Observability begann als ein Problem der Sichtbarkeit. Heute wird sie jedoch ebenso als Kontrollherausforderung verstanden, weil Teams die täglich durch die Unternehmensumgebung fließenden Telemetrie-Mengen steuern müssen. Die meisten Unternehmen erfassen bereits große Volumina an Logs, Metriken, Events und Traces. Die eigentliche Herausforderung besteht heute darin, diese Datenmengen zu verwalten, bevor sie kostspielige Downstream-Tools erreichen. Gartner definiert Observability-Plattformen als Systeme, die Telemetrie erfassen, um Teams dabei zu helfen, Zustand, Performance und Verhalten von Anwendungen, Services und Infrastrukturen zu verstehen. Das ist relevant, weil Verlangsamungen oder Ausfälle von Systemen weit über die technische Ebene hinausgehen und Umsatz, Kundenwahrnehmung sowie Markenimage beeinflussen.
Daraus entsteht ein bekanntes Paradoxon. Komplexe Umgebungen erfordern eine breite Telemetrie-Abdeckung, zugleich können große Datenvolumina schnell teuer und schwer beherrschbar werden. Wenn jedes Signal standardmäßig weitergeleitet wird, vermischen sich wertvolle Erkenntnisse mit Duplikaten, Daten mit geringem Mehrwert sowie steigenden Speicher- und Verarbeitungskosten. Gartner berichtet, dass die Ausgaben für Observability jährlich um rund 20 % steigen