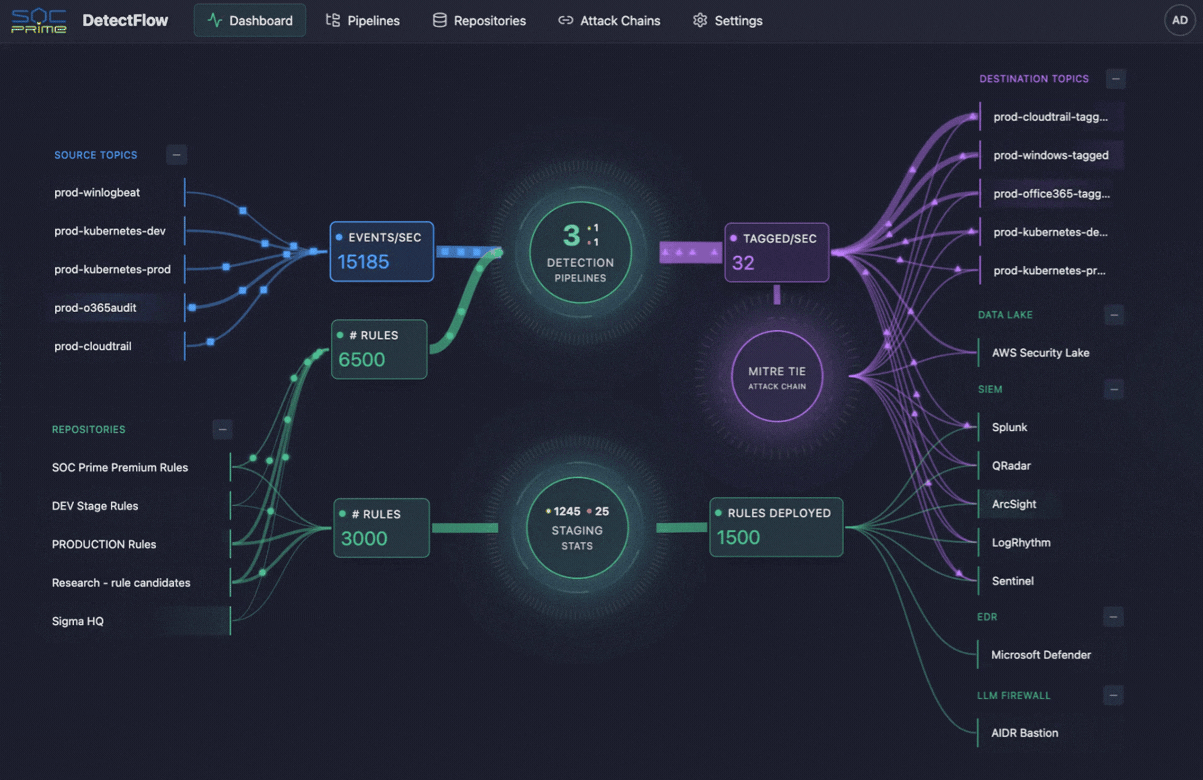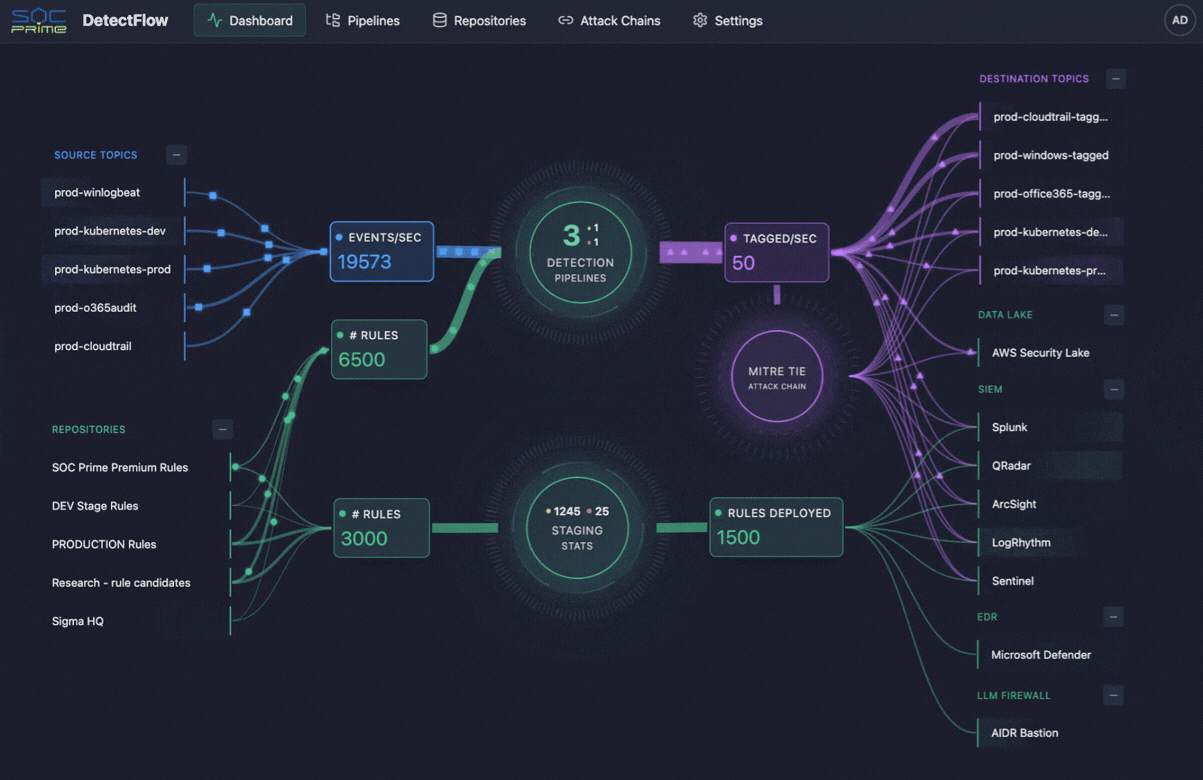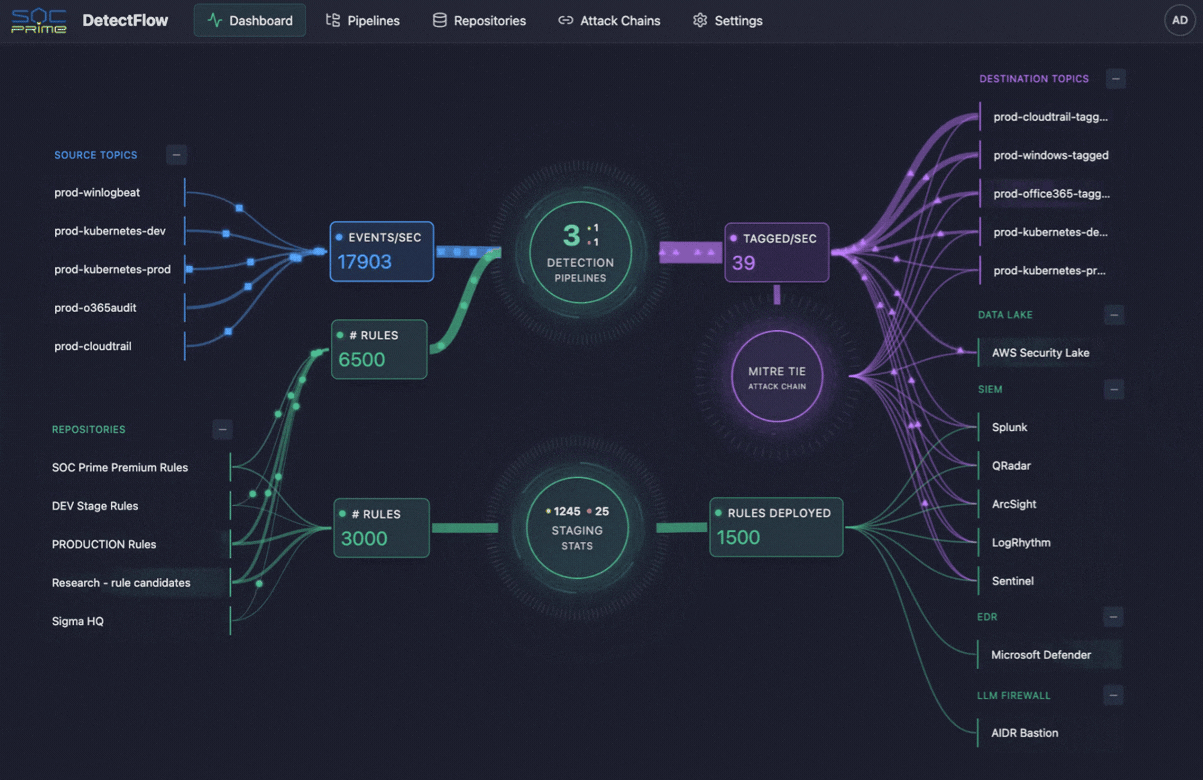
La même logique commence à façonner les opérations de cybersécurité également. C’est là que des outils comme DetectFlow de SOC Prime entrent en scène. DetectFlow déplace la couche de détection directement dans le pipeline, permettant aux équipes SOC d’exécuter des dizaines de milliers de règles Sigma sur des flux Kafka en direct utilisant Apache Flink, étiquetant, enrichissant et enchaînant les événements au stade pré-SIEM pour évoluer sans les limites habituelles des fournisseurs en termes de vitesse, de capacité ou de coût.
Qu’est-ce qu’un pipeline d’observabilité ?
Un pipeline d’observabilité est la solution qui déplace la télémétrie des sources vers les destinations tout en accomplissant des tâches comme la transformation, l’enrichissement et l’agrégation. Concrètement, il prend en charge les journaux, les métriques, les traces et les événements, puis prépare ces données avant qu’elles n’atteignent les plateformes de surveillance, les SIEM, les lacs de données ou le stockage à long terme. En cours de route, les pipelines d’observabilité