L’observability è nata come un problema di visibilità. Oggi, però, viene considerata sempre più anche una sfida di controllo, perché i team devono gestire i flussi di telemetry che attraversano ogni giorno l’ambiente aziendale. La maggior parte delle organizzazioni raccoglie già grandi volumi di log, metriche, eventi e trace. Il problema ora sta nel gestire tutta questa mole di dati prima che raggiunga costosi strumenti downstream. Gartner definisce le piattaforme di observability come sistemi che acquisiscono telemetry per aiutare i team a comprendere salute, prestazioni e comportamento di applicazioni, servizi e infrastrutture. Questo conta perché, quando i sistemi rallentano o si guastano, l’impatto va ben oltre l’aspetto tecnico, influenzando ricavi, percezione dei clienti e reputazione del brand.
Questo crea un paradosso ben noto. Gli ambienti complessi richiedono un’ampia copertura della telemetry, ma grandi volumi di dati possono rapidamente diventare costosi e difficili da gestire. Quando ogni segnale viene inoltrato per impostazione predefinita, gli insight utili finiscono mescolati a duplicazioni, dati di scarso valore e costi crescenti di storage ed elaborazione. Gartner riporta una crescita della spesa per l’observability di circa il 20% anno su anno, con molte organizzazioni che già spendono oltre 800.000 dollari l’anno. La tendenza mostra che entro il 2028 l’80% delle aziende prive di controlli sui costi dell’observability spenderà oltre il 50% in più del necessario.
Questa pressione spinge i team a cercare maggiore controllo nelle fasi più a monte del flusso. Gli observability pipeline rispondono a questa esigenza offrendo ai team un modo pratico per filtrare, arricchire, trasformare e instradare i dati prima che si trasformino in rumore, sprechi e attrito operativo downstream.
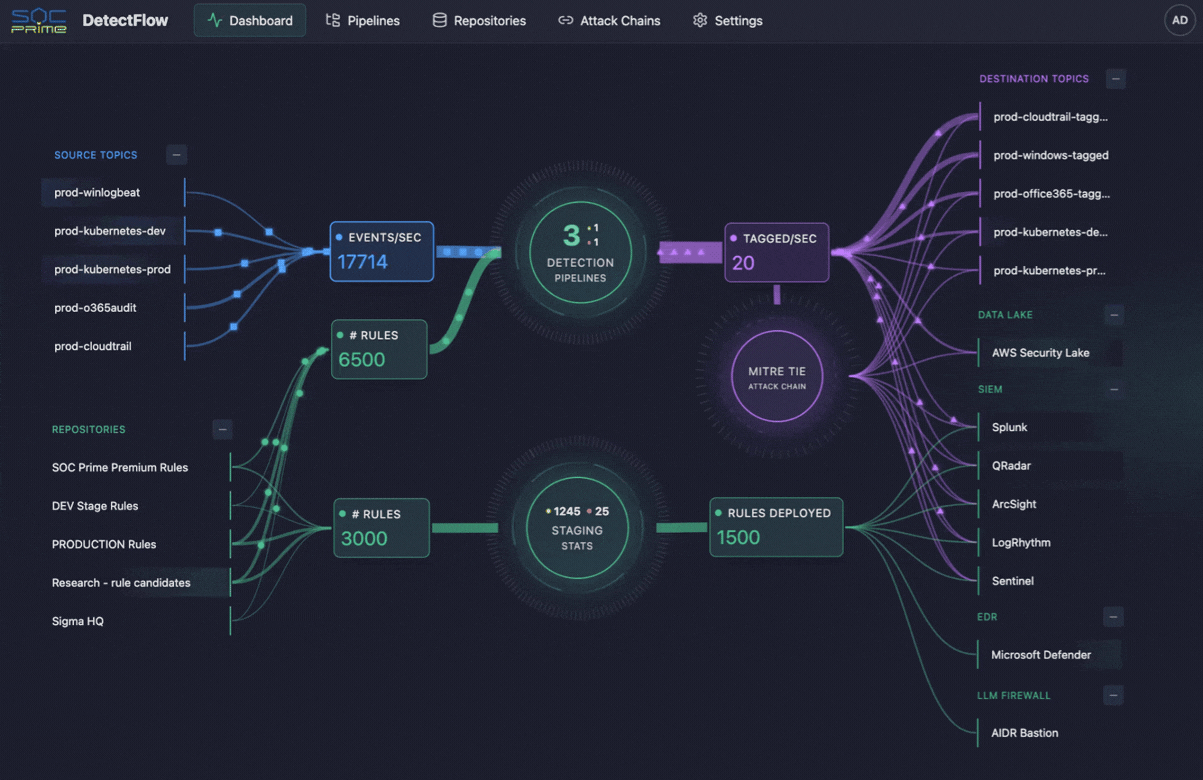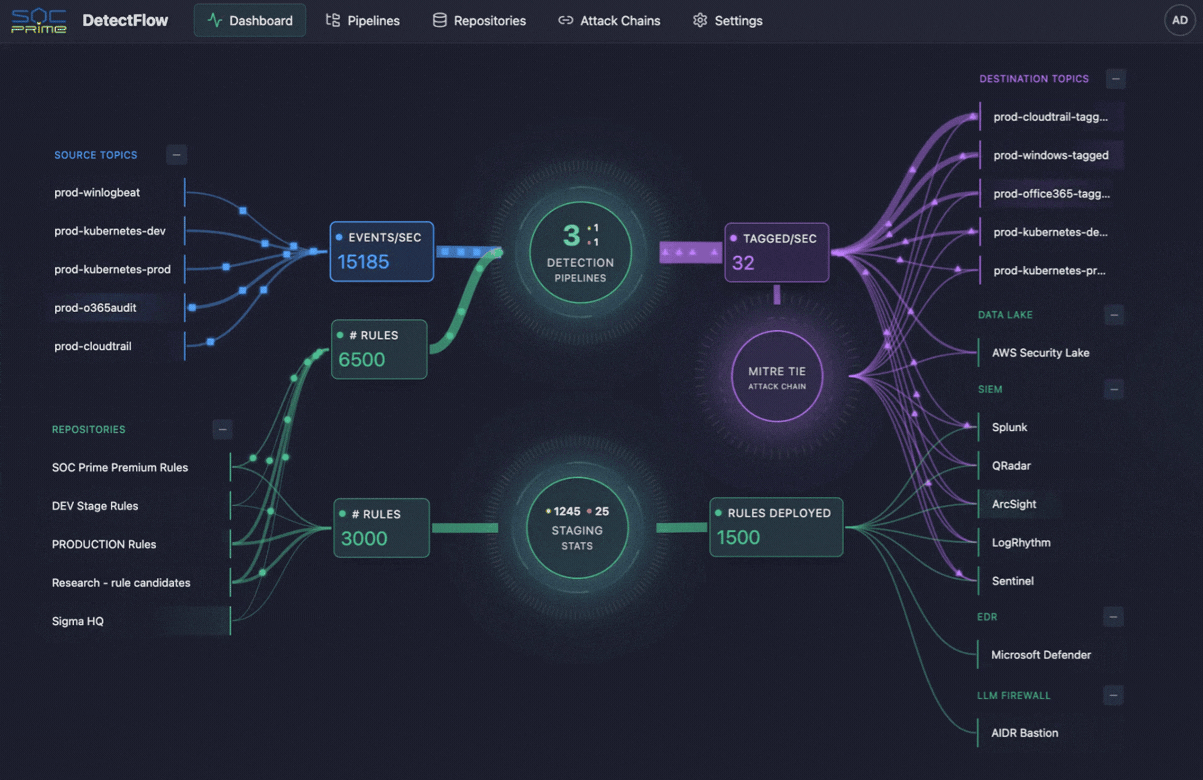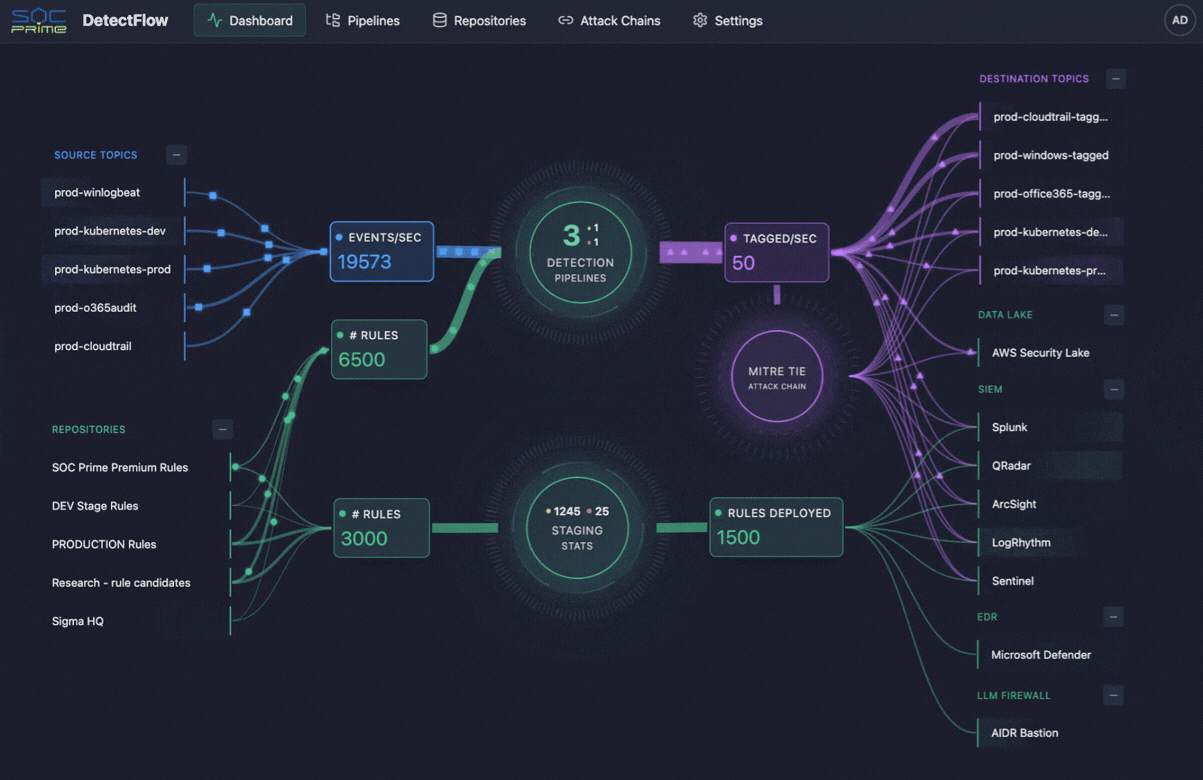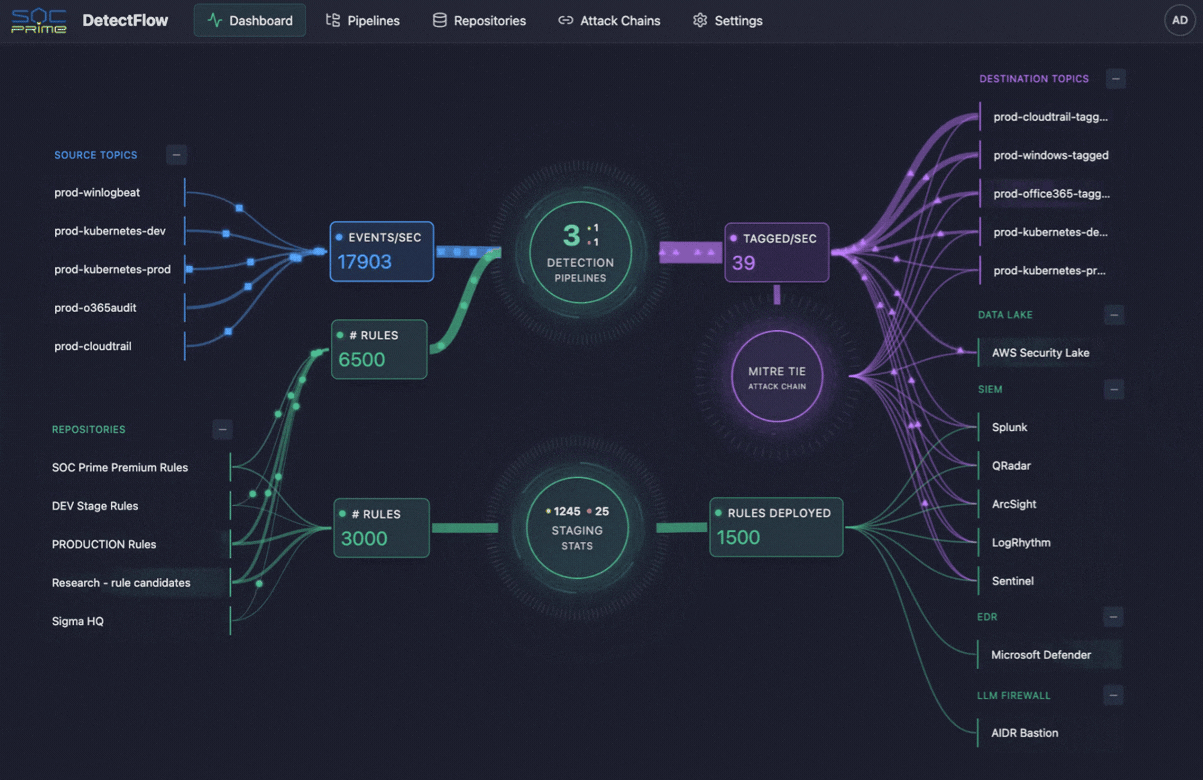
La stessa logica sta iniziando a plasmare anche le operazioni di cybersecurity. È qui che entrano in gioco strumenti come DetectFlow di SOC Prime. DetectFlow sposta il layer di detection direttamente nella pipeline, consentendo ai team SOC di eseguire decine di migliaia di regole Sigma su stream Kafka live tramite Apache Flink, con