I team di sicurezza hanno bisogno di modi più rapidi e flessibili per rilevare le minacce in ambienti dati complessi. Flussi di dati ad alto volume rendono difficile il rilevamento quando le operazioni sono frammentate su più strumenti, l’agilità nella risposta agli incidenti è limitata e la gestione di grandi dataset è costosa.
Confluent Sigma affronta queste sfide abilitando una strategia di rilevamento delle minacce Shift-Left che sposta la logica di rilevamento fuori dal SIEM e all’interno del livello di elaborazione dei flussi. Questo consente ai team di sicurezza di rilevare le minacce più vicino alla fonte e agire su segnali ad alta fedeltà mentre un attacco è in corso, piuttosto che aspettare che i dati siano normalizzati, indicizzati e memorizzati.
Confluent Sigma utilizza Kafka Streams per eseguire le regole Sigma sui dati sorgente prima che raggiungano il SIEM. Sigma è lo standard open-source, indipendente dal fornitore, per descrivere gli eventi di log. Applicando regole ai flussi di dati live, Confluent Sigma combina la portabilità di Sigma con la velocità e scalabilità di Apache Kafka.
Questa guida ti accompagna nell’installazione di Confluent Sigma e presenta scenari pratici per i suoi principali casi d’uso, aiutando i team di sicurezza ad adottare il rilevamento come codice e a rispondere alle minacce in modo più efficace.
Per i team di sicurezza che richiedono scalabilità immediata e funzionalità avanzate per le imprese, SOC Prime Platform fornisce una soluzione completamente supportata, a livello aziendale basata su Confluent Sigma.
Moduli & Logica di Elaborazione di Confluent Sigma
Confluent Sigma è composto da tre moduli principali:
- sigma-parser: Una libreria Java che fornisce la funzionalità principale per leggere ed elaborare le regole Sigma.
- sigma-streams-ui: Un’interfaccia utente orientata allo sviluppo per interagire con il processo Sigma Streams, consentendo agli utenti di visualizzare le regole pubblicate, aggiungere o modificare regole, monitorare lo stato dei processori e visualizzare le rilevazioni.
- sigma-streams: Il modulo principale del progetto, che contiene il processore di flusso effettivo e gli script da riga di comando associati.
Il processore Sigma Streams sfrutta Kafka Streams per applicare in modo efficiente la logica di rilevamento basata sul tipo di regola:
- Topologia Semplice: Questa topologia supporta una sottotopologia per molte regole ed è utilizzata per rilevazioni non aggreganti basate su un singolo record di evento. Il processore utilizza la funzione
flatMapValuesdi Kafka Streams per trasformare i record. Itera attraverso ciascuna regola per il filtraggio, convalida i dati in streaming rispetto alla regola DSL e aggiunge i risultati della corrispondenza a un elenco di output. Questo processo è altamente efficiente e il record di rilevazione finale viene inviato immediatamente all’argomento di output dinamico. - Topologia Aggregata: Questa topologia richiede una sottotopologia per ciascuna regola per gestire lo stato ed è utilizzata per rilevazioni complesse e stateful che coinvolgono conteggi o finestre temporali. Per le regole avanzate, il processore prima convalida i dati e poi li raggruppa per una chiave definita (es.
id_orig_h). Applica una finestra scorrevole dalla regola (es.timeframe: 10s), conta il numero di istanze all’interno di quella finestra e infine filtra in base all’aggregazione e operazione nella regola (es.count() > 10). Il record finale di rilevazione aggregato viene quindi inviato al topic di output dinamico.
Quando si verifica una corrispondenza, l’evento di rilevazione risultante viene arricchito prima dell’output:
- Metadati della Regola: L’evento include il titolo della regola corrispondente
title,author,product, eservice. - Mappatura dei Campi: Se la regola utilizza un’espressione regolare (regex), i campi estratti vengono aggiunti all’output.
- Campi Personalizzati: Tutti i metadati personalizzati definiti nella regola sono inclusi per il contesto e il routing a valle.
- Output Dinamico: Il risultato viene inviato al topic specificato dal campo
outputTopicdella regola.