peuvent filtrer les données bruyantes, enrichir les enregistrements avec leur contexte, agréger les flux à grand volume, sécuriser les champs sensibles et diriger chaque type de donnée vers la destination la plus appropriée.
Cela devient important à mesure que la télémétrie se développe parmi les microservices, les conteneurs, les services cloud et les systèmes distribués. Sans un pipeline, les équipes transfèrent souvent tout par défaut, ce qui augmente les coûts, ajoute du bruit et rend la gestion des données plus compliquée à travers plusieurs outils et environnements.
Les pipelines d’observabilité aident à résoudre plusieurs défis courants :
- Surcharge de données. Le volume élevé de télémétrie rend plus difficile la distinction entre les signaux utiles et les données de faible valeur, surtout lorsque des journaux, des métriques et des traces proviennent de nombreux systèmes différents en même temps.
- Coûts croissants de stockage et de traitement. Envoyer toutes les données vers les plateformes en aval augmente les coûts d’ingestion, d’indexation et de rétention, même si une grande partie de ces données apporte peu de valeur.
- Données bruyantes. La télémétrie en double, à faible priorité ou à faible contexte peut submerger les signaux qui comptent réellement pour le dépannage, la sécurité et l’analyse des performances.
- Risques de conformité et de sécurité. Les journaux et les flux télémétriques peuvent contenir des données personnelles ou réglementées, ce qui augmente les risques de conformité et de confidentialité lorsqu’ils sont transmis ou stockés sans masquage ou rédaction appropriés.
- Infrastructure complexe. Les équipes doivent souvent envoyer différents ensembles de données vers différentes destinations, telles que des outils de surveillance, des SIEM et du stockage à moindre coût, ce qui devient difficile à gérer sans un plan de contrôle central.
- Migration et flexibilité des fournisseurs. Les pipelines facilitent la reconfiguration et le redirectionnement de la télémétrie pour de nouveaux outils ou des destinations parallèles sans reconstruire la collecte depuis le début.
En termes simples, un pipeline d’observabilité donne aux équipes plus de contrôle sur la télémétrie. Il aide les organisations à conserver les signaux utiles, à améliorer le contexte, et à envoyer chaque flux là où il doit aller.
