Los equipos de seguridad necesitan maneras más rápidas y flexibles de detectar amenazas en entornos de datos complejos. Los flujos de datos de alto volumen dificultan la detección cuando las operaciones están fragmentadas en múltiples herramientas, la agilidad en la respuesta a incidentes es limitada, y gestionar grandes conjuntos de datos es costoso.
Confluent Sigma aborda estos desafíos permitiendo una estrategia de detección de amenazas Shift-Left que mueve la lógica de detección del SIEM a la capa de procesamiento de flujos. Esto permite a los equipos de seguridad detectar amenazas más cerca de la fuente y actuar sobre señales de alta fidelidad mientras un ataque se desarrolla, en lugar de esperar hasta que los datos se normalicen, indexen y almacenen.
Confluent Sigma utiliza Kafka Streams para ejecutar reglas Sigma en datos de origen antes de que lleguen al SIEM. Sigma es el estándar de código abierto, independiente del proveedor, para describir eventos de registro. Al aplicar reglas a flujos de datos en vivo, Confluent Sigma combina la portabilidad de Sigma con la velocidad y escalabilidad de Apache Kafka.
Esta guía te lleva a través de la instalación de Confluent Sigma y presenta escenarios prácticos para sus principales casos de uso, ayudando a los equipos de seguridad a adoptar Detection as Code y responder a las amenazas de manera más efectiva.
Para los equipos de seguridad que requieren escala inmediata y características empresariales avanzadas, SOC Prime Platform proporciona una solución totalmente soportada de nivel empresarial basada en Confluent Sigma.
Módulos y Lógica de Procesamiento de Confluent Sigma
Confluent Sigma se compone de tres módulos principales:
- sigma-parser: Una biblioteca Java que proporciona la funcionalidad principal para leer y procesar reglas Sigma.
- sigma-streams-ui: Una interfaz de usuario orientada al desarrollo para interactuar con el proceso de Sigma Streams, permitiendo a los usuarios ver reglas publicadas, añadir o editar reglas, monitorear el estado del procesador y visualizar detecciones.
- sigma-streams: El módulo principal del proyecto, que contiene el procesador de flujo real y los scripts de línea de comandos asociados.
El procesador Sigma Streams aprovecha Kafka Streams para aplicar de manera eficiente la lógica de detección basada en el tipo de regla:
- Topología Simple: Esta topología admite una sub-topología para muchas reglas y se utiliza para detecciones no agregativas basadas en un solo registro de evento. El procesador utiliza la función
flatMapValuesde Kafka Streams para transformar registros. Itera a través de cada regla para filtrar, valida los datos en streaming contra la regla DSL y añade los resultados de coincidencias a una lista de salida. Este proceso es altamente eficiente, y el registro de detección final se envía inmediatamente al tema de salida dinámico. - Topología Agregada: Esta topología requiere una sub-topología para cada regla para gestionar el estado y se utiliza para detecciones complejas y con estado que involucran conteo o ventanas temporales. Para reglas avanzadas, el procesador primero valida los datos y luego los agrupa por una clave definida (por ejemplo,
id_orig_h). Aplica una ventana deslizante de la regla (por ejemplo,timeframe: 10s), cuenta el número de instancias dentro de esa ventana y finalmente filtra basado en la agregación y operación en la regla (por ejemplo,count() > 10). El registro de detección agregado final se envía luego al tema de salida dinámico.
Cuando ocurre una coincidencia, el evento de detección resultante se enriquece antes de la salida:
- Metadatos de la Regla: El evento incluye el
title,author,product, yservice. - Mapeo de Campos: Si la regla utiliza una expresión regular (regex), los campos extraídos se añaden a la salida.
- Campos Personalizados: Cualquier metadato personalizado definido en la regla se incluye para el contexto y para el enrutamiento descendente.
- Salida Dinámica: El resultado se envía al tema especificado por el campo
outputTopicde la regla.