Come Installare Confluent Sigma
Passo 1: Iniziare
Confluent Sigma si basa su tre topic principali di Kafka per funzionare. Il processore Sigma Streams monitora continuamente questi topic per applicare la logica e produrre rilevazioni.
- Topic delle regole: Contiene le regole Sigma
- Topic dei dati di input: Contiene i dati degli eventi in arrivo (es. log).
- Topic di output: Contiene eventi che hanno corrisposto a una o più regole Sigma.
Le regole Sigma vengono pubblicate su un topic dedicato di Kafka, che il processore Sigma Streams monitora. Queste regole vengono poi applicate in tempo reale ai dati provenienti da un altro topic sottoscritto. Qualsiasi record che corrisponde alle regole è inoltrato a un topic di output designato.
Nota: Tutti e tre i topic devono essere definiti nella configurazione. Tuttavia, le regole possono sovrascrivere la destinazione dell’output per indirizzare a diversi topic in base alla logica specifica delle regole.
Prima di iniziare con Confluent Sigma, assicurati di avere a disposizione quanto segue:
- Ambiente Kafka
- Un cluster Apache Kafka in esecuzione (locale o di produzione).
- Accesso agli strumenti CLI di Kafka (kafka-topics, kafka-console-producer, kafka-console-consumer).
- Connessione di rete adeguata e permessi appropriati per creare e gestire i topic.
- Applicazione Sigma Streams
- Scaricare e installare l’applicazione Confluent Sigma Streams.
- Assicurarsi che lo script
bin/confluent-sigma.shsia eseguibile.
- Regole Sigma
- File di regole Sigma validi nei formati YAML o JSON.
- Ogni regola dovrebbe seguire la specifica Sigma.
- Caricatore di Regole Sigma (opzionale)
- Installare l’utilità SigmaRuleLoader se si prevede di caricare regole in blocco.
- File di Configurazione
Assicurarsi di avere un file di configurazione sigma.properties valido con:- Topic delle regole
- Topic dei dati di input
- Topic di output
- Impostazioni del server di bootstrap
Passo 2: Creazione di un Topic delle Regole Sigma
Prima di aggiungere una regola Sigma, assicurarsi di creare un topic delle regole Sigma. Di seguito è riportato un esempio di come creare un topic delle regole Sigma:kafka-topics --bootstrap-server localhost:9092 --topic sigma_rules --replication-factor 1 --partitions 1 --config cleanup.policy=compact --create
Nota: Per implementazioni in produzione, utilizzare un fattore di replica di almeno 3. Poiché le regole sono relativamente poche rispetto ai dati degli eventi, one partizione è tipicamente sufficiente.
Passo 3. Caricamento delle Regole Sigma
Le regole Sigma sono memorizzate in un topic Kafka specificato dall’utente. La chiave di ciascun record di Kafka deve soddisfare i seguenti requisiti:
- Tipo:
string - Imposta sul campo titolo della regola
Nota: La specifica Sigma non richiede un campo ID, quindi i titoli delle regole devono essere unici. Le regole pubblicate o aggiornate di recente vengono acquisite automaticamente da un processore Sigma Streams in esecuzione.
Le regole possono essere ingerite in Kafka utilizzando:
- applicazione SigmaRuleLoader
- The
kafka-console-producerda riga di comando
Ingestione delle Regole tramite SigmaRuleLoader
L’applicazione SigmaRuleLoader consente l’ingestione singola o in blocco di regole come file YAML.