Comment fonctionnent les pipelines d’observabilité
De manière pratique, les pipelines d’observabilité créent un flux unique pour gérer les données de télémétrie. Au lieu de gérer plusieurs transferts entre sources et destinations, les équipes peuvent travailler à travers une seule couche de contrôle qui prépare les données pour différents cas d’utilisation opérationnels et de sécurité.
Collecter
La première étape consiste à recueillir les données à travers l’environnement organisationnel. Cela peut inclure des journaux d’applications, des métriques d’infrastructure, des événements cloud, des données de conteneurs et des enregistrements de sécurité. Rassembler ces entrées dans un seul pipeline donne aux équipes un point de départ plus cohérent et réduit le besoin de connexions séparées entre chaque source et chaque outil.
Traitement
Une fois les données entrées dans le pipeline, elles peuvent être ajustées pour répondre aux besoins de l’entreprise. Les équipes peuvent standardiser les formats, enrichir les enregistrements avec des métadonnées, supprimer les événements en double, masquer les champs sensibles ou réduire les détails inutiles. Cette étape rend les données plus utilisables, que l’objectif soit le dépannage, la conformité, la rétention à long terme ou l’analyse de sécurité.
Acheminer
Après traitement, le pipeline envoie les données à la bonne destination. Les enregistrements prioritaires peuvent aller vers une plateforme de surveillance ou un SIEM pour une visibilité immédiate, tandis que d’autres données peuvent être archivées, stockées dans un lac de données ou dirigées vers un stockage à moindre coût. Cela facilite le soutien des différentes équipes sans forcer chaque système à traiter les mêmes données de la même manière.
Avantages de l’utilisation d’un pipeline d’observabilité
Un pipeline d’observabilité aide les équipes à gérer la croissance des volumes de télémétries, à améliorer la qualité des données et à contrôler comment les informations sont utilisées à travers les opérations et la sécurité. À mesure que les environnements deviennent plus distribués, ce type de contrôle est de plus en plus important pour le coût, la performance et une prise de décision plus rapide.
Certains des principaux avantages incluent :
- Réduction des coûts de stockage et de traitement. Un pipeline d’observabilité aide à réduire les dépenses inutiles en filtrant les événements de faible valeur, en dédupliquant les enregistrements et en envoyant uniquement les données pertinentes aux plateformes coûteuses. Cela empêche les équipes de payer le prix fort pour des données qui n’apportent que peu de valeur.
- Une meilleure qualité des signaux. Lorsque la télémétrie bruyante ou incomplète est nettoyée plus tôt, les données qui atteignent les outils en aval deviennent plus faciles à rechercher, analyser et exploiter. Cela aide les équipes à se concentrer sur ce qui importe réellement au lieu de trier le fouillis.
- Dépannage et enquêtes plus rapides. Des données mieux préparées accélèrent la réponse aux incidents. Les équipes opérationnelles peuvent identifier plus rapidement les problèmes de performance, tandis que les équipes de sécurité peuvent obtenir des enregistrements plus propres et plus pertinents dans les SIEM et autres outils de détection sans submerger les analystes avec du bruit.
- Une conformité et une protection des données renforcées. Les journaux et la télémétrie peuvent contenir des informations sensibles ou réglementées. Un pipeline facilite le masquage, la rédaction ou l’acheminement correct de ces données avant qu’elles ne soient stockées ou partagées, ce qui soutient la conformité et réduit le risque.
- Plus de flexibilité à travers les outils et les équipes. Différentes équipes ont besoin de vues différentes des mêmes données. Un pipeline d’observabilité facilite le routage de flux spécifiques vers des plateformes de surveillance, des lacs de données, des SIEM ou un stockage moins coûteux sans reconstruire la collecte chaque fois que les besoins changent.
- Une meilleure évolutivité pour les environnements modernes. À mesure que l’infrastructure se développe à travers le cloud, les conteneurs et les systèmes distribués, les pipelines aident les organisations à faire évoluer la gestion de la télémétrie de manière plus contrôlée et durable.
En essence, la valeur d’un pipeline d’observabilité repose sur le contrôle. Il aide les équipes à réduire les déchets, améliorer la qualité des signaux, soutenir la sécurité et la conformité, et à mieux utiliser la télémétrie à travers l’entreprise.