Cómo instalar Confluent Sigma
Paso 1: Comenzando
Confluent Sigma se basa en tres temas principales de Kafka para funcionar. El procesador Sigma Streams monitorea continuamente estos temas para aplicar la lógica y producir detecciones.
- Tema de reglas: Contiene reglas Sigma
- Tema de datos de entrada:Contiene datos de eventos entrantes (por ejemplo, registros).
- Tema de salida:Contiene eventos que coincidieron con una o más reglas Sigma.
Las reglas Sigma se publican en un tema dedicado de Kafka, que el procesador Sigma Streams monitorea. Estas reglas se aplican en tiempo real a los datos de otro tema suscrito. Cualquier registro que coincida con las reglas se reenvía a un tema de salida designado.
Nota: Los tres temas deben definirse en la configuración. Sin embargo, las reglas pueden sobrescribir el destino de salida para enrutarse a diferentes temas según la lógica específica de la regla.
Antes de comenzar con Confluent Sigma, asegúrate de tener lo siguiente:
- Entorno Kafka
- Un clúster Apache Kafka en funcionamiento (local o de producción).
- Acceso a herramientas CLI de Kafka (kafka-topics, kafka-console-producer, kafka-console-consumer).
- Conexión de red adecuada y permisos apropiados para crear y gestionar temas.
- Aplicación Sigma Streams
- Descargar e instalar la aplicación Confluent Sigma Streams.
- Asegúrate de que el script
bin/confluent-sigma.shsea ejecutable.
- Reglas Sigma
- Archivos de reglas Sigma válidos en formato YAML o JSON.
- Cada regla debe seguir la especificación Sigma.
- Cargador de Reglas Sigma (opcional)
- Instala la utilidad SigmaRuleLoader si planeas cargar reglas en bloque.
- Archivos de Configuración
Asegúrate de tener un archivo de configuración sigma.properties válido con:- Tema de reglas
- Tema de datos de entrada:
- Tema de salida:
- Configuraciones del servidor de inicio
Paso 2: Creación de un Tema de Reglas Sigma
Antes de añadir una regla Sigma, asegúrate de crear un tema de reglas Sigma. A continuación, se muestra un ejemplo de cómo crear un tema de reglas Sigma:kafka-topics --bootstrap-server localhost:9092 --topic sigma_rules --replication-factor 1 --partitions 1 --config cleanup.policy=compact --create
Nota: Para implementaciones de producción, usa un factor de replicación de al menos 3. Dado que las reglas son relativamente pocas en comparación con los datos de eventos, one una partición suele ser suficiente.
Paso 3. Cargar Reglas Sigma
Las reglas Sigma se almacenan en un tema Kafka especificado por el usuario. La clave de cada registro Kafka debe cumplir los siguientes requisitos:
- Tipo:
string - Establecer en el campo de título de la regla
Nota: La especificación Sigma no requiere un campo de ID, por lo que los títulos de las reglas deben ser únicos. Las reglas recién publicadas o actualizadas son recogidas automáticamente por un procesador Sigma Streams en funcionamiento.
Las reglas se pueden ingerir en Kafka usando:
- Aplicación SigmaRuleLoader
- The Herramienta de línea de comandos
kafka-console-producerIngestión de Reglas a través de SigmaRuleLoader
Rule Ingestion via SigmaRuleLoader
La aplicación SigmaRuleLoader permite la ingestión masiva o única de reglas como archivos YAML.