und viele Unternehmen bereits mehr als 800.000 US-Dollar pro Jahr ausgeben. Der Trend zeigt zudem, dass bis 2028 80 % der Unternehmen ohne Kostenkontrollen für Observability ihre Ausgaben um mehr als 50 % überschreiten werden.
Dieser Druck veranlasst Teams dazu, früher im Datenfluss für mehr Kontrolle zu sorgen. Observability Pipelines erfüllen genau diesen Bedarf, indem sie Teams eine praktische Möglichkeit geben, Daten zu filtern, anzureichern, zu transformieren und weiterzuleiten, bevor daraus Rauschen, Verschwendung und operative Reibung in Downstream-Systemen entstehen.
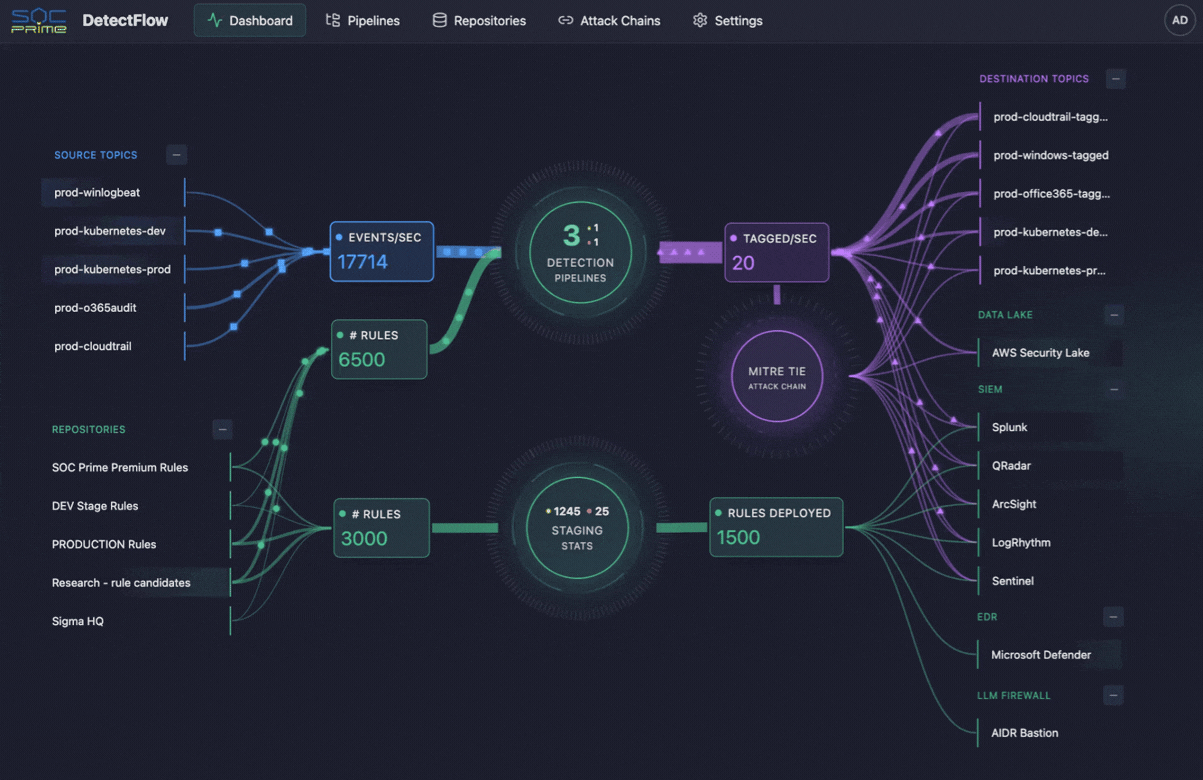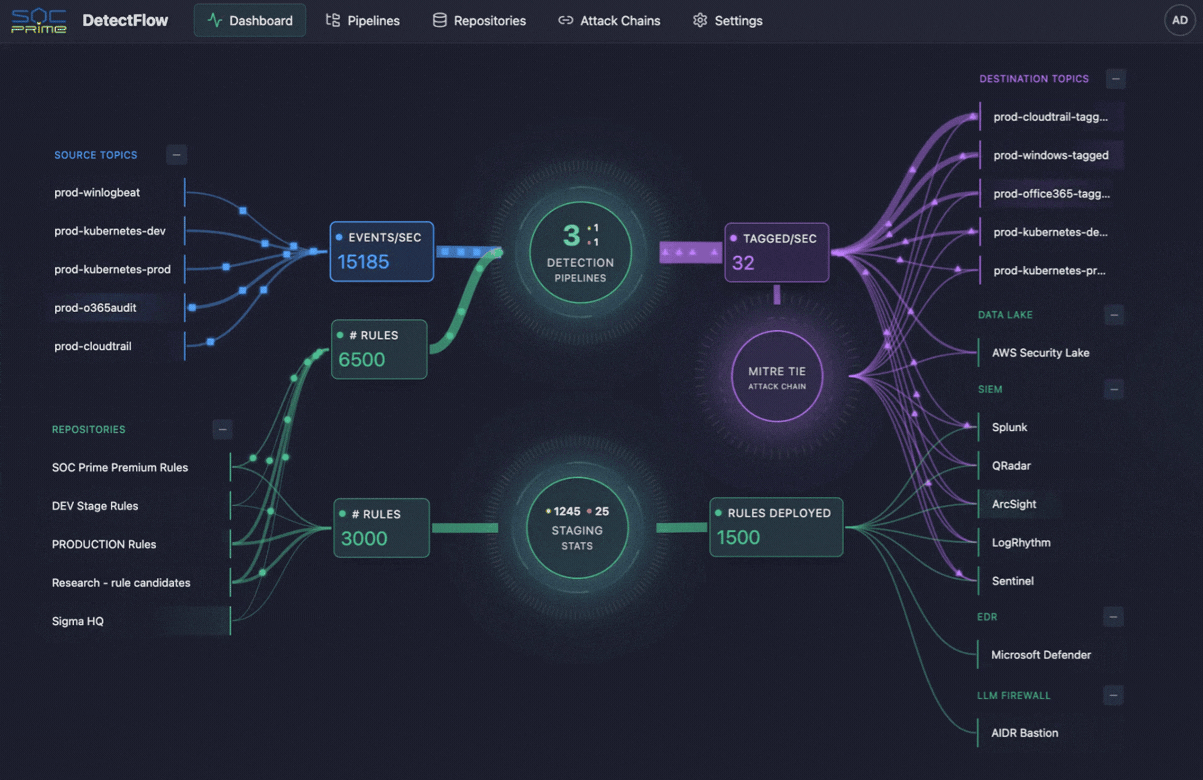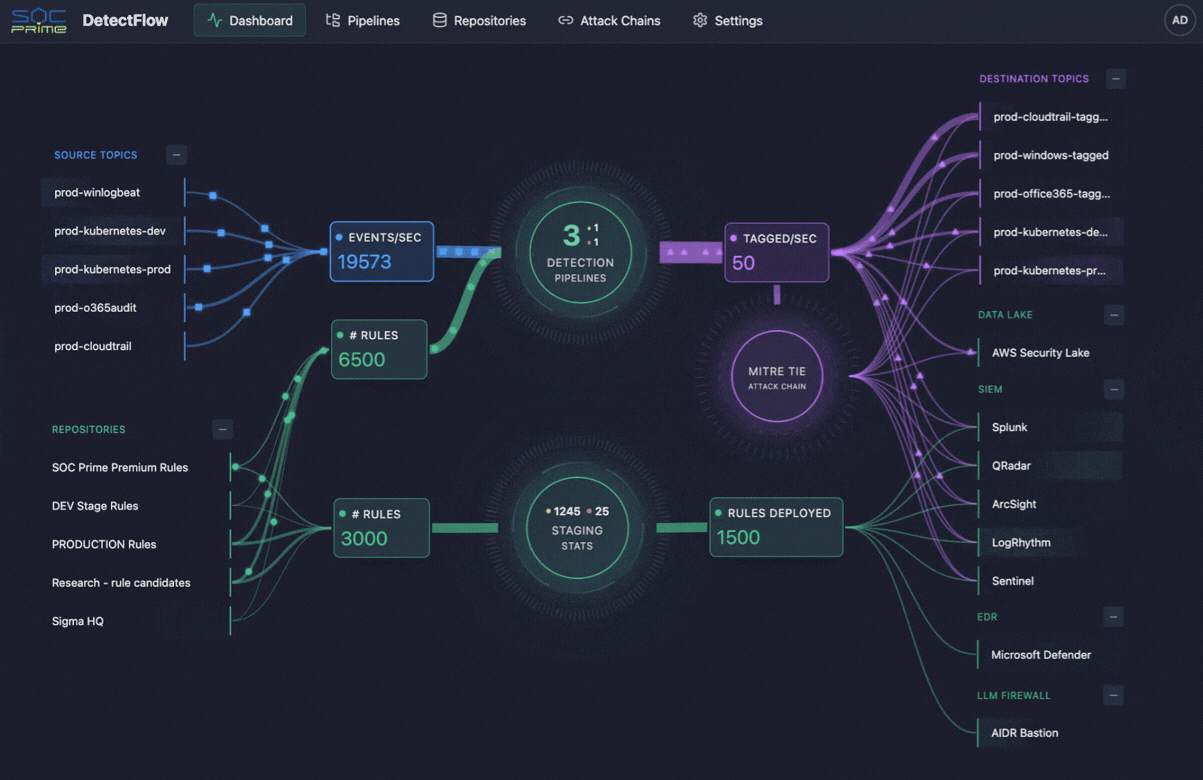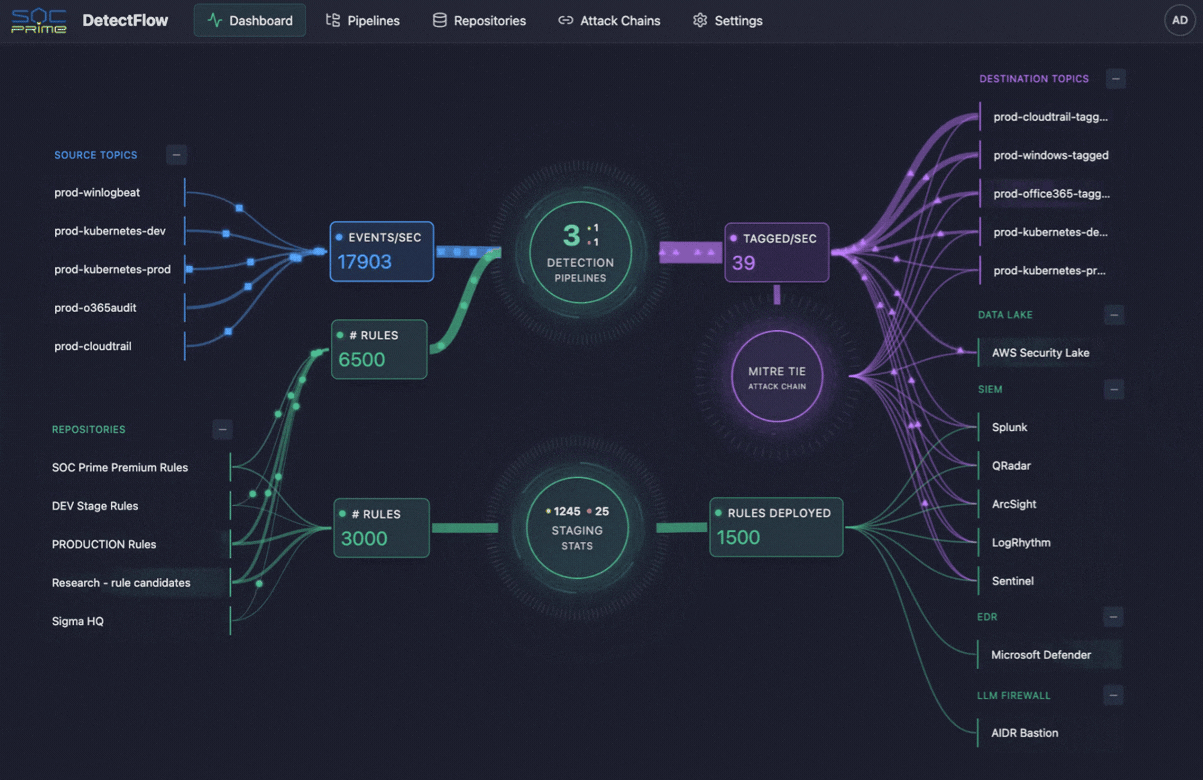
Dieselbe Logik prägt zunehmend auch den Cybersecurity-Betrieb. Genau hier kommen Tools wie SOC Prime’s DetectFlow ins Spiel. DetectFlow verlagert die Detection-Ebene direkt in die Pipeline und ermöglicht es SOC-Teams, Zehntausende Sigma-Regeln auf Live-Kafka-Streams mit Apache Flink auszuführen sowie Events bereits vor der SIEM-Stufe zu taggen, anzureichern und zu verketten, um ohne die üblichen herstellerbedingten Grenzen bei Geschwindigkeit, Kapazität oder Kosten zu skalieren.
Was ist eine Observability Pipeline?