tagging, enrichment e concatenazione degli eventi nella fase pre-SIEM, così da scalare senza i consueti limiti imposti dai vendor in termini di velocità, capacità o costo.
Che cos’è un Observability Pipeline?
Un observability pipeline è la soluzione che sposta la telemetry dalle sorgenti alle destinazioni eseguendo attività come trasformazione, arricchimento e aggregazione. In concreto, acquisisce log, metriche, trace ed eventi, quindi prepara questi dati prima che raggiungano piattaforme di monitoring, SIEM, data lake o storage a lungo termine. Lungo il percorso, gli observability pipeline possono filtrare i dati rumorosi, arricchire i record con contesto, aggregare stream ad alto volume, proteggere i campi sensibili e instradare ciascun tipo di dato verso la destinazione più appropriata.
Questo diventa fondamentale man mano che la telemetry cresce in ambienti basati su microservizi, container, servizi cloud e sistemi distribuiti. Senza una pipeline, i team spesso inoltrano tutto per impostazione predefinita, aumentando i costi, aggiungendo rumore e rendendo più difficile la gestione dei dati tra più strumenti e ambienti.
Gli observability pipeline aiutano a risolvere diverse sfide comuni:
- Sovraccarico di dati. Un volume elevato di telemetry rende più difficile separare i segnali utili dai dati di scarso valore, soprattutto quando log, metriche e trace arrivano contemporaneamente da molti sistemi diversi.
- Aumento dei costi di storage ed elaborazione. Inviare tutti i dati alle piattaforme downstream fa crescere i costi di ingestione, indicizzazione e retention, anche quando gran parte di quei dati aggiunge poco valore.
- Dati rumorosi. Telemetry duplicata, a bassa priorità o con scarso contesto può sommergere i segnali che contano davvero per troubleshooting, sicurezza e analisi delle prestazioni.
- Rischi di compliance e sicurezza. Log e stream di telemetry possono contenere dati personali o regolamentati, aumentando i rischi di compliance e privacy quando vengono inoltrati o archiviati senza un’adeguata mascheratura o redazione.
- Infrastruttura complessa. I team spesso devono inviare set di dati diversi a destinazioni diverse, come strumenti di monitoring, SIEM e storage a costo inferiore, cosa che diventa difficile da gestire senza un control plane centralizzato.