Para cargar un solo archivo de reglas Sigma, usa la opción -file. Por ejemplo:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -file zeek_sigma_rule.yml
Para cargar todo el directorio que contiene reglas Sigma, usa la opción -dir:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -dir zeek_sigma_rules
Ingestión de Reglas a través de CLI
También puedes cargar reglas Sigma manualmente a través de una CLI estándar de Kafka, por ejemplo, la Herramienta de línea de comandos kafka-console-producer utilidad:kafka-console-producer --broker-list localhost:9092 --topic sigma-rules --property "key.separator=:"
Aquí hay un fragmento de código de la ingestión de reglas a través de CLI en formato JSON:--property "key.separator=:"
{"title":Sigma Rule Test,"id":"123456789","status":"experimental","description":"This is just a test.", "author":"Test", "date":"1970/01/01","references":["https://confluent.io/"],"tags":["test.test"],"logsource": {"category":"process_creation","product":"windows"},"detection":{"selection":{"CommandLine|contains|all": [" /vss "," /y "]},"condition":"selection"},"fields":["CommandLine","ParentCommandLine"],"falsepositives": ["Administrative activity"],"level":"high"}
Paso 4. Ejecutando la Aplicación Sigma Streams
Confluent Sigma Streams es una aplicación Java que se puede ejecutar directamente o a través del script confluent-sigma.sh . Para ejecutar la aplicación mediante un script, usa el siguiente comando:
bin/confluent-sigma.sh properties-file
Orden de búsqueda de configuración de Confluent Sigma Streams:
- Argumento de la línea de comandos (
properties-file). - variable de entorno
$SIGMAPROPS. environment variable.
Nota: Si no especificas el properties-file, la aplicación verificará la variable de entorno $SIGMAPROPS. variable.
- Si lo anterior no está configurado, la aplicación buscará en los siguientes directorios la
properties-file:~/.config~/.confluent~/tmp
Ver los ejemplos de sigma.properties aquí.
Recomendaciones de Implementación
Recarga Rápida de Reglas a través de un Tema de Kafka
Un desafío operativo significativo es actualizar las reglas de detección sin incurrir en tiempo de inactividad. Reiniciar la aplicación de procesamiento de flujo cada vez que se añade o modifica una regla Sigma es ineficiente y conduce a brechas en la cobertura de detección.
- Recomendación: Crea un tema de Kafka dedicado y compactado para servir como un «tema de reglas». La aplicación confluent-sigma debe consumir de este tema utilizando un GlobalKTable. Cuando se publique una nueva regla Sigma o se actualice en este tema (claveada por un ID de regla único), el GlobalKTable se actualizará automáticamente en casi tiempo real. El flujo de procesamiento de eventos principal entonces puede unirse contra este GlobalKTable, asegurando que siempre tenga el último conjunto de reglas sin necesidad de reinicio.
- Impacto: Esto proporciona una implementación de reglas sin tiempo de inactividad, permitiendo a los analistas de seguridad reaccionar ante nuevas amenazas casi al instante. Desacopla el ciclo de vida de gestión de reglas del ciclo de vida de implementación de la aplicación.
Enriquecer Eventos en el Flujo Antes del Emparejamiento de Reglas
Los registros de seguridad en bruto a menudo carecen del contexto necesario para alertas de alta fidelidad. Por ejemplo, un registro en bruto podría contener una dirección IP pero no su reputación, o un ID de usuario pero no el departamento o rol del usuario. Confiar en el SIEM para todo el enriquecimiento puede retrasar el contexto y crear alertas más ruidosas.
- Recomendación Específica: Antes de la lógica principal de emparejamiento de reglas Sigma, implementa una fase de enriquecimiento dentro de la topología de Kafka Streams. Usa uniones de flujo-tabla para enriquecer el flujo de eventos entrante.
- Inteligencia de Amenazas: Une el flujo de eventos con un GlobalKTable de IPs, dominios o hashes de archivos maliciosos conocidos cargados desde una fuente de inteligencia de amenazas.
- Información de Activos/Usuarios: Une el flujo de eventos con un KTable poblado de un CMDB o fuente de Active Directory para añadir contexto como propietario del dispositivo, criticidad del servidor o rol del usuario.
- Impacto: Esto reduce drásticamente los falsos positivos and aumenta la precisión de la prioridad de las alertas. Un evento que involucre un servidor crítico o un usuario privilegiado puede escalarse inmediatamente. También hace que las alertas enviadas al SIEM sean mucho más valiosas desde el inicio.
Mejores Prácticas
Temas Dedicados de Kafka
- Aislamiento: Usar temas dedicados para diferentes flujos de datos proporciona aislamiento entre ellos. Esto significa que un problema con un flujo de datos (por ejemplo, un repentino aumento de tráfico) es menos probable que afecte a los demás.