Eine Observability Pipeline ist die Lösung, die Telemetrie von Quellen zu Zielen transportiert und dabei Aufgaben wie Transformation, Anreicherung und Aggregation ausführt. Konkret nimmt sie Logs, Metriken, Traces und Events auf und bereitet diese Daten auf, bevor sie Monitoring-Plattformen, SIEMs, Data Lakes oder langfristige Speicher erreichen. Dabei können Observability Pipelines verrauschte Daten filtern, Datensätze mit Kontext anreichern, Streams mit hohem Volumen aggregieren, sensible Felder absichern und jeden Datentyp an das Ziel weiterleiten, an dem er den größten Nutzen bringt.
Das wird umso wichtiger, je stärker die Telemetrie über Microservices, Container, Cloud-Services und verteilte Systeme hinweg wächst. Ohne eine Pipeline leiten Teams häufig standardmäßig alles weiter, was die Kosten erhöht, mehr Rauschen erzeugt und das Datenhandling über mehrere Tools und Umgebungen hinweg schwerer steuerbar macht.
Observability Pipelines helfen dabei, mehrere häufige Herausforderungen zu lösen:
- Datenüberlastung. Hohe Telemetrie-Volumina erschweren es, nützliche Signale von Daten mit geringem Mehrwert zu trennen, insbesondere wenn Logs, Metriken und Traces gleichzeitig aus vielen verschiedenen Systemen eintreffen.