Pipeline d’observabilité dans le Cloud
Les environnements cloud compliquent l’observabilité car ils ajoutent plus de mouvement, plus de dépendances, et bien plus de télémétrie à gérer. Les microservices, les conteneurs, Kubernetes et les charges de travail à courte durée de vie produisent tous des signaux qui changent rapidement et s’accumulent rapidement. Dans le résumé de recherche de la chronosphère sur l’observabilité cloud-native, 87% des ingénieurs ont déclaré que les architectures cloud-native ont rendu la découverte et le dépannage des incidents plus complexes, et 96% ont dit qu’ils se sentaient à leurs limites.
Cette complexité crée un problème pratique pour l’entreprise. Les équipes ont besoin d’une large visibilité pour comprendre ce qui se passe à travers les services cloud, les applications et l’infrastructure, mais transférer tout par défaut devient rapidement coûteux et difficile à gérer. Les experts décrivent le changement du marché comme un passage du volume à la valeur, poussé par les coûts de télémétrie croissants, les charges de travail IA et le besoin d’une visibilité plus disciplinée.
C’est là que les pipelines d’observabilité deviennent particulièrement utiles dans le cloud. Un pipeline donne aux équipes une couche de contrôle entre les sources de données et les outils en aval, afin qu’elles puissent filtrer les enregistrements bruyants, enrichir les plus importants, et diriger chaque flux vers la bonne destination. Cela signifie moins de gaspillage dans les plateformes premium, de meilleurs signaux pour le dépannage, et plus de flexibilité à travers les outils de surveillance, de stockage et de sécurité. Dans les environnements cloud-native, ce type de contrôle n’est plus un simple bonus.
L’angle cloud est également important pour la cybersécurité. Les équipes de sécurité dépendent de la même télémétrie cloud pour la détection des menaces, l’enquête et la conformité, mais le volume brut peut submerger les SIEM et enfouir les événements importants. Un pipeline d’observabilité aide plus tôt dans le flux en réduisant le bruit, en améliorant le contexte, et en envoyant les enregistrements de plus grande valeur aux bons systèmes. C’est aussi là que DetectFlow de SOC Prime trouve naturellement sa place, déplaçant la détection plus près de l’ingestion pour que les équipes puissent évaluer, enrichir et corréler les événements avant qu’ils ne deviennent une surcharge en aval.
Pipeline d’observabilité : une couche plus intelligente pour les opérations de sécurité
Un pipeline d’observabilité offre aux équipes quelque chose dont elles ont de plus en plus besoin dans les environnements modernes : le contrôle avant que les données ne se transforment en coûts, en bruit, et en prise de décision lente. Plus les organisations collectent de télémétrie, plus il est essentiel de la filtrer, de l’enrichir, de la transformer et de la diriger avec un objectif. Cela rend les pipelines d’observabilité utiles bien au-delà de la seule surveillance. Ils aident à améliorer la qualité des données, à maintenir l’efficacité des plateformes en aval, et à créer une base plus solide pour les opérations et la sécurité.
Notamment, les équipes de sécurité font face au même problème de télémétrie, mais avec des enjeux plus élevés. Les SIEM ont des limites pratiques, les comptes de règles ne s’échelonnent pas indéfiniment, et trop de données brutes peuvent imposer une charge énorme sur l’analyse de sécurité. C’est là que DetectFlow ajoute une couche de valeur significative, en étendant la logique du pipeline d’observabilité à la détection des menaces en rapprochant la détection de la couche d’ingestion.
DetectFlow exécute des dizaines de milliers de détections Sigma sur des flux Kafka en direct utilisant Apache Flink, corrèle les événements à partir de sources de journaux multiples au stade pré-SIEM, et utilise Flink Agent plus un contexte de menace actif pour une analyse améliorée par IA. En pratique, cela signifie que les équipes SOC peuvent réduire le bruit plus tôt, faire émerger les chaînes d’attaque plus rapidement, et améliorer la clarté des enquêtes avant que les outils en aval ne soient submergés.