- Rendimiento: Los temas dedicados también pueden mejorar el rendimiento al permitirte optimizar la configuración de cada tema para su caso de uso específico. Por ejemplo, puedes establecer un número diferente de particiones o un factor de replicación diferente para cada tema.
Escalabilidad
- Escalado Horizontal: La aplicación Confluent Sigma puede escalarse horizontalmente ejecutando múltiples instancias de la aplicación en paralelo. Cada instancia procesará un subconjunto de los datos, lo que aumentará el rendimiento total del sistema.
- Particionamiento: Para habilitar el escalado horizontal, necesitas particionar tus temas de Kafka. Esto permitirá que varias instancias de la aplicación consuman datos del mismo tema en paralelo. Debes elegir una clave de particionamiento que distribuya los datos uniformemente a través de las particiones.
- Grupos de Consumo: Cuando ejecutas múltiples instancias de la aplicación Confluent Sigma, debes configurarlas para que formen parte del mismo grupo de consumo. Esto asegurará que cada mensaje en el tema de entrada sea procesado solo por una instancia de la aplicación.
Encriptación
Debes usar TLS/SSL para encriptar los datos en tránsito entre los productores, consumidores y los brokers de Kafka. Esto protegerá los datos de escuchas y manipulaciones.
Monitoreo
Es crucial monitorear la salud y el rendimiento de la aplicación Confluent Sigma en un entorno de producción. Debes monitorear las siguientes métricas:
- El número de mensajes procesados
- El número de alertas generadas
- La latencia de la aplicación
- El uso de CPU y memoria de la aplicación
Métricas Clave
Además de las métricas mencionadas anteriormente, también debes monitorear lo siguiente:
- Retraso del Consumidor: Este es el número de mensajes en un tema que aún no han sido procesados por el consumidor. Un alto retraso del consumidor puede indicar que la aplicación no puede seguir el ritmo de la tasa de datos entrantes.
- Latencia de Fin a Fin: Este es el tiempo que tarda un mensaje en viajar del productor al consumidor. Una alta latencia de fin a fin puede indicar un problema con la red o el clúster de Kafka.
Casos de Uso de Confluent Sigma
Confluent Sigma permite a los equipos de seguridad detectar amenazas en tiempo real aplicando reglas Sigma directamente a los streams de Kafka, lo que permite a los Ingenieros de Detección responder a anomalías antes de que los datos lleguen al SIEM y optimizar el refinamiento de reglas.
Los casos de uso clave incluyen los siguientes:
- Detección de Amenazas Shift-Left: Aplica lógica de detección en la fuente, antes de que los registros lleguen al SIEM, permitiendo una respuesta más rápida a ataques en vivo.
- Configurar Pipeline CI/CD para Detecciones: Automatizar la implementación y actualización de reglas en todos los entornos mientras se mejora la eficiencia operativa y la consistencia.
- Versionado de Reglas en Entornos: Mantener un versionado estructurado de las reglas usando temas de Kafka o Git, asegurando trazabilidad y facilidad de reversión.
- Reducir Costos de Ingesta de Logs: Detectar amenazas en vuelo sin ingerir cada registro en el SIEM, reduciendo costos de almacenamiento y procesamiento.
- Eliminar la Latencia de Consultas del SIEM: Acceder a detecciones de alta fidelidad instantáneamente procesando reglas en streams en tiempo real.
- Aumentar la Velocidad de Correlación: Aplicar lógica de agregación y ventana deslizante dentro de Kafka Streams para correlacionar rápidamente eventos y generar alertas.