- Steigende Speicher- und Verarbeitungskosten. Wenn alle Daten an Downstream-Plattformen gesendet werden, steigen Ingest-, Indexierungs- und Aufbewahrungskosten, selbst wenn ein großer Teil dieser Daten nur wenig Mehrwert liefert.
- Verrauschte Daten. Doppelte, niedrig priorisierte oder kontextarme Telemetrie kann genau die Signale überdecken, die für Troubleshooting, Security und Performance-Analysen tatsächlich relevant sind.
- Compliance- und Sicherheitsrisiken. Logs und Telemetrie-Streams können personenbezogene oder regulierte Daten enthalten, was Compliance- und Datenschutzrisiken erhöht, wenn diese ohne angemessenes Masking oder Redaction weitergeleitet oder gespeichert werden.
- Komplexe Infrastruktur. Teams müssen häufig unterschiedliche Datensätze an verschiedene Ziele senden, etwa an Monitoring-Tools, SIEMs und kostengünstigeren Storage. Ohne eine zentrale Control Plane wird das schwer beherrschbar.
- Migration und Vendor-Flexibilität. Pipelines erleichtern es, Telemetrie für neue Tools oder parallele Ziele umzustrukturieren und umzuleiten, ohne die Datenerfassung von Grund auf neu aufzubauen.
Vereinfacht gesagt verschafft eine Observability Pipeline Teams mehr Kontrolle über Telemetrie. Sie hilft Unternehmen dabei, nützliche Signale zu erhalten, den Kontext zu verbessern und jeden Datenstrom dorthin zu senden, wo er am besten passt.