Per caricare un singolo file di regola Sigma, utilizzare l’opzione -file. Per esempio:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -file zeek_sigma_rule.yml
Per caricare l’intera directory contenente le regole Sigma, utilizzare l’opzione -dir:sigma-rule-loader.sh -bootStrapServer localhost:9092 -topic sigma-rules -dir zeek_sigma_rules
Ingestione delle Regole tramite CLI
È anche possibile caricare manualmente le regole Sigma tramite un CLI Kafka standard, ad esempio l’utility kafka-console-producer :kafka-console-producer --broker-list localhost:9092 --topic sigma-rules --property "key.separator=:"
Ecco un esempio di codice per l’ingestione delle regole tramite CLI nel formato JSON:--property "key.separator=:"
{"title":Sigma Rule Test,"id":"123456789","status":"experimental","description":"This is just a test.", "author":"Test", "date":"1970/01/01","references":["https://confluent.io/"],"tags":["test.test"],"logsource": {"category":"process_creation","product":"windows"},"detection":{"selection":{"CommandLine|contains|all": [" /vss "," /y "]},"condition":"selection"},"fields":["CommandLine","ParentCommandLine"],"falsepositives": ["Administrative activity"],"level":"high"}
Passo 4. Esecuzione dell’Applicazione Sigma Streams
Confluent Sigma Streams è un’applicazione Java che può essere eseguita direttamente o tramite lo script confluent-sigma.sh . Per eseguire l’applicazione tramite uno script, utilizzare il seguente comando:
bin/confluent-sigma.sh properties-file
Ordine di ricerca della configurazione di Confluent Sigma Streams:
- Argomento da riga di comando (
properties-file). - Variabile d’ambiente
$SIGMAPROPS. Se non si specifica il
Nota: , l’applicazione controllerà la variabile properties-file. Variabile d’ambiente $SIGMAPROPS. Se quest’ultima non è impostata, l’app cercherà nelle seguenti directory il
- ~/tmp
properties-file:~/.config~/.confluent~/tmp
Vedi gli esempi di sigma.properties qui.
Raccomandazioni di Implementazione
Ricaricamento a Caldo delle Regole tramite un Topic Kafka
Una significativa sfida operativa è l’aggiornamento delle regole di rilevamento senza incorrere in tempi di inattività. Riavviare l’applicazione di elaborazione dei flussi ogni volta che viene aggiunta o modificata una regola Sigma è inefficiente e porta a lacune nella copertura del rilevamento.
- Raccomandazione: Creare un topic Kafka dedicato e compatto per servire come “topic delle regole.” L’applicazione confluent-sigma dovrebbe consumare da questo topic usando un GlobalKTable. Quando una nuova o aggiornata regola Sigma viene pubblicata su questo topic (con una chiave unica della regola), il GlobalKTable si aggiornerà automaticamente quasi in tempo reale. Il flusso di elaborazione degli eventi principale può quindi unirsi a questa GlobalKTable, assicurandosi di avere sempre l’ultimo set di regole senza bisogno di un riavvio.
- Impatto: Questo fornisce un’implementazione delle regole senza tempi di inattività, permettendo agli analisti di sicurezza di reagire a nuove minacce quasi istantaneamente. Decoupla il ciclo di vita della gestione delle regole dal ciclo di vita del deployment dell’applicazione.
Arricchire gli Eventi In-Stream prima del Confronto delle Regole
I log di sicurezza grezzi spesso mancano del contesto necessario per avvisi ad alta fedeltà. Ad esempio, un log grezzo potrebbe contenere un indirizzo IP ma non la sua reputazione, o un ID utente ma non il dipartimento o il ruolo dell’utente. Affidarsi al SIEM per tutto l’arricchimento può ritardare il contesto e creare avvisi più rumorosi.
- Raccomandazione Specifica: Prima della logica principale di corrispondenza delle regole Sigma, implementare una fase di arricchimento all’interno della topologia di Kafka Streams. Utilizzare join flusso-tabella per arricchire il flusso di eventi in arrivo.
- Intelligenza sulle Minacce: Unire il flusso di eventi con un GlobalKTable di IP, domini o hash di file maligni noti caricati da un feed di intelligenza sulle minacce.
- Informazioni su Asset/Utente: Unire il flusso di eventi con una KTable popolata da un feed CMDB o Active Directory per aggiungere contesto come proprietario del dispositivo, criticità del server o ruolo dell’utente.
- Impatto: Questo riduce drasticamente i falsi positivi and aumenta l’accuratezza della priorità degli avvisi.Un evento che coinvolge un server critico o un utente privilegiato può essere immediatamente escalato. Inoltre rende gli avvisi inviati al SIEM molto più preziosi out-of-the-box.
Migliori Pratiche
Topic Kafka Dedicati
- Isolamento: Usare topic dedicati per diversi flussi di dati fornisce isolamento tra di essi. Ciò significa che un problema con un flusso di dati (ad es. un improvviso picco di traffico) ha meno probabilità di influire sugli altri.