- Migrazione e flessibilità verso i vendor. Le pipeline rendono più semplice rimodellare e reindirizzare la telemetry verso nuovi strumenti o destinazioni parallele senza ricostruire la raccolta da zero.
In termini semplici, un observability pipeline offre ai team maggiore controllo sulla telemetry. Aiuta le organizzazioni a mantenere i segnali utili, migliorare il contesto e inviare ogni stream dove si integra meglio.
Come funzionano gli Observability Pipeline
A livello pratico, gli observability pipeline creano un flusso unico per gestire i dati di telemetry. Invece di coordinare molteplici passaggi tra sorgenti e destinazioni, i team possono operare attraverso un unico layer di controllo che prepara i dati per diversi casi d’uso operativi e di sicurezza.
Collect
Il primo passaggio consiste nel raccogliere dati da tutto l’ambiente organizzativo. Questo può includere log applicativi, metriche infrastrutturali, eventi cloud, dati dei container e record di sicurezza. Convogliare questi input in un’unica pipeline offre ai team un punto di partenza più coerente e riduce la necessità di connessioni separate tra ogni sorgente e ogni strumento.
Process
Una volta che i dati entrano nella pipeline, possono essere adattati alle esigenze del business. I team possono standardizzare i formati, arricchire i record con metadati, rimuovere eventi duplicati, mascherare campi sensibili o ridurre il dettaglio non necessario. Questo passaggio rende i dati più utilizzabili, sia che l’obiettivo sia il troubleshooting, la compliance, la retention a lungo termine o l’analisi di sicurezza.
Route
Dopo l’elaborazione, la pipeline invia i dati alla destinazione corretta. I record ad alta priorità possono finire su una piattaforma di monitoring o in un SIEM per una visibilità immediata, mentre altri dati possono essere archiviati, conservati in un data lake o instradati verso storage a costo inferiore. Questo rende più semplice supportare team diversi senza costringere ogni sistema a gestire gli stessi dati nello stesso modo.
Vantaggi dell’uso di un Observability Pipeline
Un observability pipeline aiuta i team a gestire volumi crescenti di telemetry, migliorare la qualità dei dati e controllare il modo in cui le informazioni vengono utilizzate tra operation e sicurezza. Man mano che gli ambienti diventano più distribuiti, questo livello di controllo assume sempre più valore in termini di costi, prestazioni e rapidità decisionale.
Tra i principali vantaggi troviamo:
- Riduzione dei costi di storage ed elaborazione. Un observability pipeline aiuta a ridurre la spesa non necessaria filtrando gli eventi di scarso valore, deduplicando i record e inviando solo i dati giusti alle piattaforme più costose. In questo modo i team evitano di pagare prezzi elevati per dati che aggiungono poco valore.
- Migliore qualità del segnale. Quando la telemetry rumorosa o incompleta viene ripulita nelle fasi iniziali, i dati che raggiungono gli strumenti downstream diventano più facili da cercare, analizzare e utilizzare. Questo aiuta i team a concentrarsi su ciò che conta davvero, invece di perdersi nel rumore.
- Troubleshooting e indagini più rapidi. Dati preparati meglio accelerano la risposta agli incidenti. I team operation possono identificare più rapidamente i problemi di performance, mentre i team security possono inviare record più puliti e pertinenti ai SIEM e ad altri strumenti di detection senza sommergere gli analisti di rumore.
- Compliance e protezione dei dati più robuste. Log e telemetry possono contenere informazioni sensibili o regolamentate. Una pipeline semplifica la mascheratura, la redazione o l’instradamento corretto di questi dati prima che vengano archiviati o condivisi, supportando la compliance e riducendo il rischio.
- Maggiore flessibilità tra strumenti e team. Team diversi hanno bisogno di viste diverse sugli stessi dati. Un observability pipeline semplifica l’instradamento di stream specifici verso piattaforme di monitoring, data lake, SIEM o storage a costo inferiore senza ricostruire la raccolta ogni volta che cambiano i requisiti.
- Migliore scalabilità per gli ambienti moderni. Con la crescita dell’infrastruttura tra cloud, container e sistemi distribuiti, le pipeline aiutano le organizzazioni a scalare la gestione della telemetry in modo più controllato e sostenibile.