Wie Observability Pipelines funktionieren
Auf praktischer Ebene schaffen Observability Pipelines einen einheitlichen Ablauf für die Verarbeitung von Telemetriedaten. Anstatt mehrere Übergaben zwischen Quellen und Zielen zu steuern, können Teams über eine zentrale Control Layer arbeiten, die Daten für unterschiedliche operative und sicherheitsbezogene Anwendungsfälle vorbereitet.
Erfassen
Der erste Schritt besteht darin, Daten aus der gesamten Unternehmensumgebung zu erfassen. Dazu gehören Application Logs, Infrastruktur-Metriken, Cloud-Events, Container-Daten und Security Records. Wenn diese Eingaben in einer Pipeline zusammengeführt werden, erhalten Teams einen konsistenteren Ausgangspunkt und benötigen weniger separate Verbindungen zwischen jeder Quelle und jedem Tool.
Verarbeiten
Sobald Daten in die Pipeline gelangen, können sie an die Anforderungen des Unternehmens angepasst werden. Teams können Formate standardisieren, Datensätze mit Metadaten anreichern, doppelte Events entfernen, sensible Felder maskieren oder unnötige Details reduzieren. Dieser Schritt macht die Daten besser nutzbar – unabhängig davon, ob das Ziel Troubleshooting, Compliance, langfristige Aufbewahrung oder Security-Analyse ist.
Weiterleiten
Nach der Verarbeitung sendet die Pipeline Daten an das richtige Ziel. Datensätze mit hoher Priorität können für sofortige Sichtbarkeit an eine Monitoring-Plattform oder ein SIEM gehen, während andere Daten archiviert, in einem Data Lake gespeichert oder an kostengünstigeren Storage weitergeleitet werden. So lassen sich unterschiedliche Teams einfacher unterstützen, ohne dass jedes System dieselben Daten auf dieselbe Weise verarbeiten muss.
Vorteile einer Observability Pipeline
Eine Observability Pipeline hilft Teams dabei, wachsende Telemetrie-Volumina zu steuern, die Datenqualität zu verbessern und zu kontrollieren, wie Informationen in Betrieb und Security genutzt werden. Je verteilter Umgebungen werden, desto wichtiger wird diese Art von Kontrolle für Kosten, Performance und schnellere Entscheidungsfindung.
Zu den wichtigsten Vorteilen gehören:
- Niedrigere Speicher- und Verarbeitungskosten. Eine Observability Pipeline hilft dabei, unnötige Ausgaben zu senken, indem Events mit geringem Mehrwert gefiltert, Datensätze dedupliziert und nur die richtigen Daten an kostenintensive Plattformen gesendet werden. So zahlen Teams keinen Höchstpreis für Daten, die nur wenig Nutzen bringen.
- Bessere Signalqualität. Wenn verrauschte oder unvollständige Telemetrie früher bereinigt wird, lassen sich die Daten, die Downstream-Tools erreichen, leichter durchsuchen, analysieren und nutzen. Das hilft Teams, sich auf das Wesentliche zu konzentrieren, statt sich durch Datenballast zu arbeiten.
- Schnelleres Troubleshooting und schnellere Untersuchungen. Besser vorbereitete Daten beschleunigen die Reaktion auf Vorfälle. Operations-Teams können Performance-Probleme schneller identifizieren, während Security-Teams sauberere und relevantere Datensätze in SIEMs und andere Detection-Tools einspeisen können, ohne Analysten mit Rauschen zu überlasten.
- Stärkere Compliance und besserer Datenschutz. Logs und Telemetrie können sensible oder regulierte Informationen enthalten. Eine Pipeline erleichtert es, solche Daten vor der Speicherung oder Weitergabe korrekt zu maskieren, zu redigieren oder gezielt weiterzuleiten, was Compliance unterstützt und Risiken reduziert.
- Mehr Flexibilität über Tools und Teams hinweg. Unterschiedliche Teams benötigen unterschiedliche Sichten auf dieselben Daten. Eine Observability Pipeline erleichtert es, bestimmte Datenströme an Monitoring-Plattformen, Data Lakes, SIEMs oder kostengünstigeren Storage zu leiten, ohne die Datenerfassung bei jeder Anforderungsänderung neu aufbauen zu müssen.
- Bessere Skalierbarkeit für moderne Umgebungen. Wenn Infrastrukturen über Cloud, Container und verteilte Systeme hinweg wachsen, helfen Pipelines Unternehmen dabei, das Telemetrie-Handling kontrollierter und nachhaltiger zu skalieren.