- Prestazioni: I topic dedicati possono anche migliorare le prestazioni consentendo di ottimizzare la configurazione di ciascun topic per il suo caso d’uso specifico. Ad esempio, puoi impostare un diverso numero di partizioni o un diverso fattore di replica per ciascun topic.
Scalabilità
- Scalabilità Orizzontale: L’applicazione Confluent Sigma può essere scalata orizzontalmente eseguendo più istanze dell’applicazione in parallelo. Ogni istanza elaborerà un sottoinsieme dei dati, il che aumenterà il throughput complessivo del sistema.
- Partizionamento: Per abilitare la scalabilità orizzontale, è necessario partizionare i topic Kafka. Questo consentirà a più istanze dell’applicazione di consumare dati dallo stesso topic in parallelo. Dovresti scegliere una chiave di partizionamento che distribuirà i dati uniformemente tra le partizioni.
- Gruppi di Consumatori: Quando esegui più istanze dell’applicazione Confluent Sigma, dovresti configurarle per fare parte dello stesso gruppo di consumatori. Questo assicurerà che ciascun messaggio nel topic di input sia elaborato da una sola istanza dell’applicazione.
Cifratura
Dovresti utilizzare TLS/SSL per cifrare i dati in transito tra i produttori, i consumatori e i broker Kafka. Questo proteggerà i dati da intercettazioni e manomissioni.
Monitoraggio
È cruciale monitorare la salute e le prestazioni dell’applicazione Confluent Sigma in un ambiente di produzione. Dovresti monitorare le metriche seguenti:
- Il numero di messaggi elaborati
- Il numero di avvisi generati
- La latenza dell’applicazione
- L’uso della CPU e della memoria dell’applicazione
Metriche Chiave
Oltre alle metriche precedentemente menzionate, dovresti anche monitorare le seguenti:
- Latenza End-to-End: Questo è il tempo impiegato da un messaggio per viaggiare dal produttore al consumatore. Una latenza end-to-end alta può indicare un problema con la rete o il cluster Kafka.
- Ritardo del Consumatore: Questo è il numero di messaggi in un topic che non sono ancora stati elaborati dal consumatore. Un alto ritardo del consumatore può indicare che l’applicazione non è in grado di tenere il passo con il tasso di dati in arrivo.
Casi d’Uso di Confluent Sigma
Confluent Sigma consente ai team di sicurezza di rilevare minacce in tempo reale applicando regole Sigma direttamente ai flussi di Kafka, consentendo agli ingegneri di rilevamento di rispondere ad anomalie prima che i dati raggiungano il SIEM e ottimizzare il perfezionamento delle regole.
I principali casi d’uso includono i seguenti:
- Rilevamento delle Minacce Shift-Left: Applicare la logica di rilevamento alla fonte, prima che i log raggiungano il SIEM, consentendo una risposta più rapida agli attacchi in corso.
- Impostare una Pipeline CI/CD per i Rilevamenti: Automatizzare il deployment e l’aggiornamento delle regole tra gli ambienti migliorando l’efficienza operativa e la coerenza.
- Versionare le Regole tra Ambienti: Mantenere la strutturazione delle versioni delle regole utilizzando topic Kafka o Git, garantendo tracciabilità e più facili rollback.
- Ridurre i Costi di Ingestione dei Log: Rilevare minacce in volo senza ingerire ogni log nel SIEM, riducendo i costi di archiviazione e elaborazione.
- Rimuovere la Latenza di Query del SIEM: Accedere a rilevamenti ad alta fedeltà istantaneamente elaborando le regole in flussi in tempo reale.
- Incrementare la Velocità di Correlazione: Applicare logica di aggregazione e finestre scorrevoli all’interno di Kafka Streams per correlare rapidamente gli eventi e generare avvisi.