In sostanza, il valore di un observability pipeline ruota attorno al controllo. Aiuta i team a ridurre gli sprechi, migliorare la qualità del segnale, supportare sicurezza e compliance e sfruttare meglio la telemetry in tutta l’organizzazione.
Observability Pipeline nel Cloud
Gli ambienti cloud rendono l’observability più difficile perché introducono più dinamismo, più dipendenze e una quantità molto maggiore di telemetry da gestire. Microservizi, container, Kubernetes e workload di breve durata producono segnali che cambiano rapidamente e si accumulano altrettanto velocemente. Nel research summary di Chronosphere sull’observability cloud-native, l’87% degli ingegneri ha dichiarato che le architetture cloud-native hanno reso più complessa l’individuazione e la risoluzione degli incidenti, mentre il 96% afferma di sentirsi al limite delle proprie capacità operative.
Questa complessità crea un problema concreto per il business. I team hanno bisogno di un’ampia visibilità per capire cosa sta accadendo tra servizi cloud, applicazioni e infrastrutture, ma inoltrare tutto per impostazione predefinita diventa rapidamente costoso e difficile da gestire. Gli esperti descrivono il cambiamento del mercato come un passaggio dal volume al valore, spinto dall’aumento dei costi della telemetry, dai workload AI e dalla necessità di una visibilità più disciplinata.
È qui che gli observability pipeline diventano particolarmente utili nel cloud. Una pipeline offre ai team un layer di controllo tra le sorgenti dati e gli strumenti downstream, così possono filtrare i record rumorosi, arricchire quelli importanti e instradare ogni stream verso la destinazione corretta. Questo significa meno sprechi sulle piattaforme premium, segnali di qualità superiore per il troubleshooting e maggiore flessibilità tra strumenti di monitoring, storage e sicurezza. Negli ambienti cloud-native, questo tipo di controllo non è più un semplice vantaggio aggiuntivo.
L’angolo cloud conta anche per la cybersecurity. I team security si affidano alla stessa telemetry cloud per threat detection, indagini e compliance, ma il volume grezzo può facilmente sopraffare i SIEM e nascondere gli eventi che contano davvero. Un observability pipeline aiuta già nelle prime fasi del flusso, riducendo il rumore, migliorando il contesto e inviando i record di maggior valore ai sistemi corretti. È anche qui che DetectFlow di SOC Prime si inserisce in modo naturale, avvicinando la detection all’ingestione affinché i team possano valutare, arricchire e correlare gli eventi prima che diventino un sovraccarico downstream.
Observability Pipeline: Un layer più intelligente per le Security Operations
Un observability pipeline offre ai team qualcosa di cui hanno sempre più bisogno negli ambienti moderni: controllo prima che i dati si trasformino in costo, rumore e lentezza decisionale. Più telemetry raccolgono le organizzazioni, più diventa importante filtrarla, arricchirla, trasformarla e instradarla con uno scopo preciso. Questo rende gli observability pipeline utili ben oltre il solo monitoring. Aiutano a migliorare la qualità dei dati, mantenere efficienti le piattaforme downstream e creare una base più solida sia per le operation sia per la sicurezza.
In particolare, i team security affrontano lo stesso problema della telemetry, ma con implicazioni più critiche. I SIEM hanno limiti pratici, il numero di regole non può crescere all’infinito e una quantità eccessiva di dati grezzi può imporre un carico enorme all’analisi di sicurezza. È qui che DetectFlow aggiunge un layer di valore concreto, estendendo la logica dell’observability pipeline alla threat detection e spostando la detection più vicino al layer di ingestione.
DetectFlow esegue decine di migliaia di detection Sigma su stream Kafka live utilizzando Apache Flink, correla eventi attraverso più sorgenti di log nella fase pre-SIEM e utilizza Flink Agent insieme al contesto delle minacce attive per un’analisi AI-powered. In pratica, questo consente ai team SOC di ridurre il rumore prima, far emergere più velocemente le attack chain e migliorare la chiarezza investigativa prima che gli strumenti downstream vengano sopraffatti.