Im Kern läuft der Wert einer Observability Pipeline auf Kontrolle hinaus. Sie hilft Teams, Verschwendung zu reduzieren, die Signalqualität zu verbessern, Security und Compliance zu unterstützen und Telemetrie im gesamten Unternehmen besser zu nutzen.
Observability Pipeline in der Cloud
Cloud-Umgebungen machen Observability schwieriger, weil sie mehr Dynamik, mehr Abhängigkeiten und deutlich mehr Telemetrie mit sich bringen. Microservices, Container, Kubernetes und kurzlebige Workloads erzeugen Signale, die sich schnell verändern und schnell anwachsen. In der cloud-nativen Observability- Research Summary von Chronosphere gaben 87 % der Engineers an, dass cloud-native Architekturen die Erkennung und Behebung von Incidents komplexer gemacht haben, und 96 % sagten, dass sie an ihre Belastungsgrenzen stoßen.
Diese Komplexität schafft ein praktisches Problem für das Unternehmen. Teams benötigen eine breite Sichtbarkeit, um zu verstehen, was in Cloud-Services, Anwendungen und Infrastrukturen geschieht. Doch wenn standardmäßig alles weitergeleitet wird, wird dies schnell teuer und schwer beherrschbar. Experten beschreiben den Marktwechsel als eine Bewegung von Volumen hin zu Wert – getrieben durch steigende Telemetrie-Kosten, AI-Workloads und den Bedarf an stärker disziplinierter Sichtbarkeit.
Genau hier werden Observability Pipelines in der Cloud besonders nützlich. Eine Pipeline verschafft Teams eine Control Layer zwischen Datenquellen und Downstream-Tools, sodass sie verrauschte Datensätze filtern, wichtige Informationen anreichern und jeden Stream an das richtige Ziel weiterleiten können. Das bedeutet weniger Verschwendung auf Premium-Plattformen, bessere Signale für Troubleshooting und mehr Flexibilität über Monitoring-, Storage- und Security-Tools hinweg. In cloud-nativen Umgebungen ist diese Art von Kontrolle längst kein Nice-to-have mehr.
Die Cloud-Perspektive ist auch für Cybersecurity relevant. Security-Teams verlassen sich auf dieselbe Cloud-Telemetrie für Threat Detection, Investigation und Compliance, doch rohe Datenmengen können SIEMs überlasten und genau die Events verdecken, die relevant sind. Eine Observability Pipeline hilft früher im Datenfluss, indem sie Rauschen reduziert, den Kontext verbessert und höherwertige Datensätze an die richtigen Systeme sendet. Genau hier passt auch SOC Prime’s DetectFlow natürlich ins Bild: Es verlagert Detection näher an den Ingest, sodass Teams Events bewerten, anreichern und korrelieren können, bevor sie in Downstream-Systemen zur Überlastung führen.
Observability Pipeline: Eine intelligentere Schicht für Security Operations
Eine Observability Pipeline gibt Teams etwas, das sie in modernen Umgebungen zunehmend benötigen: Kontrolle, bevor Daten zu Kosten, Rauschen und langsamen Entscheidungen führen. Je mehr Telemetrie Unternehmen erfassen, desto wichtiger wird es, sie gezielt zu filtern, anzureichern, zu transformieren und weiterzuleiten. Dadurch werden Observability Pipelines weit über klassisches Monitoring hinaus nützlich. Sie verbessern die Datenqualität, halten Downstream-Plattformen effizient und schaffen eine stärkere Grundlage für Operations und Security gleichermaßen.
Bemerkenswert ist, dass Security-Teams mit demselben Telemetrie-Problem konfrontiert sind – allerdings mit deutlich höheren Folgen. SIEMs haben praktische Grenzen, Regelmengen skalieren nicht unbegrenzt, und zu viele Rohdaten können die Sicherheitsanalyse massiv belasten. Genau hier schafft DetectFlow eine zusätzliche Wertebene, indem es die Logik der Observability Pipeline in die Threat Detection erweitert und Detection näher an die Ingestion verlagert.
DetectFlow führt Zehntausende Sigma-Detections auf Live-Kafka-Streams mit Apache Flink aus, korreliert Events aus mehreren Log-Quellen bereits vor der SIEM-Stufe und nutzt Flink Agent plus aktiven Threat Context für AI-gestützte Analysen. In der Praxis bedeutet das, dass SOC-Teams Rauschen früher reduzieren, Angriffsketten schneller sichtbar machen und die Klarheit von Untersuchungen verbessern können, bevor Downstream-Tools überlastet werden.