Confluent Sigma Alimentato dalla Tecnologia SOC Prime
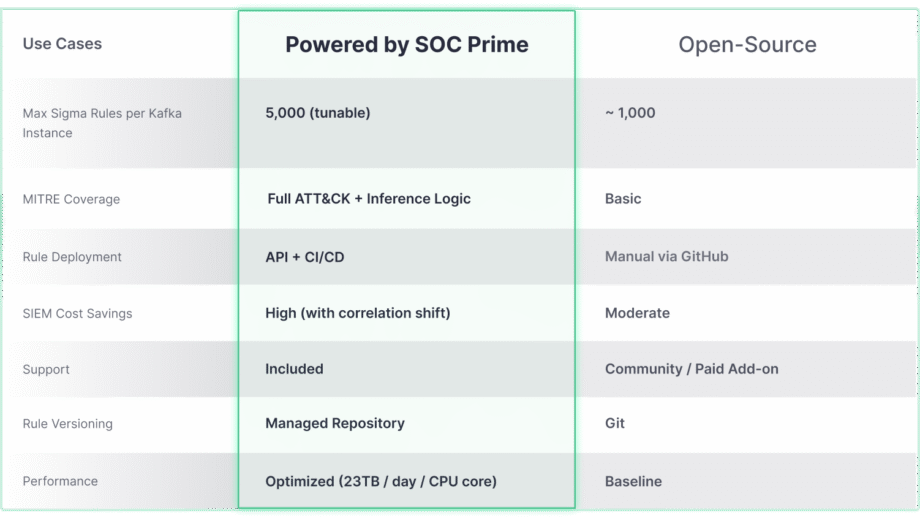
Mentre il progetto open-source Confluent Sigma fornisce una solida base per il rilevamento Shift-Left, il suo vero potenziale per la scalabilità e la copertura avanzata delle minacce si sblocca quando integrato con soluzioni a livello aziendale come SOC Prime. Il confronto sottostante evidenzia come le capacità principali si evolvano per soddisfare le esigenze di ambienti su larga scala e complessi.
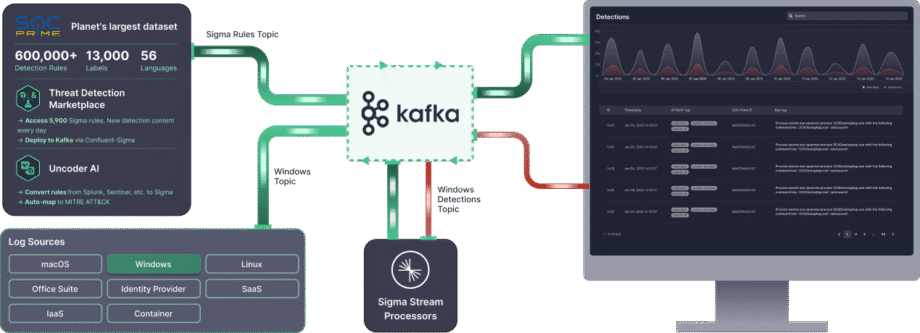
La soluzione Confluent Sigma & SOC Prime fornisce un accesso diretto a strumenti e contenuti che accelerano drasticamente il ciclo di vita del rilevamento:
- Threat Detection Marketplace: Sfruttando il Threat Detection Marketplace, i team di sicurezza possono scegliere tra oltre 15.000 regole Sigma che affrontano minacce emergenti e trasmetterle direttamente all’ambiente Kafka in modo automatizzato.
- Uncoder AI: Con Uncoder AI di SOC Prime, un IDE e co-pilota per l’ingegneria di rilevamento end-to-end, i difensori possono convertire il codice di rilevamento da più formati di linguaggio a Sigma, mappandolo automaticamente a MITRE ATT&CK, scrivere codice da zero con l’IA o modificarlo al volo per garantire un rilevamento delle minacce snello..
- Eccellenza Operativa: Il deployment automatizzato tramite API e CI/CD assicura un rollout delle regole coerente e ripetibile, mentre le prestazioni ad alta capacità (fino a 23 TB/giorno per core CPU) abilitano il rilevamento delle minacce in tempo reale e scalabile in qualsiasi ambiente.
- Supporto Esperto: Affidati alla massima competenza ingegneristica di SOC Prime per ricevere supporto guidato nell’installazione, gestione e scalabilità dello stack di rilevamento open-source.