Confluent Sigma Potenciado por Tecnología de SOC Prime
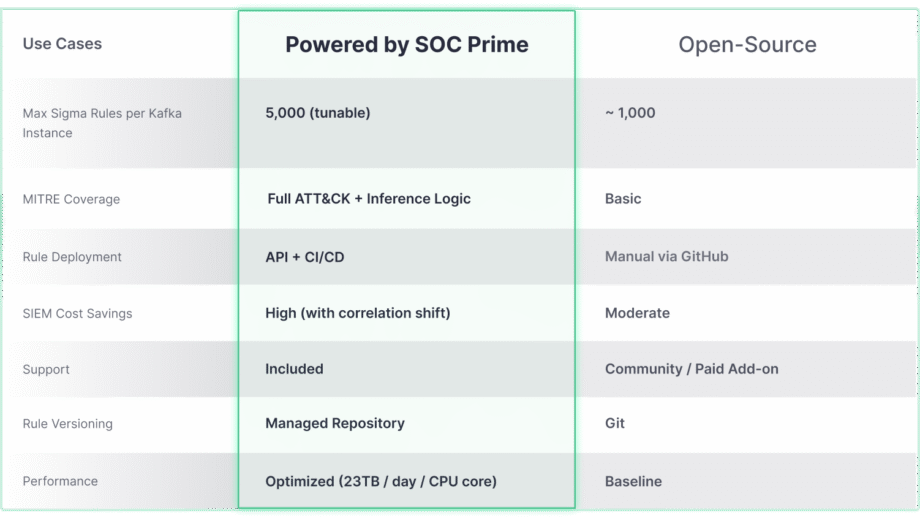
Aunque el proyecto de código abierto Confluent Sigma proporciona una base sólida para la detección Shift-Left, su verdadero potencial para escalar y cubrir amenazas avanzadas se desbloquea cuando se integra con soluciones empresariales avanzadas como SOC Prime. La comparación a continuación destaca cómo las capacidades principales evolucionan para satisfacer las demandas de entornos a gran escala y complejos.
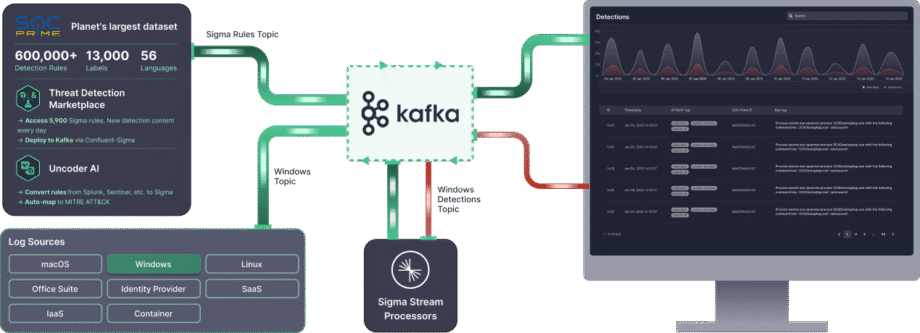
La solución Confluent Sigma & SOC Prime proporciona acceso directo a herramientas y contenido que aceleran drásticamente el ciclo de vida de la detección:
- Threat Detection Marketplace: Al aprovechar el Threat Detection Marketplace, los equipos de seguridad pueden elegir entre más de 15,000 reglas Sigma que abordan amenazas emergentes y transmitirlas directamente al entorno Kafka de manera automatizada.
- Uncoder AI: Con el Uncoder AI de SOC Prime, un IDE y co-piloto para la ingeniería de detección de extremo a extremo, los defensores pueden convertir el código de detección de varios formatos de lenguaje a Sigma, mapearlo automáticamente a MITRE ATT&CK, escribir código desde cero con IA o ajustarlo al vuelo para asegurar una detección de amenazas optimizada.
- Excelencia Operacional: La implementación automatizada a través de APIs y CI/CD asegura un despliegue de reglas consistente y repetible, mientras que el alto rendimiento (hasta 23 TB/día por núcleo de CPU) permite la detección de amenazas en tiempo real y escalable en cualquier entorno.
- Soporte Experto: Confíe en la experiencia de ingeniería de primer nivel de SOC Prime para recibir soporte guiado en la instalación, gestión y escalado del stack de detección de código abierto.